 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantile Off-Policy Evaluation via Deep Conditional Generative Learning
Dec 29, 2022



Off-Policy evaluation (OPE) is concerned with evaluating a new target policy using offline data generated by a potentially different behavior policy. It is critical in a number of sequential decision making problems ranging from healthcare to technology industries. Most of the work in existing literature is focused on evaluating the mean outcome of a given policy, and ignores the variability of the outcome. However, in a variety of applications, criteria other than the mean may be more sensible. For example, when the reward distribution is skewed and asymmetric, quantile-based metrics are often preferred for their robustness. In this paper, we propose a doubly-robust inference procedure for quantile OPE in sequential decision making and study its asymptotic properties. In particular, we propose utilizing state-of-the-art deep conditional generative learning methods to handle parameter-dependent nuisance function estimation. We demonstrate the advantages of this proposed estimator through both simulations and a real-world dataset from a short-video platform. In particular, we find that our proposed estimator outperforms classical OPE estimators for the mean in settings with heavy-tailed reward distributions.
An Instrumental Variable Approach to Confounded Off-Policy Evaluation
Dec 29, 2022Off-policy evaluation (OPE) is a method for estimating the return of a target policy using some pre-collected observational data generated by a potentially different behavior policy. In some cases, there may be unmeasured variables that can confound the action-reward or action-next-state relationships, rendering many existing OPE approaches ineffective. This paper develops an instrumental variable (IV)-based method for consistent OPE in confounded Markov decision processes (MDPs). Similar to single-stage decision making, we show that IV enables us to correctly identify the target policy's value in infinite horizon settings as well. Furthermore, we propose an efficient and robust value estimator and illustrate its effectiveness through extensive simulations and analysis of real data from a world-leading short-video platform.
ResFed: Communication Efficient Federated Learning by Transmitting Deep Compressed Residuals
Dec 11, 2022Federated learning enables cooperative training among massively distributed clients by sharing their learned local model parameters. However, with increasing model size, deploying federated learning requires a large communication bandwidth, which limits its deployment in wireless networks. To address this bottleneck, we introduce a residual-based federated learning framework (ResFed), where residuals rather than model parameters are transmitted in communication networks for training. In particular, we integrate two pairs of shared predictors for the model prediction in both server-to-client and client-to-server communication. By employing a common prediction rule, both locally and globally updated models are always fully recoverable in clients and the server. We highlight that the residuals only indicate the quasi-update of a model in a single inter-round, and hence contain more dense information and have a lower entropy than the model, comparing to model weights and gradients. Based on this property, we further conduct lossy compression of the residuals by sparsification and quantization and encode them for efficient communication. The experimental evaluation shows that our ResFed needs remarkably less communication costs and achieves better accuracy by leveraging less sensitive residuals, compared to standard federated learning. For instance, to train a 4.08 MB CNN model on CIFAR-10 with 10 clients under non-independent and identically distributed (Non-IID) setting, our approach achieves a compression ratio over 700X in each communication round with minimum impact on the accuracy. To reach an accuracy of 70%, it saves around 99% of the total communication volume from 587.61 Mb to 6.79 Mb in up-streaming and to 4.61 Mb in down-streaming on average for all clients.
Flying Trot Control Method for Quadruped Robot Based on Trajectory Planning
Oct 24, 2022An intuitive control method for the flying trot, which combines offline trajectory planning with real-time balance control, is presented. The motion features of running animals in the vertical direction were analysed using the spring-load-inverted-pendulum (SLIP) model, and the foot trajectory of the robot was planned, so the robot could run similar to an animal capable of vertical flight, according to the given height and speed of the trunk. To improve the robustness of running, a posture control method based on a foot acceleration adjustment is proposed. A novel kinematic based CoM observation method and CoM regulation method is present to enhance the stability of locomotion. To reduce the impact force when the robot interacts with the environment, the virtual model control method is used in the control of the foot trajectory to achieve active compliance. By selecting the proper parameters for the virtual model, the oscillation motion of the virtual model and the planning motion of the support foot are synchronized to avoid the large disturbance caused by the oscillation motion of the virtual model in relation to the robot motion. The simulation and experiment using the quadruped robot Billy are reported. In the experiment, the maximum speed of the robot could reach 4.73 times the body length per second, which verified the feasibility of the control method.
