 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Programming by Example with a Natural Language Prior
May 25, 2022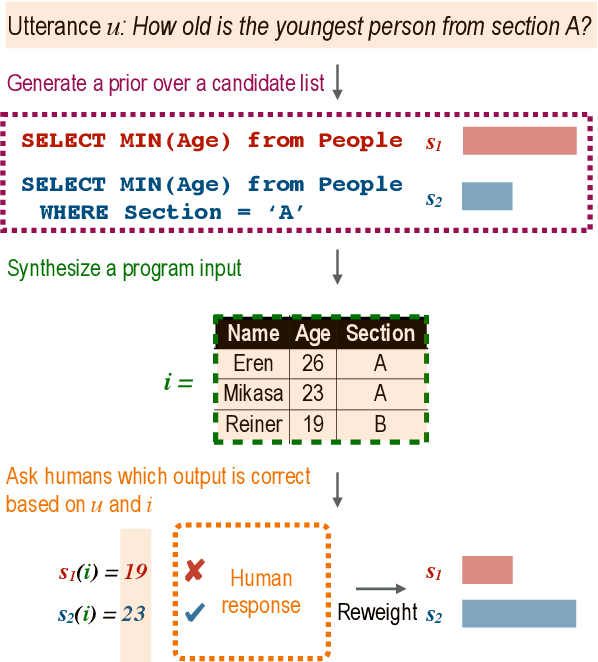
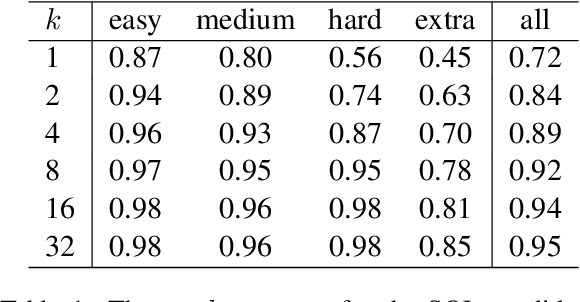

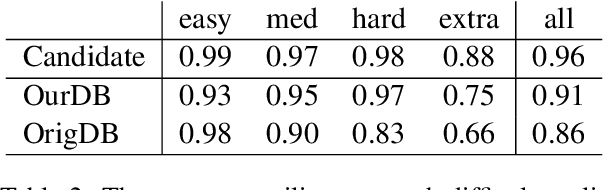
We introduce APEL, a new framework that enables non-programmers to indirectly annotate natural language utterances with executable meaning representations, such as SQL programs. Based on a natural language utterance, we first run a seed semantic parser to generate a prior over a list of candidate programs. To obtain information about which candidate is correct, we synthesize an input on which the more likely programs tend to produce different outputs, and ask an annotator which output is appropriate for the utterance. Hence, the annotator does not have to directly inspect the programs. To further reduce effort required from annotators, we aim to synthesize simple input databases that nonetheless have high information gain. With human annotators and Bayesian inference to handle annotation errors, we outperform Codex's top-1 performance (59%) and achieve the same accuracy as the original expert annotators (75%), by soliciting answers for each utterance on only 2 databases with an average of 9 records each. In contrast, it would be impractical to solicit outputs on the original 30K-record databases provided by SPIDER
InCoder: A Generative Model for Code Infilling and Synthesis
Apr 17, 2022

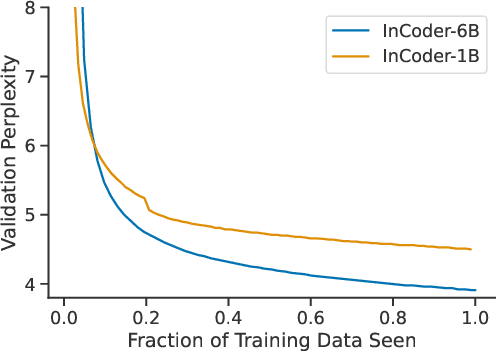
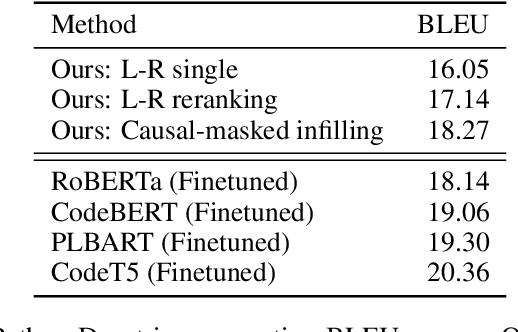
Code is seldom written in a single left-to-right pass and is instead repeatedly edited and refined. We introduce InCoder, a unified generative model that can perform program synthesis (via left-to-right generation) as well as editing (via infilling). InCoder is trained to generate code files from a large corpus of permissively licensed code, where regions of code have been randomly masked and moved to