 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA-Enabled Machine Learning Applications in Earth Observation: A Systematic Review
Jun 04, 2025



New UAV technologies and the NewSpace era are transforming Earth Observation missions and data acquisition. Numerous small platforms generate large data volume, straining bandwidth and requiring onboard decision-making to transmit high-quality information in time. While Machine Learning allows real-time autonomous processing, FPGAs balance performance with adaptability to mission-specific requirements, enabling onboard deployment. This review systematically analyzes 66 experiments deploying ML models on FPGAs for Remote Sensing applications. We introduce two distinct taxonomies to capture both efficient model architectures and FPGA implementation strategies. For transparency and reproducibility, we follow PRISMA 2020 guidelines and share all data and code at https://github.com/CedricLeon/Survey_RS-ML-FPGA.
Dataset Distillation by Automatic Training Trajectories
Jul 19, 2024



Dataset Distillation is used to create a concise, yet informative, synthetic dataset that can replace the original dataset for training purposes. Some leading methods in this domain prioritize long-range matching, involving the unrolling of training trajectories with a fixed number of steps (NS) on the synthetic dataset to align with various expert training trajectories. However, traditional long-range matching methods possess an overfitting-like problem, the fixed step size NS forces synthetic dataset to distortedly conform seen expert training trajectories, resulting in a loss of generality-especially to those from unencountered architecture. We refer to this as the Accumulated Mismatching Problem (AMP), and propose a new approach, Automatic Training Trajectories (ATT), which dynamically and adaptively adjusts trajectory length NS to address the AMP. Our method outperforms existing methods particularly in tests involving cross-architectures. Moreover, owing to its adaptive nature, it exhibits enhanced stability in the face of parameter variations.
Hierarchical Resource Partitioning on Modern GPUs: A Reinforcement Learning Approach
May 14, 2024GPU-based heterogeneous architectures are now commonly used in HPC clusters. Due to their architectural simplicity specialized for data-level parallelism, GPUs can offer much higher computational throughput and memory bandwidth than CPUs in the same generation do. However, as the available resources in GPUs have increased exponentially over the past decades, it has become increasingly difficult for a single program to fully utilize them. As a consequence, the industry has started supporting several resource partitioning features in order to improve the resource utilization by co-scheduling multiple programs on the same GPU die at the same time. Driven by the technological trend, this paper focuses on hierarchical resource partitioning on modern GPUs, and as an example, we utilize a combination of two different features available on recent NVIDIA GPUs in a hierarchical manner: MPS (Multi-Process Service), a finer-grained logical partitioning; and MIG (Multi-Instance GPU), a coarse-grained physical partitioning. We propose a method for comprehensively co-optimizing the setup of hierarchical partitioning and the selection of co-scheduling groups from a given set of jobs, based on reinforcement learning using their profiles. Our thorough experimental results demonstrate that our approach can successfully set up job concurrency, partitioning, and co-scheduling group selections simultaneously. This results in a maximum throughput improvement by a factor of 1.87 compared to the time-sharing scheduling.
