 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGumbelSoft: Diversified Language Model Watermarking via the GumbelMax-trick
Feb 25, 2024Large language models (LLMs) excellently generate human-like text, but also raise concerns about misuse in fake news and academic dishonesty. Decoding-based watermark, particularly the GumbelMax-trick-based watermark(GM watermark), is a standout solution for safeguarding machine-generated texts due to its notable detectability. However, GM watermark encounters a major challenge with generation diversity, always yielding identical outputs for the same prompt, negatively impacting generation diversity and user experience. To overcome this limitation, we propose a new type of GM watermark, the Logits-Addition watermark, and its three variants, specifically designed to enhance diversity. Among these, the GumbelSoft watermark (a softmax variant of the Logits-Addition watermark) demonstrates superior performance in high diversity settings, with its AUROC score outperforming those of the two alternative variants by 0.1 to 0.3 and surpassing other decoding-based watermarking methods by a minimum of 0.1.
Probabilistic Precipitation Downscaling with Optical Flow-Guided Diffusion
Dec 11, 2023In climate science and meteorology, local precipitation predictions are limited by the immense computational costs induced by the high spatial resolution that simulation methods require. A common workaround is statistical downscaling (aka superresolution), where a low-resolution prediction is super-resolved using statistical approaches. While traditional computer vision tasks mainly focus on human perception or mean squared error, applications in weather and climate require capturing the conditional distribution of high-resolution patterns given low-resolution patterns so that reliable ensemble averages can be taken. Our approach relies on extending recent video diffusion models to precipitation superresolution: an optical flow on the high-resolution output induces temporally coherent predictions, whereas a temporally-conditioned diffusion model generates residuals that capture the correct noise characteristics and high-frequency patterns. We test our approach on X-SHiELD, an established large-scale climate simulation dataset, and compare against two state-of-the-art baselines, focusing on CRPS, MSE, precipitation distributions, as well as an illustrative case -- the complex terrain of California. Our approach sets a new standard for data-driven precipitation downscaling.
Harmonic Mobile Manipulation
Dec 11, 2023



Recent advancements in robotics have enabled robots to navigate complex scenes or manipulate diverse objects independently. However, robots are still impotent in many household tasks requiring coordinated behaviors such as opening doors. The factorization of navigation and manipulation, while effective for some tasks, fails in scenarios requiring coordinated actions. To address this challenge, we introduce, HarmonicMM, an end-to-end learning method that optimizes both navigation and manipulation, showing notable improvement over existing techniques in everyday tasks. This approach is validated in simulated and real-world environments and adapts to novel unseen settings without additional tuning. Our contributions include a new benchmark for mobile manipulation and the successful deployment in a real unseen apartment, demonstrating the potential for practical indoor robot deployment in daily life. More results are on our project site: https://rchalyang.github.io/HarmonicMM/
CMMD: Contrastive Multi-Modal Diffusion for Video-Audio Conditional Modeling
Dec 08, 2023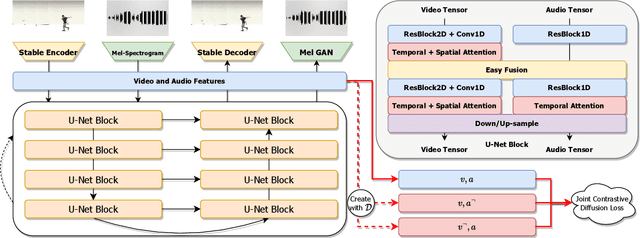
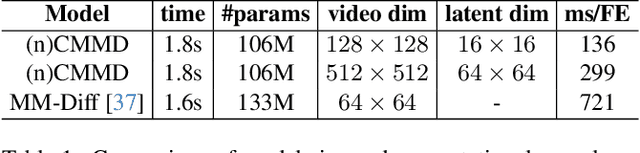
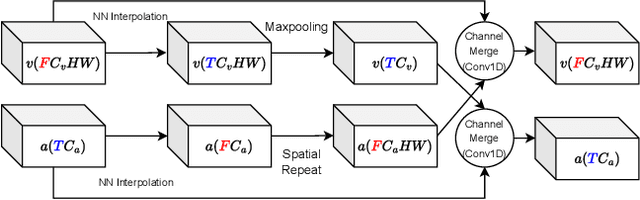
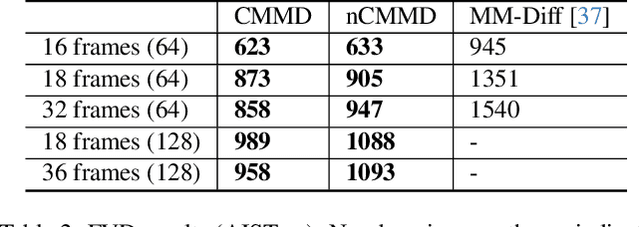
We introduce a multi-modal diffusion model tailored for the bi-directional conditional generation of video and audio. Recognizing the importance of accurate alignment between video and audio events in multi-modal generation tasks, we propose a joint contrastive training loss to enhance the synchronization between visual and auditory occurrences. Our research methodology involves conducting comprehensive experiments on multiple datasets to thoroughly evaluate the efficacy of our proposed model. The assessment of generation quality and alignment performance is carried out from various angles, encompassing both objective and subjective metrics. Our findings demonstrate that the proposed model outperforms the baseline, substantiating its effectiveness and efficiency. Notably, the incorporation of the contrastive loss results in improvements in audio-visual alignment, particularly in the high-correlation video-to-audio generation task. These results indicate the potential of our proposed model as a robust solution for improving the quality and alignment of multi-modal generation, thereby contributing to the advancement of video and audio conditional generation systems.