the end of each file, allowing code infilling with bidirectional context. Our model is the first generative model that is able to directly perform zero-shot code infilling, which we evaluate on challenging tasks such as type inference, comment generation, and variable re-naming. We find that the ability to condition on bidirectional context substantially improves performance on these tasks, while still performing comparably on standard program synthesis benchmarks in comparison to left-to-right only models pretrained at similar scale. The InCoder models and code are publicly released. https://sites.google.com/view/incoder-code-models
Summarizing Differences between Text Distributions with Natural Language
Jan 28, 2022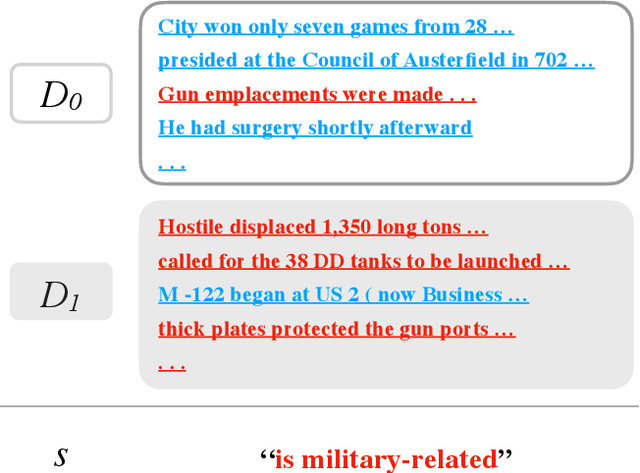


How do two distributions of texts differ? Humans are slow at answering this, since discovering patterns might require tediously reading through hundreds of samples. We propose to automatically summarize the differences by "learning a natural language hypothesis": given two distributions $D_{0}$ and $D_{1}$, we search for a description that is more often true for $D_{1}$, e.g., "is military-related." To tackle this problem, we fine-tune GPT-3 to propose descriptions with the prompt: "[samples of $D_{0}$] + [samples of $D_{1}$] + the difference between them is _____". We then re-rank the descriptions by checking how often they hold on a larger set of samples with a learned verifier. On a benchmark of 54 real-world binary classification tasks, while GPT-3 Curie (13B) only generates a description similar to human annotation 7% of the time, the performance reaches 61% with fine-tuning and re-ranking, and our best system using GPT-3 Davinci (175B) reaches 76%. We apply our system to describe distribution shifts, debug dataset shortcuts, summarize unknown tasks, and label text clusters, and present analyses based on automatically generated descriptions.
UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models
Jan 20, 2022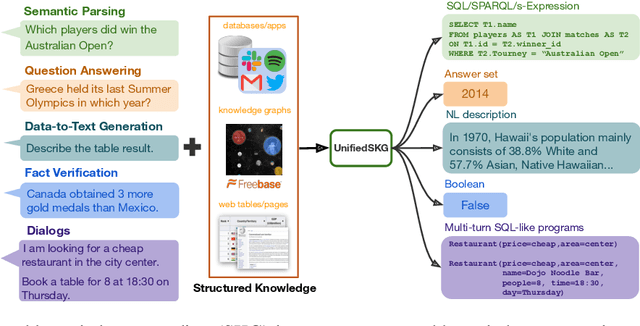
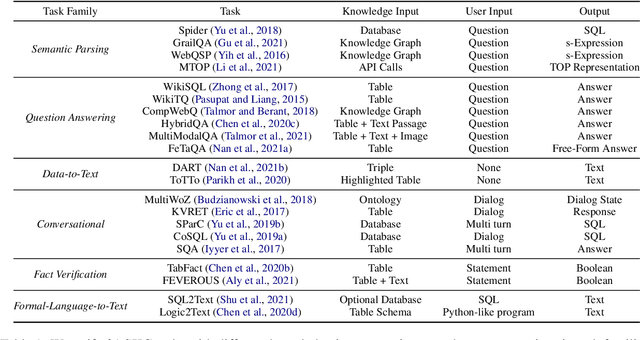
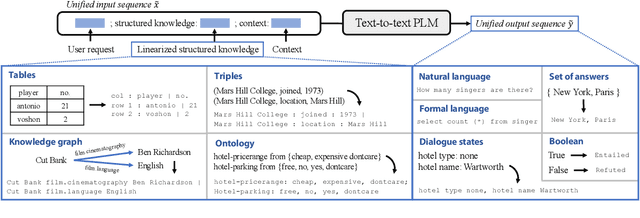
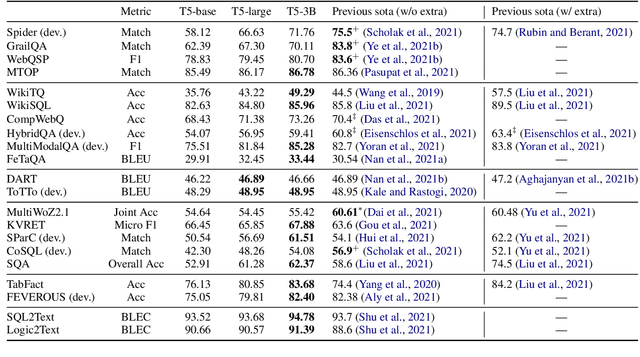
Structured knowledge grounding (SKG) leverages structured knowledge to complete user requests, such as semantic parsing over databases and question answering over knowledge bases. Since the inputs and outputs of SKG tasks are heterogeneous, they have been studied separately by different communities, which limits systematic and compatible research on SKG. In this paper, we overcome this limitation by proposing the SKG framework, which unifies 21 SKG tasks into a text-to-text format, aiming to promote systematic SKG research, instead of being exclusive to a single task, domain, or dataset. We use UnifiedSKG to benchmark T5 with different sizes and show that T5, with simple modifications when necessary, achieves state-of-the-art performance on almost all of the 21 tasks. We further demonstrate that multi-task prefix-tuning improves the performance on most tasks, largely improving the overall performance. UnifiedSKG also facilitates the investigation of zero-shot and few-shot learning, and we show that T0, GPT-3, and Codex struggle in zero-shot and few-shot learning for SKG. We also use UnifiedSKG to conduct a series of controlled experiments on structured knowledge encoding variants across SKG tasks. UnifiedSKG is easily extensible to more tasks, and it is open-sourced at https://github.com/hkunlp/unifiedskg Latest collections at https://unifiedskg.com.