Federated Learning via Decentralized Dataset Distillation in Resource-Constrained Edge Environments
Aug 31, 2022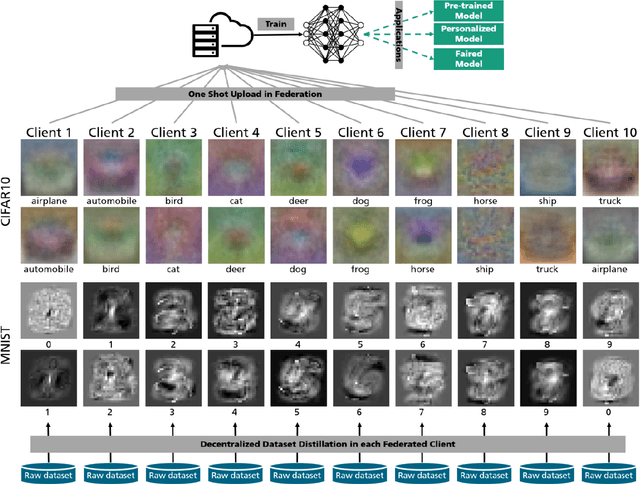
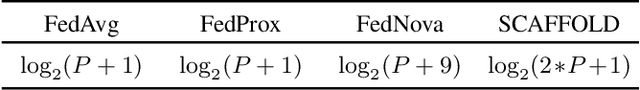
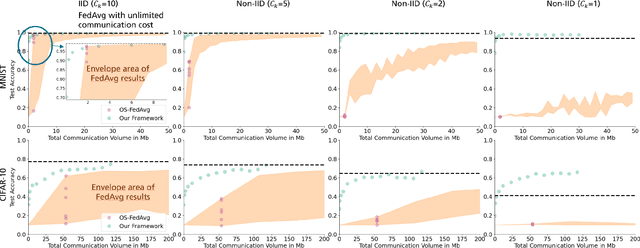
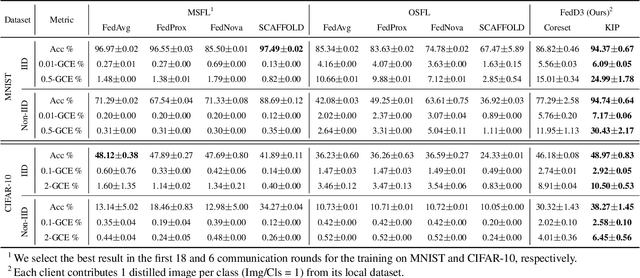
We introduce a novel federated learning framework, FedD3, which reduces the overall communication volume and with that opens up the concept of federated learning to more application scenarios in network-constrained environments. It achieves this by leveraging local dataset distillation instead of traditional learning approaches (i) to significantly reduce communication volumes and (ii) to limit transfers to one-shot communication, rather than iterative multiway communication. Instead of sharing model updates, as in other federated learning approaches, FedD3 allows the connected clients to distill the local datasets independently, and then aggregates those decentralized distilled datasets (typically in the form a few unrecognizable images, which are normally smaller than a model) across the network only once to form the final model. Our experimental results show that FedD3 significantly outperforms other federated learning frameworks in terms of needed communication volumes, while it provides the additional benefit to be able to balance the trade-off between accuracy and communication cost, depending on usage scenario or target dataset. For instance, for training an AlexNet model on a Non-IID CIFAR-10 dataset with 10 clients, FedD3 can either increase the accuracy by over 71% with a similar communication volume, or save 98% of communication volume, while reaching the same accuracy, comparing to other one-shot federated learning approaches.