Generalized Animal Imitator: Agile Locomotion with Versatile Motion Prior
Oct 02, 2023The agility of animals, particularly in complex activities such as running, turning, jumping, and backflipping, stands as an exemplar for robotic system design. Transferring this suite of behaviors to legged robotic systems introduces essential inquiries: How can a robot be trained to learn multiple locomotion behaviors simultaneously? How can the robot execute these tasks with a smooth transition? And what strategies allow for the integrated application of these skills? This paper introduces the Versatile Instructable Motion prior (VIM) - a Reinforcement Learning framework designed to incorporate a range of agile locomotion tasks suitable for advanced robotic applications. Our framework enables legged robots to learn diverse agile low-level skills by imitating animal motions and manually designed motions with Functionality reward and Stylization reward. While the Functionality reward guides the robot's ability to adopt varied skills, the Stylization reward ensures performance alignment with reference motions. Our evaluations of the VIM framework span both simulation environments and real-world deployment. To our understanding, this is the first work that allows a robot to concurrently learn diverse agile locomotion tasks using a singular controller. Further details and supportive media can be found at our project site: https://rchalyang.github.io/VIM .
Neural Volumetric Memory for Visual Locomotion Control
Apr 03, 2023Legged robots have the potential to expand the reach of autonomy beyond paved roads. In this work, we consider the difficult problem of locomotion on challenging terrains using a single forward-facing depth camera. Due to the partial observability of the problem, the robot has to rely on past observations to infer the terrain currently beneath it. To solve this problem, we follow the paradigm in computer vision that explicitly models the 3D geometry of the scene and propose Neural Volumetric Memory (NVM), a geometric memory architecture that explicitly accounts for the SE(3) equivariance of the 3D world. NVM aggregates feature volumes from multiple camera views by first bringing them back to the ego-centric frame of the robot. We test the learned visual-locomotion policy on a physical robot and show that our approach, which explicitly introduces geometric priors during training, offers superior performance than more na\"ive methods. We also include ablation studies and show that the representations stored in the neural volumetric memory capture sufficient geometric information to reconstruct the scene. Our project page with videos is https://rchalyang.github.io/NVM .
Lossy Image Compression with Conditional Diffusion Models
Sep 14, 2022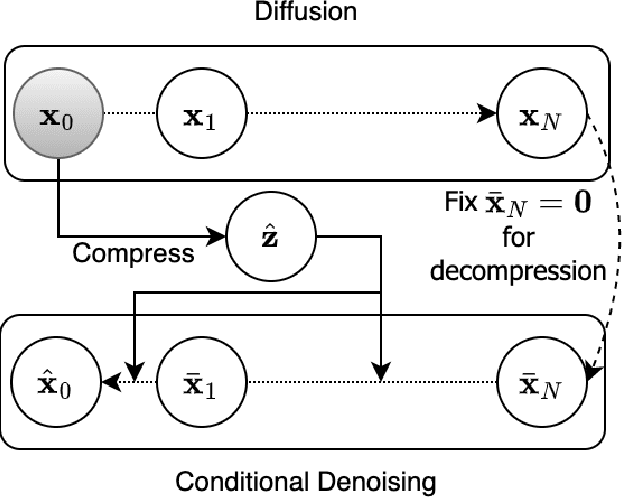

Diffusion models are a new class of generative models that mark a milestone in high-quality image generation while relying on solid probabilistic principles. This makes them promising candidate models for neural image compression. This paper outlines an end-to-end optimized framework based on a conditional diffusion model for image compression. Besides latent variables inherent to the diffusion process, the model introduces an additional per-instance "content" latent variable to condition the denoising process. Upon decoding, the diffusion process conditionally generates/reconstructs an image using ancestral sampling. Our experiments show that this approach outperforms one of the best-performing conventional image codecs (BPG) and one neural codec on two compression benchmarks, where we focus on rate-perception tradeoffs. Qualitatively, our approach shows fewer decompression artifacts than the classical approach.
