 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Fine-Tuning versus Reinforcement Learning: A Study of Post-Training Methods for Large Language Models
Mar 14, 2026Pre-trained Large Language Model (LLM) exhibits broad capabilities, yet, for specific tasks or domains their attainment of higher accuracy and more reliable reasoning generally depends on post-training through Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL). Although often treated as distinct methodologies, recent theoretical and empirical developments demonstrate that SFT and RL are closely connected. This study presents a comprehensive and unified perspective on LLM post-training with SFT and RL. We first provide an in-depth overview of both techniques, examining their objectives, algorithmic structures, and data requirements. We then systematically analyze their interplay, highlighting frameworks that integrate SFT and RL, hybrid training pipelines, and methods that leverage their complementary strengths. Drawing on a representative set of recent application studies from 2023 to 2025, we identify emerging trends, characterize the rapid shift toward hybrid post-training paradigms, and distill key takeaways that clarify when and why each method is most effective. By synthesizing theoretical insights, practical methodologies, and empirical evidence, this study establishes a coherent understanding of SFT and RL within a unified framework and outlines promising directions for future research in scalable, efficient, and generalizable LLM post-training.
PABU: Progress-Aware Belief Update for Efficient LLM Agents
Feb 09, 2026Large Language Model (LLM) agents commonly condition actions on full action-observation histories, which introduce task-irrelevant information that easily leads to redundant actions and higher inference cost. We propose Progress-Aware Belief Update (PABU), a belief-state framework that compactly represents an agent's state by explicitly modeling task progress and selectively retaining past actions and observations. At each step, the agent predicts its relative progress since the previous round and decides whether the newly encountered interaction should be stored, conditioning future decisions only on the retained subset. Across eight environments in the AgentGym benchmark, and using identical training trajectories, PABU achieves an 81.0% task completion rate, outperforming previous State of the art (SoTA) models with full-history belief by 23.9%. Additionally, PABU's progress-oriented action selection improves efficiency, reducing the average number of interaction steps to 9.5, corresponding to a 26.9% reduction. Ablation studies show that both explicit progress prediction and selective retention are necessary for robust belief learning and performance gains.
IM-GIV: an effective integrity monitoring scheme for tightly-coupled GNSS/INS/Vision integration based on factor graph optimization
Oct 30, 2024Global Navigation Satellite System/Inertial Navigation System (GNSS/INS)/Vision integration based on factor graph optimization (FGO) has recently attracted extensive attention in navigation and robotics community. Integrity monitoring (IM) capability is required when FGO-based integrated navigation system is used for safety-critical applications. However, traditional researches on IM of integrated navigation system are mostly based on Kalman filter. It is urgent to develop effective IM scheme for FGO-based GNSS/INS/Vision integration. In this contribution, the position error bounding formula to ensure the integrity of the GNSS/INS/Vision integration based on FGO is designed and validated for the first time. It can be calculated by the linearized equations from the residuals of GNSS pseudo-range, IMU pre-integration and visual measurements. The specific position error bounding is given in the case of GNSS, INS and visual measurement faults. Field experiments were conducted to evaluate and validate the performance of the proposed position error bounding. Experimental results demonstrate that the proposed position error bounding for the GNSS/INS/Vision integration based on FGO can correctly fit the position error against different fault modes, and the availability of integrity in six fault modes is 100% after correct and timely fault exclusion.
Large Language Model for Causal Decision Making
Dec 29, 2023



Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to inference based on user-specified structured data and knowledge in corpus-rare concepts like causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. With three case studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers. Numerical studies also reveal that it has a remarkable ability to identify the correct causal task given a query.
Locally Aggregated Feature Attribution on Natural Language Model Understanding
Apr 26, 2022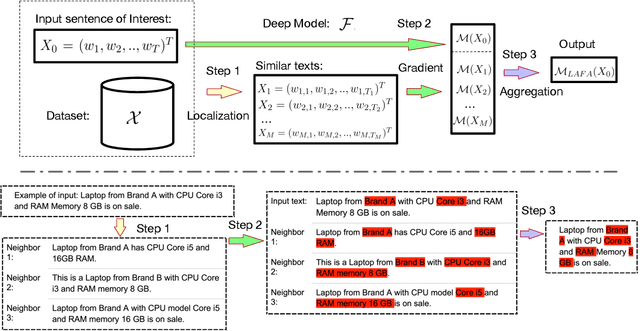
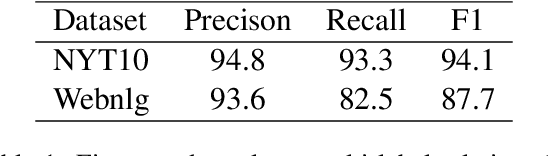
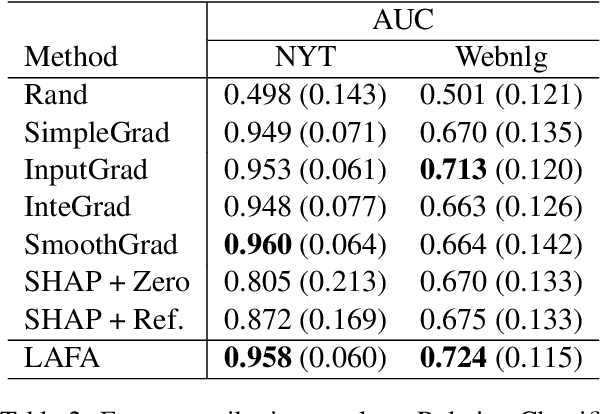
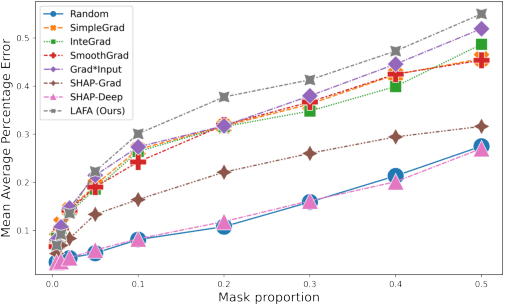
With the growing popularity of deep-learning models, model understanding becomes more important. Much effort has been devoted to demystify deep neural networks for better interpretability. Some feature attribution methods have shown promising results in computer vision, especially the gradient-based methods where effectively smoothing the gradients with reference data is key to a robust and faithful result. However, direct application of these gradient-based methods to NLP tasks is not trivial due to the fact that the input consists of discrete tokens and the "reference" tokens are not explicitly defined. In this work, we propose Locally Aggregated Feature Attribution (LAFA), a novel gradient-based feature attribution method for NLP models. Instead of relying on obscure reference tokens, it smooths gradients by aggregating similar reference texts derived from language model embeddings. For evaluation purpose, we also design experiments on different NLP tasks including Entity Recognition and Sentiment Analysis on public datasets as well as key feature detection on a constructed Amazon catalogue dataset. The superior performance of the proposed method is demonstrated through experiments.