Edge-Aided Sensor Data Sharing in Vehicular Communication Networks
Jun 17, 2022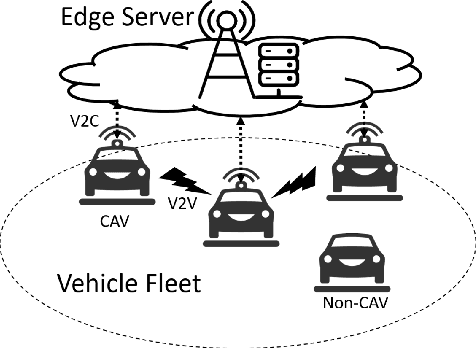
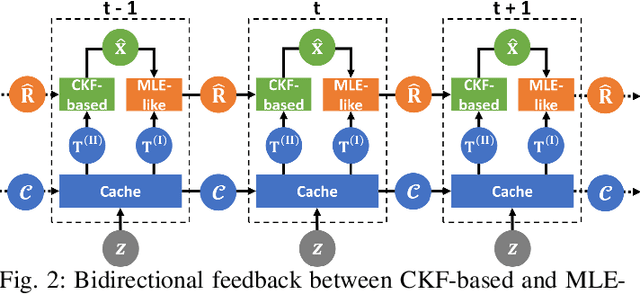
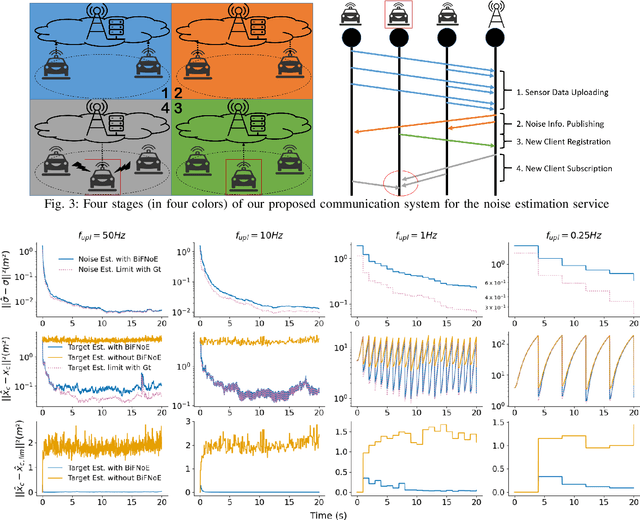
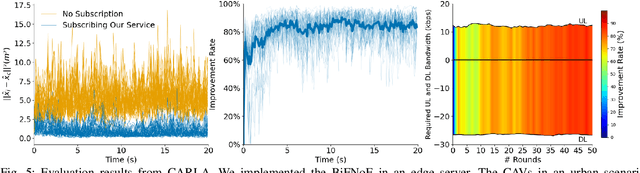
Sensor data sharing in vehicular networks can significantly improve the range and accuracy of environmental perception for connected automated vehicles. Different concepts and schemes for dissemination and fusion of sensor data have been developed. It is common to these schemes that measurement errors of the sensors impair the perception quality and can result in road traffic accidents. Specifically, when the measurement error from the sensors (also referred as measurement noise) is unknown and time varying, the performance of the data fusion process is restricted, which represents a major challenge in the calibration of sensors. In this paper, we consider sensor data sharing and fusion in a vehicular network with both, vehicle-to-infrastructure and vehicle-to-vehicle communication. We propose a method, named Bidirectional Feedback Noise Estimation (BiFNoE), in which an edge server collects and caches sensor measurement data from vehicles. The edge estimates the noise and the targets alternately in double dynamic sliding time windows and enhances the distributed cooperative environment sensing at each vehicle with low communication costs. We evaluate the proposed algorithm and data dissemination strategy in an application scenario by simulation and show that the perception accuracy is on average improved by around 80 % with only 12 kbps uplink and 28 kbps downlink bandwidth.