Diffusion Probabilistic Modeling for Video Generation
Mar 31, 2022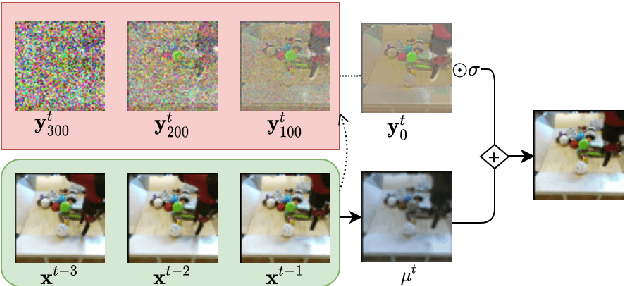
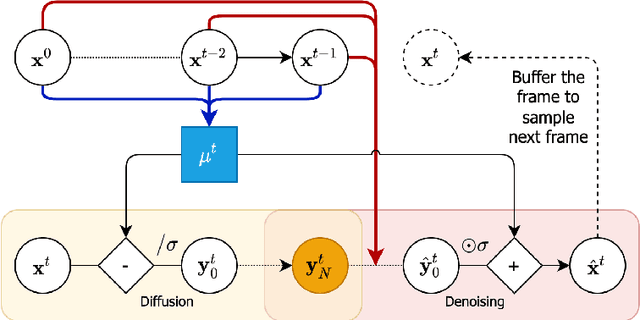

Denoising diffusion probabilistic models are a promising new class of generative models that are competitive with GANs on perceptual metrics. In this paper, we explore their potential for sequentially generating video. Inspired by recent advances in neural video compression, we use denoising diffusion models to stochastically generate a residual to a deterministic next-frame prediction. We compare this approach to two sequential VAE and two GAN baselines on four datasets, where we test the generated frames for perceptual quality and forecasting accuracy against ground truth frames. We find significant improvements in terms of perceptual quality on all data and improvements in terms of frame forecasting for complex high-resolution videos.
SC2: Supervised Compression for Split Computing
Mar 16, 2022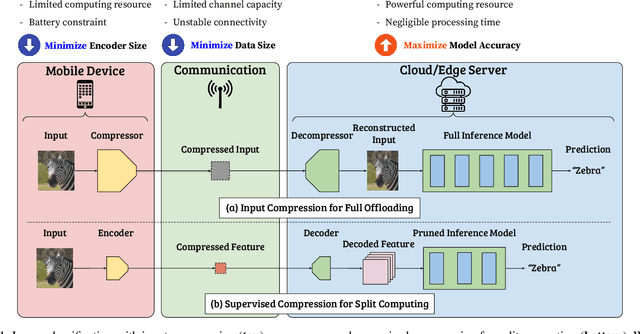
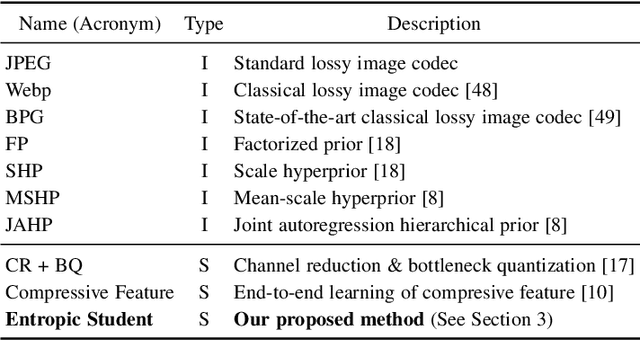
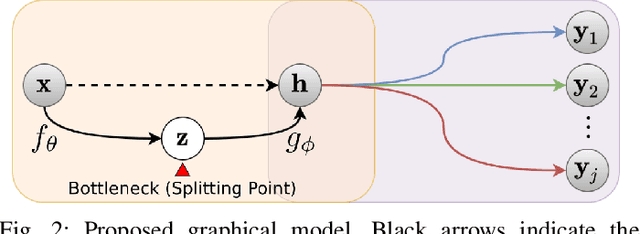
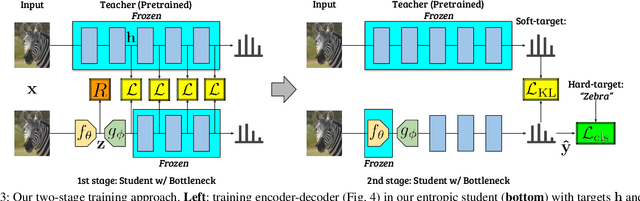
Split computing distributes the execution of a neural network (e.g., for a classification task) between a mobile device and a more powerful edge server. A simple alternative to splitting the network is to carry out the supervised task purely on the edge server while compressing and transmitting the full data, and most approaches have barely outperformed this baseline. This paper proposes a new approach for discretizing and entropy-coding intermediate feature activations to efficiently transmit them from the mobile device to the edge server. We show that a efficient splittable network architecture results from a three-way tradeoff between (a) minimizing the computation on the mobile device, (b) minimizing the size of the data to be transmitted, and (c) maximizing the model's prediction performance. We propose an architecture based on this tradeoff and train the splittable network and entropy model in a knowledge distillation framework. In an extensive set of experiments involving three vision tasks, three datasets, nine baselines, and more than 180 trained models, we show that our approach improves supervised rate-distortion tradeoffs while maintaining a considerably smaller encoder size. We also release sc2bench, an installable Python package, to encourage and facilitate future studies on supervised compression for split computing (SC2).