Federated Learning via Decentralized Dataset Distillation in Resource-Constrained Edge Environments
Aug 31, 2022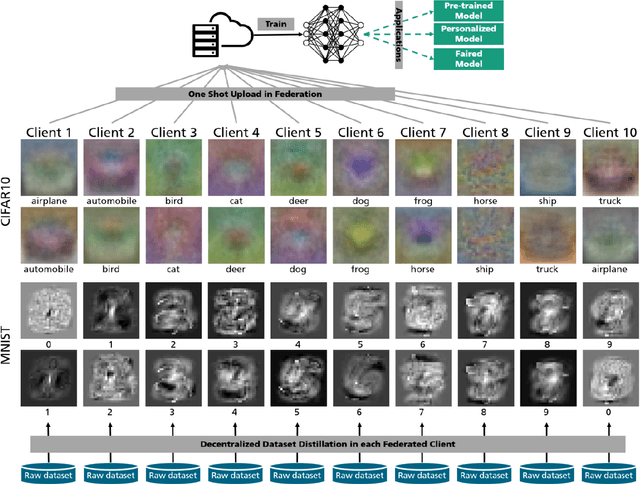
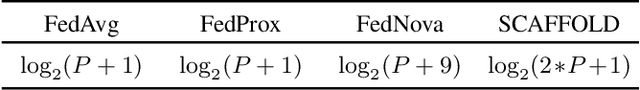
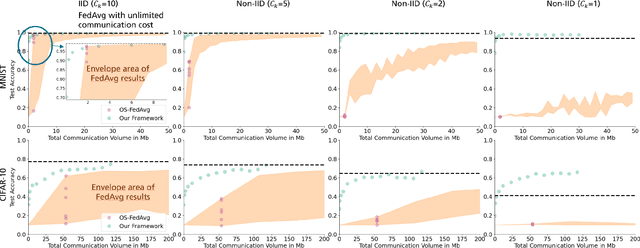
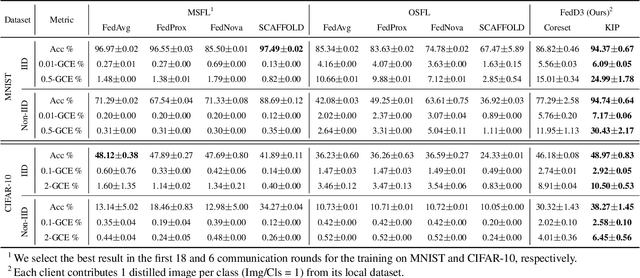
We introduce a novel federated learning framework, FedD3, which reduces the overall communication volume and with that opens up the concept of federated learning to more application scenarios in network-constrained environments. It achieves this by leveraging local dataset distillation instead of traditional learning approaches (i) to significantly reduce communication volumes and (ii) to limit transfers to one-shot communication, rather than iterative multiway communication. Instead of sharing model updates, as in other federated learning approaches, FedD3 allows the connected clients to distill the local datasets independently, and then aggregates those decentralized distilled datasets (typically in the form a few unrecognizable images, which are normally smaller than a model) across the network only once to form the final model. Our experimental results show that FedD3 significantly outperforms other federated learning frameworks in terms of needed communication volumes, while it provides the additional benefit to be able to balance the trade-off between accuracy and communication cost, depending on usage scenario or target dataset. For instance, for training an AlexNet model on a Non-IID CIFAR-10 dataset with 10 clients, FedD3 can either increase the accuracy by over 71% with a similar communication volume, or save 98% of communication volume, while reaching the same accuracy, comparing to other one-shot federated learning approaches.