Locally Aggregated Feature Attribution on Natural Language Model Understanding
Apr 26, 2022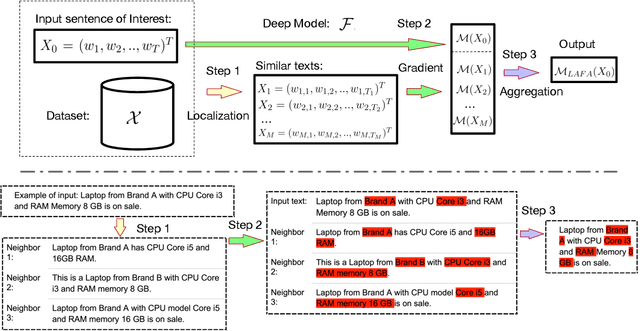
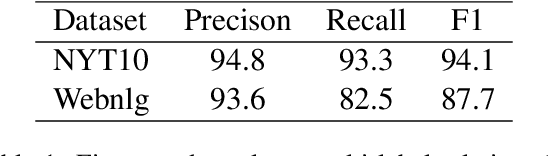
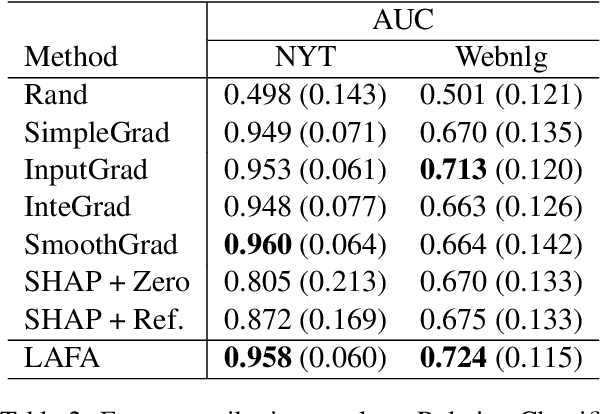
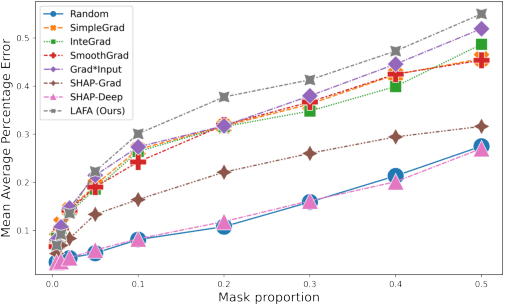
With the growing popularity of deep-learning models, model understanding becomes more important. Much effort has been devoted to demystify deep neural networks for better interpretability. Some feature attribution methods have shown promising results in computer vision, especially the gradient-based methods where effectively smoothing the gradients with reference data is key to a robust and faithful result. However, direct application of these gradient-based methods to NLP tasks is not trivial due to the fact that the input consists of discrete tokens and the "reference" tokens are not explicitly defined. In this work, we propose Locally Aggregated Feature Attribution (LAFA), a novel gradient-based feature attribution method for NLP models. Instead of relying on obscure reference tokens, it smooths gradients by aggregating similar reference texts derived from language model embeddings. For evaluation purpose, we also design experiments on different NLP tasks including Entity Recognition and Sentiment Analysis on public datasets as well as key feature detection on a constructed Amazon catalogue dataset. The superior performance of the proposed method is demonstrated through experiments.