The Effect of Model Size on Worst-Group Generalization
Dec 08, 2021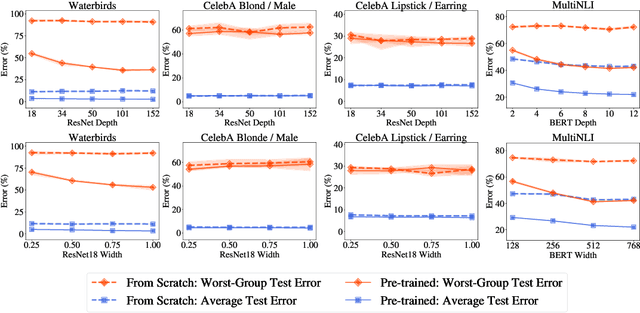
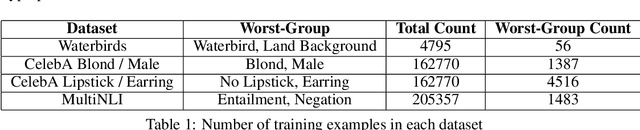
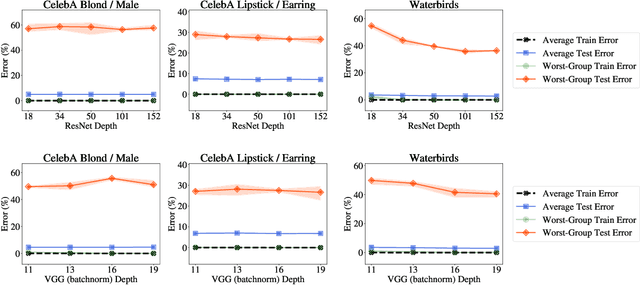
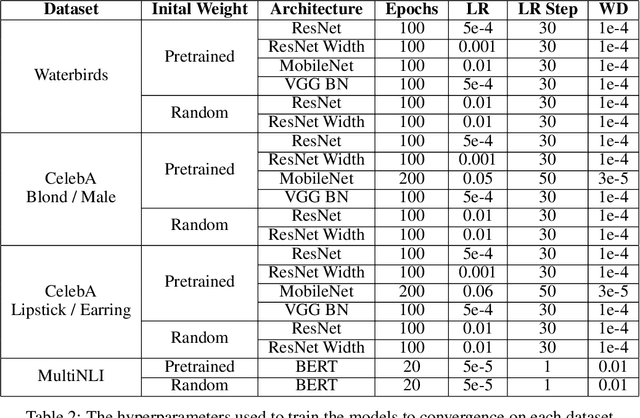
Overparameterization is shown to result in poor test accuracy on rare subgroups under a variety of settings where subgroup information is known. To gain a more complete picture, we consider the case where subgroup information is unknown. We investigate the effect of model size on worst-group generalization under empirical risk minimization (ERM) across a wide range of settings, varying: 1) architectures (ResNet, VGG, or BERT), 2) domains (vision or natural language processing), 3) model size (width or depth), and 4) initialization (with pre-trained or random weights). Our systematic evaluation reveals that increasing model size does not hurt, and may help, worst-group test performance under ERM across all setups. In particular, increasing pre-trained model size consistently improves performance on Waterbirds and MultiNLI. We advise practitioners to use larger pre-trained models when subgroup labels are unknown.
Meta-learning via Language Model In-context Tuning
Oct 15, 2021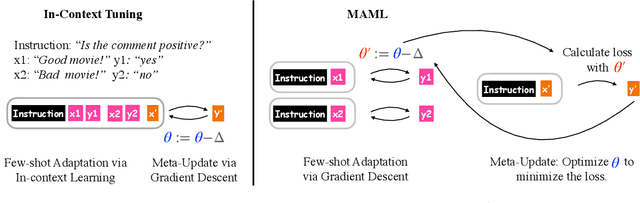
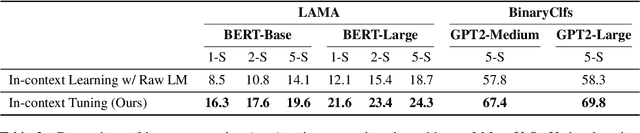
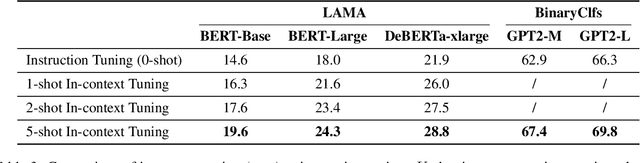
The goal of meta-learning is to learn to adapt to a new task with only a few labeled examples. To tackle this problem in NLP, we propose $\textit{in-context tuning}$, which recasts adaptation and prediction as a simple sequence prediction problem: to form the input sequence, we concatenate the task instruction, the labeled examples, and the target input to predict; to meta-train the model to learn from in-context examples, we fine-tune a pre-trained language model (LM) to predict the target label from the input sequences on a collection of tasks. We benchmark our method on two collections of text classification tasks: LAMA and BinaryClfs. Compared to first-order MAML which adapts the model with gradient descent, our method better leverages the inductive bias of LMs to perform pattern matching, and outperforms MAML by an absolute $6\%$ AUC ROC score on BinaryClfs, with increasing advantage w.r.t. model size. Compared to non-fine-tuned in-context learning (i.e. prompting a raw LM), in-context tuning directly learns to learn from in-context examples. On BinaryClfs, in-context tuning improves the average AUC-ROC score by an absolute $10\%$, and reduces the variance with respect to example ordering by 6x and example choices by 2x.