Correlation-wise Smoothing: Lightweight Knowledge Extraction for HPC Monitoring Data
Oct 13, 2020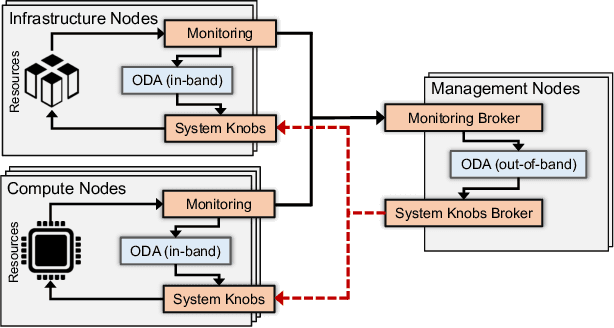
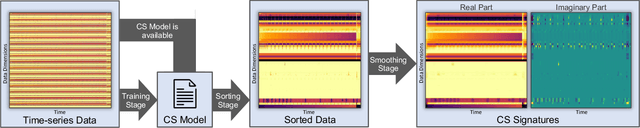
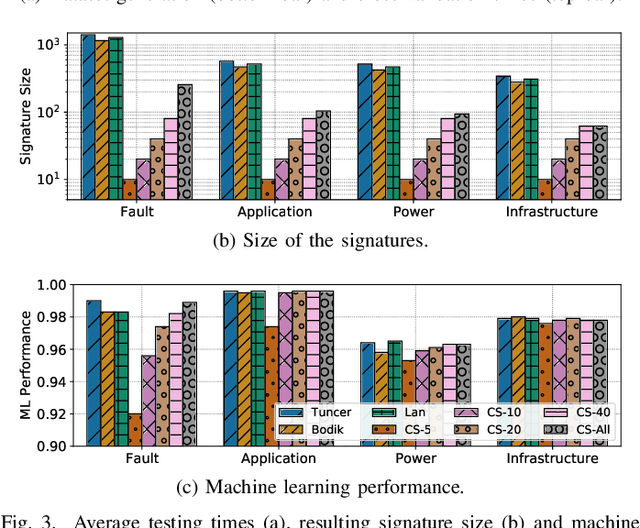
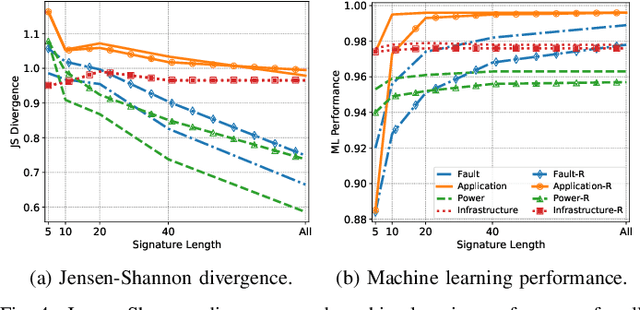
Modern High-Performance Computing (HPC) and data center operators rely more and more on data analytics techniques to improve the efficiency and reliability of their operations. They employ models that ingest time-series monitoring sensor data and transform it into actionable knowledge for system tuning: a process known as Operational Data Analytics (ODA). However, monitoring data has a high dimensionality, is hardware-dependent and difficult to interpret. This, coupled with the strict requirements of ODA, makes most traditional data mining methods impractical and in turn renders this type of data cumbersome to process. Most current ODA solutions use ad-hoc processing methods that are not generic, are sensible to the sensors' features and are not fit for visualization. In this paper we propose a novel method, called Correlation-wise Smoothing (CS), to extract descriptive signatures from time-series monitoring data in a generic and lightweight way. Our CS method exploits correlations between data dimensions to form groups and produces image-like signatures that can be easily manipulated, visualized and compared. We evaluate the CS method on HPC-ODA, a collection of datasets that we release with this work, and show that it leads to the same performance as most state-of-the-art methods while producing signatures that are up to ten times smaller and up to ten times faster, while gaining visualizability, portability across systems and clear scaling properties.