Federated Learning Framework Coping with Hierarchical Heterogeneity in Cooperative ITS
Apr 11, 2022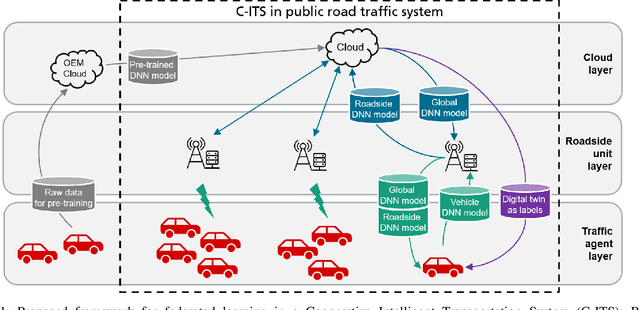
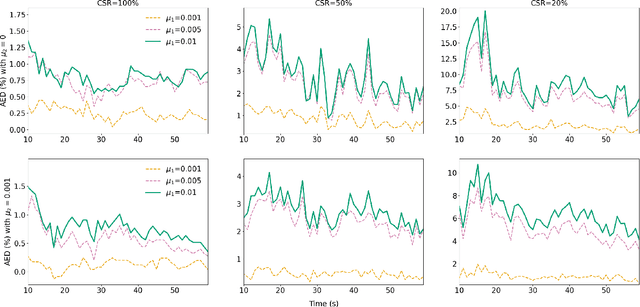
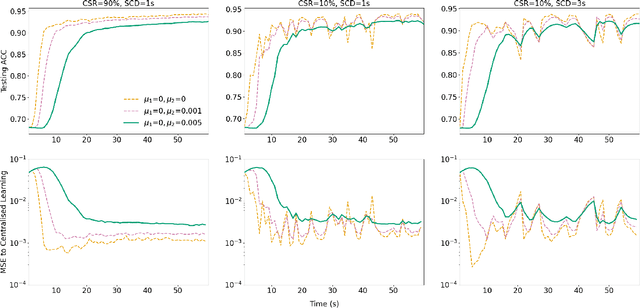
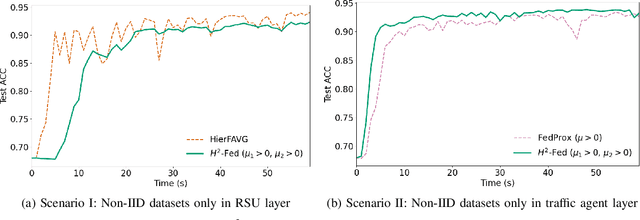
In this paper, we introduce a federated learning framework coping with Hierarchical Heterogeneity (H2-Fed), which can notably enhance the conventional pre-trained deep learning model. The framework exploits data from connected public traffic agents in vehicular networks without affecting user data privacy. By coordinating existing traffic infrastructure, including roadside units and road traffic clouds, the model parameters are efficiently disseminated by vehicular communications and hierarchically aggregated. Considering the individual heterogeneity of data distribution, computational and communication capabilities across traffic agents and roadside units, we employ a novel method that addresses the heterogeneity of different aggregation layers of the framework architecture, i.e., aggregation in layers of roadside units and cloud. The experiment results indicate that our method can well balance the learning accuracy and stability according to the knowledge of heterogeneity in current communication networks. Compared to other baseline approaches, the evaluation on a Non-IID MNIST dataset shows that our framework is more general and capable especially in application scenarios with low communication quality. Even when 90% of the agents are timely disconnected, the pre-trained deep learning model can still be forced to converge stably, and its accuracy can be enhanced from 68% to over 90% after convergence.
Off-Policy Confidence Interval Estimation with Confounded Markov Decision Process
Mar 12, 2022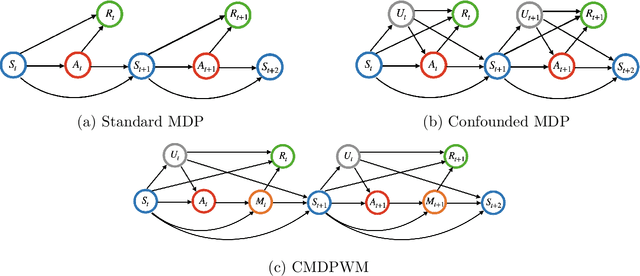

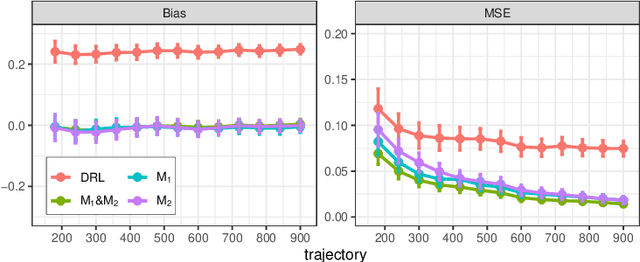
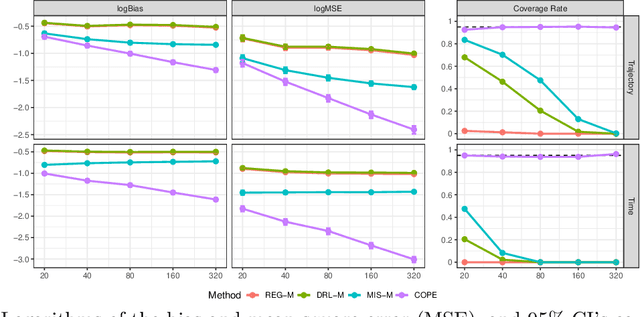
This paper is concerned with constructing a confidence interval for a target policy's value offline based on a pre-collected observational data in infinite horizon settings. Most of the existing works assume no unmeasured variables exist that confound the observed actions. This assumption, however, is likely to be violated in real applications such as healthcare and technological industries. In this paper, we show that with some auxiliary variables that mediate the effect of actions on the system dynamics, the target policy's value is identifiable in a confounded Markov decision process. Based on this result, we develop an efficient off-policy value estimator that is robust to potential model misspecification and provide rigorous uncertainty quantification. Our method is justified by theoretical results, simulated and real datasets obtained from ridesharing companies.