Are Larger Pretrained Language Models Uniformly Better? Comparing Performance at the Instance Level
May 13, 2021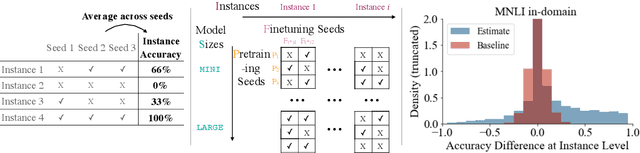
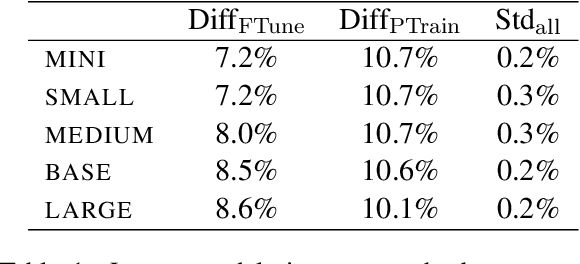
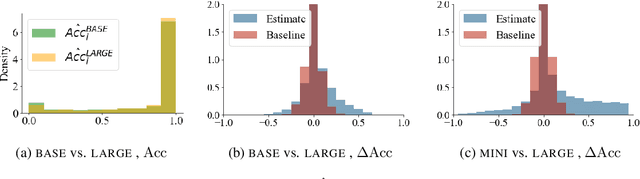
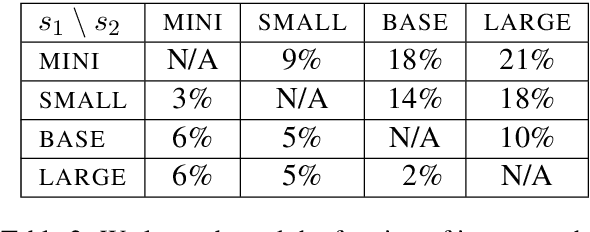
Larger language models have higher accuracy on average, but are they better on every single instance (datapoint)? Some work suggests larger models have higher out-of-distribution robustness, while other work suggests they have lower accuracy on rare subgroups. To understand these differences, we investigate these models at the level of individual instances. However, one major challenge is that individual predictions are highly sensitive to noise in the randomness in training. We develop statistically rigorous methods to address this, and after accounting for pretraining and finetuning noise, we find that our BERT-Large is worse than BERT-Mini on at least 1-4% of instances across MNLI, SST-2, and QQP, compared to the overall accuracy improvement of 2-10%. We also find that finetuning noise increases with model size and that instance-level accuracy has momentum: improvement from BERT-Mini to BERT-Medium correlates with improvement from BERT-Medium to BERT-Large. Our findings suggest that instance-level predictions provide a rich source of information; we therefore, recommend that researchers supplement model weights with model predictions.