Vision-Guided Quadrupedal Locomotion in the Wild with Multi-Modal Delay Randomization
Sep 29, 2021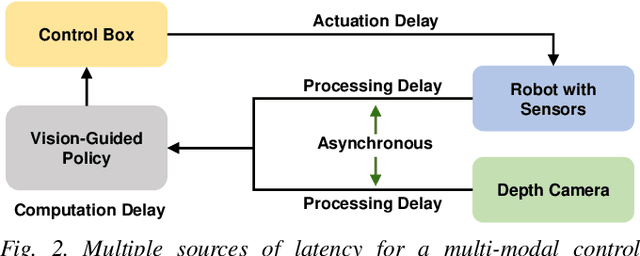
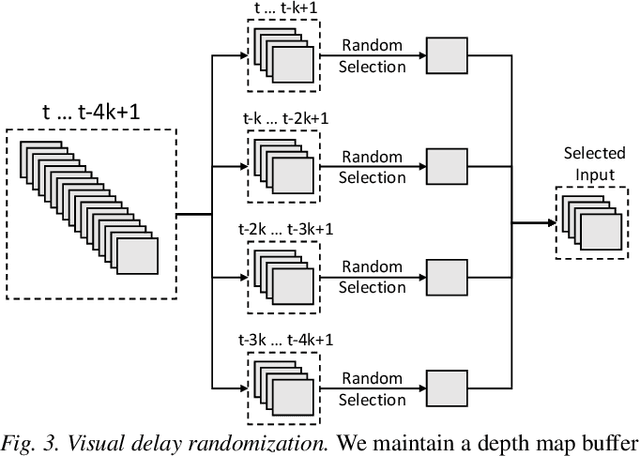

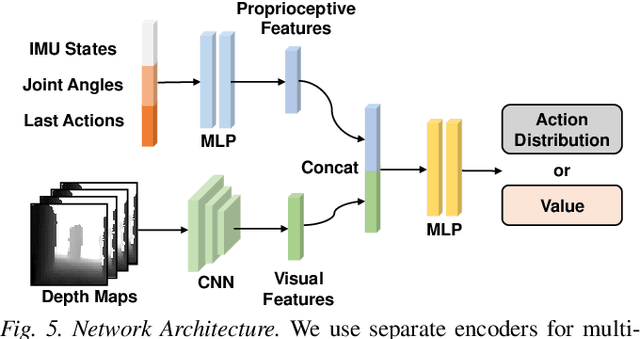
Developing robust vision-guided controllers for quadrupedal robots in complex environments, with various obstacles, dynamical surroundings and uneven terrains, is very challenging. While Reinforcement Learning (RL) provides a promising paradigm for agile locomotion skills with vision inputs in simulation, it is still very challenging to deploy the RL policy in the real world. Our key insight is that aside from the discrepancy in the domain gap, in visual appearance between the simulation and the real world, the latency from the control pipeline is also a major cause of difficulty. In this paper, we propose Multi-Modal Delay Randomization (MMDR) to address this issue when training RL agents. Specifically, we simulate the latency of real hardware by using past observations, sampled with randomized periods, for both proprioception and vision. We train the RL policy for end-to-end control in a physical simulator without any predefined controller or reference motion, and directly deploy it on the real A1 quadruped robot running in the wild. We evaluate our method in different outdoor environments with complex terrains and obstacles. We demonstrate the robot can smoothly maneuver at a high speed, avoid the obstacles, and show significant improvement over the baselines. Our project page with videos is at https://mehooz.github.io/mmdr-wild/.