DCDB Wintermute: Enabling Online and Holistic Operational Data Analytics on HPC Systems
Oct 14, 2019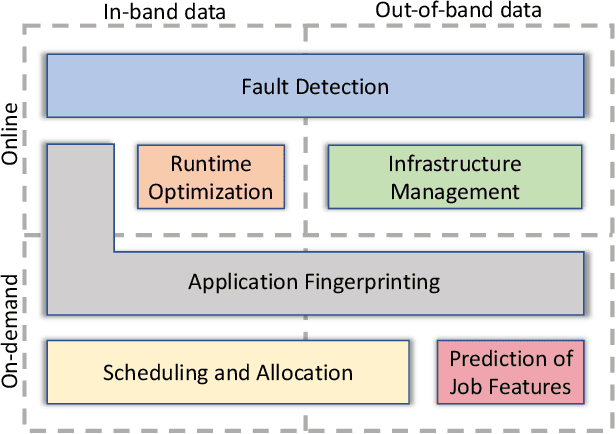
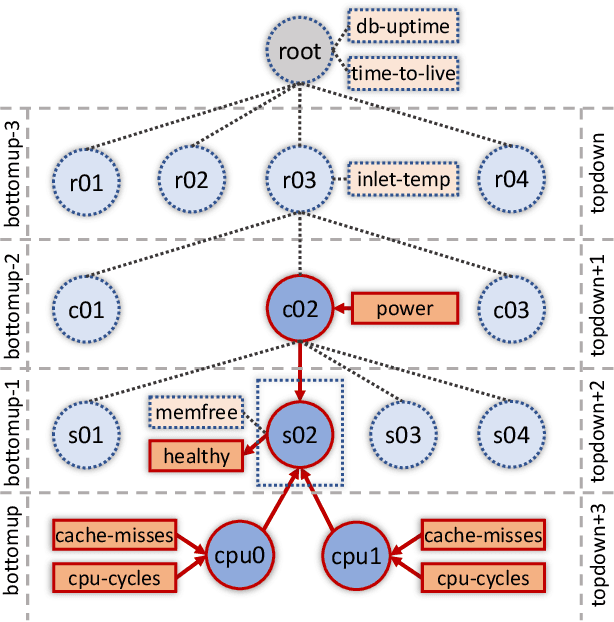
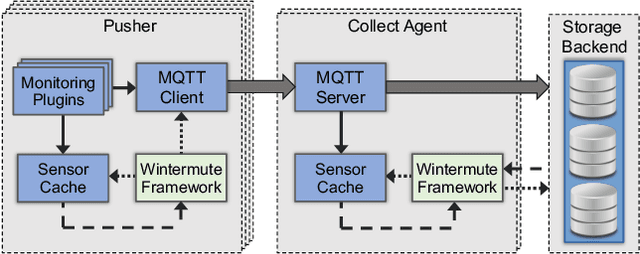
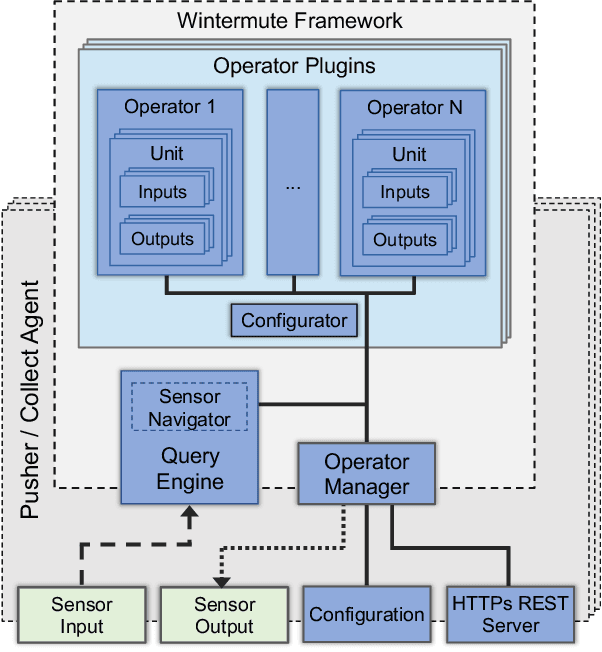
The complexity of today's HPC systems increases as we move closer to the exascale goal, raising concerns about their sustainability. In an effort to improve their efficiency and effectiveness, more and more HPC installations are experimenting with fine-grained monitoring coupled with Operational Data Analytics (ODA) to drive resource management decisions. However, while monitoring is an established reality in HPC, no generic framework exists to enable holistic and online operational data analytics, leading to insular ad-hoc solutions each addressing only specific aspects of the problem. In this paper we propose Wintermute, a novel operational data analytics framework for HPC installations, built upon the holistic DCDB monitoring system. Wintermute is designed following a survey of common operational requirements, and as such offers a large variety of configuration options to accommodate these varying requirements. Moreover, Wintermute is based on a set of logical abstractions to ease the configuration of models at a large scale and maximize code re-use. We highlight Wintermute's flexibility through a series of case studies, each targeting a different aspect of the management of HPC systems, and demonstrate its small resource footprint.