Meta-tuning Language Models to Answer Prompts Better
Apr 17, 2021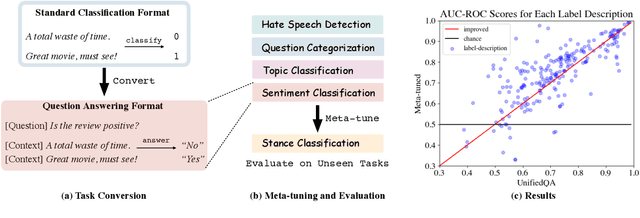
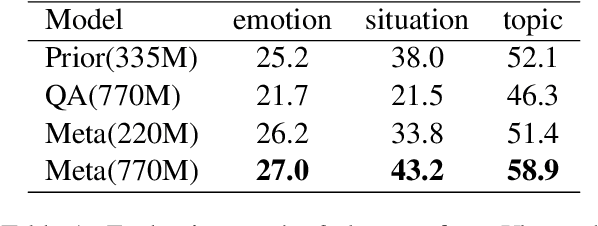

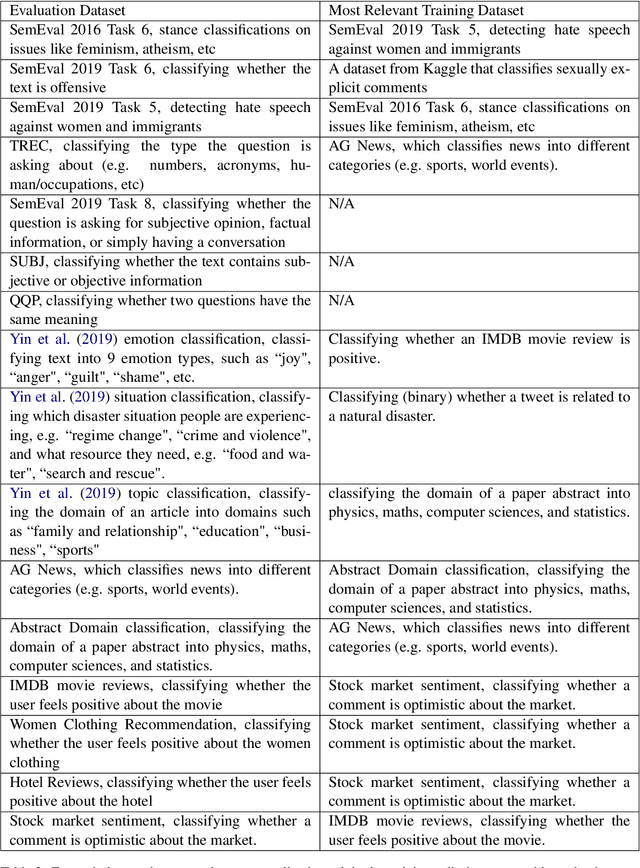
Large pretrained language models like GPT-3 have acquired a surprising ability to perform zero-shot classification (ZSC). For example, to classify review sentiments, we can "prompt" the language model with the review and the question "Is the review positive?" as the context, and ask it to predict whether the next word is "Yes" or "No". However, these models are not specialized for answering these prompts. To address this weakness, we propose meta-tuning, which trains the model to specialize in answering prompts but still generalize to unseen tasks. To create the training data, we aggregated 43 existing datasets, annotated 441 label descriptions in total, and unified them into the above question answering (QA) format. After meta-tuning, our model outperforms a same-sized QA model for most labels on unseen tasks, and we forecast that the performance would improve for even larger models. Therefore, measuring ZSC performance on non-specialized language models might underestimate their true capability, and community-wide efforts on aggregating datasets and unifying their formats can help build models that understand prompts better.