Adaptive Semi-Supervised Inference for Optimal Treatment Decisions with Electronic Medical Record Data
Mar 04, 2022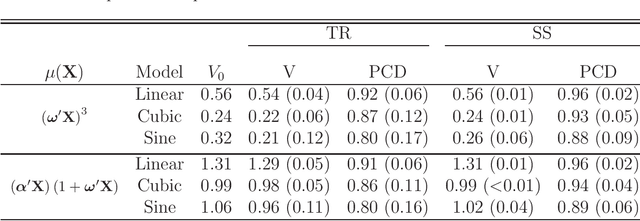
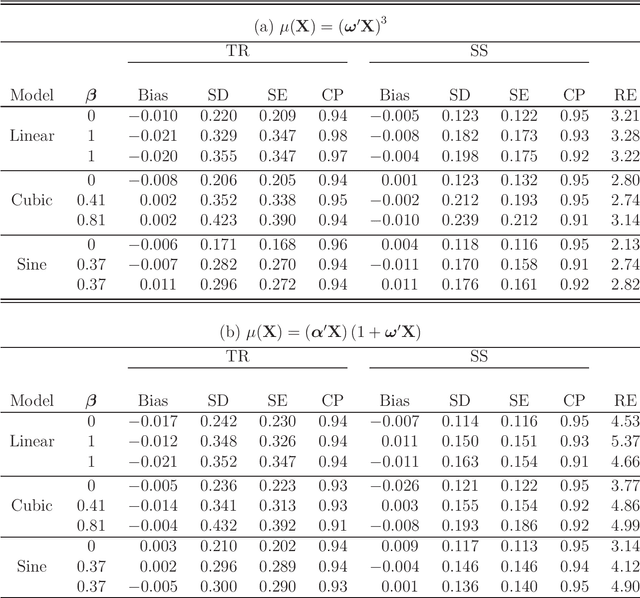
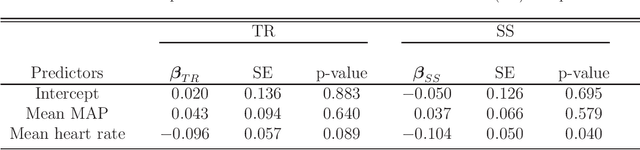

A treatment regime is a rule that assigns a treatment to patients based on their covariate information. Recently, estimation of the optimal treatment regime that yields the greatest overall expected clinical outcome of interest has attracted a lot of attention. In this work, we consider estimation of the optimal treatment regime with electronic medical record data under a semi-supervised setting. Here, data consist of two parts: a set of `labeled' patients for whom we have the covariate, treatment and outcome information, and a much larger set of `unlabeled' patients for whom we only have the covariate information. We proposes an imputation-based semi-supervised method, utilizing `unlabeled' individuals to obtain a more efficient estimator of the optimal treatment regime. The asymptotic properties of the proposed estimators and their associated inference procedure are provided. Simulation studies are conducted to assess the empirical performance of the proposed method and to compare with a fully supervised method using only the labeled data. An application to an electronic medical record data set on the treatment of hypotensive episodes during intensive care unit (ICU) stays is also given for further illustration.