Approximating How Single Head Attention Learns
Mar 13, 2021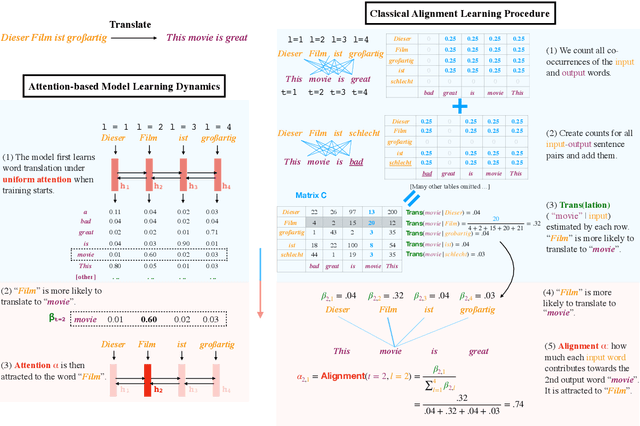

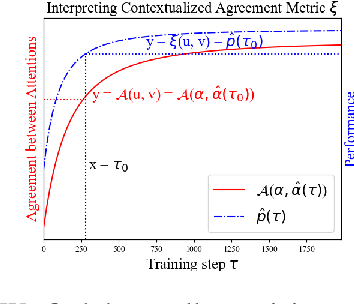
Why do models often attend to salient words, and how does this evolve throughout training? We approximate model training as a two stage process: early on in training when the attention weights are uniform, the model learns to translate individual input word `i` to `o` if they co-occur frequently. Later, the model learns to attend to `i` while the correct output is $o$ because it knows `i` translates to `o`. To formalize, we define a model property, Knowledge to Translate Individual Words (KTIW) (e.g. knowing that `i` translates to `o`), and claim that it drives the learning of the attention. This claim is supported by the fact that before the attention mechanism is learned, KTIW can be learned from word co-occurrence statistics, but not the other way around. Particularly, we can construct a training distribution that makes KTIW hard to learn, the learning of the attention fails, and the model cannot even learn the simple task of copying the input words to the output. Our approximation explains why models sometimes attend to salient words, and inspires a toy example where a multi-head attention model can overcome the above hard training distribution by improving learning dynamics rather than expressiveness.
Semantic Evaluation for Text-to-SQL with Distilled Test Suites
Oct 06, 2020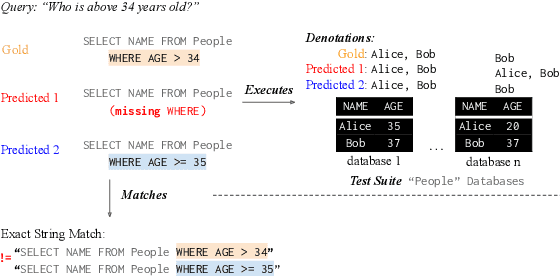
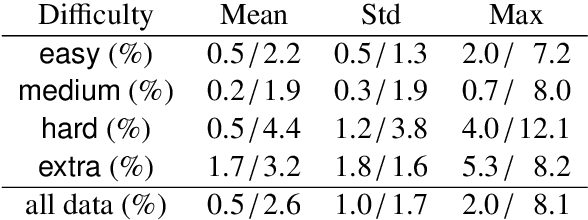

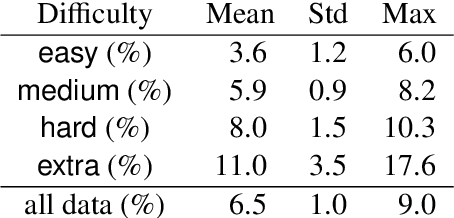
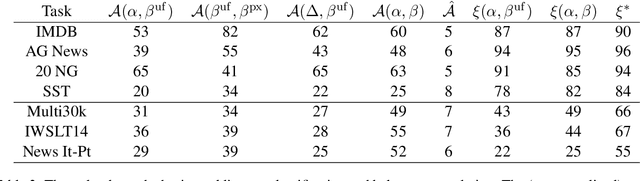
We propose test suite accuracy to approximate semantic accuracy for Text-to-SQL models. Our method distills a small test suite of databases that achieves high code coverage for the gold query from a large number of randomly generated databases. At evaluation time, it computes the denotation accuracy of the predicted queries on the distilled test suite, hence calculating a tight upper-bound for semantic accuracy efficiently. We use our proposed method to evaluate 21 models submitted to the Spider leader board and manually verify that our method is always correct on 100 examples. In contrast, the current Spider metric leads to a 2.5% false negative rate on average and 8.1% in the worst case, indicating that test suite accuracy is needed. Our implementation, along with distilled test suites for eleven Text-to-SQL datasets, is publicly available.