 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFC: Achieve Accurate Fast Convolution under Low-precision Arithmetic
Jul 03, 2024Fast convolution algorithms, including Winograd and FFT, can efficiently accelerate convolution operations in deep models. However, these algorithms depend on high-precision arithmetic to maintain inference accuracy, which conflicts with the model quantization. To resolve this conflict and further improve the efficiency of quantized convolution, we proposes SFC, a new algebra transform for fast convolution by extending the Discrete Fourier Transform (DFT) with symbolic computing, in which only additions are required to perform the transformation at specific transform points, avoiding the calculation of irrational number and reducing the requirement for precision. Additionally, we enhance convolution efficiency by introducing correction terms to convert invalid circular convolution outputs of the Fourier method into effective ones. The numerical error analysis is presented for the first time in this type of work and proves that our algorithms can provide a 3.68x multiplication reduction for 3x3 convolution, while the Winograd algorithm only achieves a 2.25x reduction with similarly low numerical errors. Experiments carried out on benchmarks and FPGA show that our new algorithms can further improve the computation efficiency of quantized models while maintaining accuracy, surpassing both the quantization-alone method and existing works on fast convolution quantization.
Relating-Up: Advancing Graph Neural Networks through Inter-Graph Relationships
May 07, 2024



Graph Neural Networks (GNNs) have excelled in learning from graph-structured data, especially in understanding the relationships within a single graph, i.e., intra-graph relationships. Despite their successes, GNNs are limited by neglecting the context of relationships across graphs, i.e., inter-graph relationships. Recognizing the potential to extend this capability, we introduce Relating-Up, a plug-and-play module that enhances GNNs by exploiting inter-graph relationships. This module incorporates a relation-aware encoder and a feedback training strategy. The former enables GNNs to capture relationships across graphs, enriching relation-aware graph representation through collective context. The latter utilizes a feedback loop mechanism for the recursively refinement of these representations, leveraging insights from refining inter-graph dynamics to conduct feedback loop. The synergy between these two innovations results in a robust and versatile module. Relating-Up enhances the expressiveness of GNNs, enabling them to encapsulate a wider spectrum of graph relationships with greater precision. Our evaluations across 16 benchmark datasets demonstrate that integrating Relating-Up into GNN architectures substantially improves performance, positioning Relating-Up as a formidable choice for a broad spectrum of graph representation learning tasks.
Non-Convex Robust Hypothesis Testing using Sinkhorn Uncertainty Sets
Mar 21, 2024



We present a new framework to address the non-convex robust hypothesis testing problem, wherein the goal is to seek the optimal detector that minimizes the maximum of worst-case type-I and type-II risk functions. The distributional uncertainty sets are constructed to center around the empirical distribution derived from samples based on Sinkhorn discrepancy. Given that the objective involves non-convex, non-smooth probabilistic functions that are often intractable to optimize, existing methods resort to approximations rather than exact solutions. To tackle the challenge, we introduce an exact mixed-integer exponential conic reformulation of the problem, which can be solved into a global optimum with a moderate amount of input data. Subsequently, we propose a convex approximation, demonstrating its superiority over current state-of-the-art methodologies in literature. Furthermore, we establish connections between robust hypothesis testing and regularized formulations of non-robust risk functions, offering insightful interpretations. Our numerical study highlights the satisfactory testing performance and computational efficiency of the proposed framework.
Sentinel-Guided Zero-Shot Learning: A Collaborative Paradigm without Real Data Exposure
Mar 14, 2024



With increasing concerns over data privacy and model copyrights, especially in the context of collaborations between AI service providers and data owners, an innovative SG-ZSL paradigm is proposed in this work. SG-ZSL is designed to foster efficient collaboration without the need to exchange models or sensitive data. It consists of a teacher model, a student model and a generator that links both model entities. The teacher model serves as a sentinel on behalf of the data owner, replacing real data, to guide the student model at the AI service provider's end during training. Considering the disparity of knowledge space between the teacher and student, we introduce two variants of the teacher model: the omniscient and the quasi-omniscient teachers. Under these teachers' guidance, the student model seeks to match the teacher model's performance and explores domains that the teacher has not covered. To trade off between privacy and performance, we further introduce two distinct security-level training protocols: white-box and black-box, enhancing the paradigm's adaptability. Despite the inherent challenges of real data absence in the SG-ZSL paradigm, it consistently outperforms in ZSL and GZSL tasks, notably in the white-box protocol. Our comprehensive evaluation further attests to its robustness and efficiency across various setups, including stringent black-box training protocol.
Point cloud-based registration and image fusion between cardiac SPECT MPI and CTA
Feb 10, 2024A method was proposed for the point cloud-based registration and image fusion between cardiac single photon emission computed tomography (SPECT) myocardial perfusion images (MPI) and cardiac computed tomography angiograms (CTA). Firstly, the left ventricle (LV) epicardial regions (LVERs) in SPECT and CTA images were segmented by using different U-Net neural networks trained to generate the point clouds of the LV epicardial contours (LVECs). Secondly, according to the characteristics of cardiac anatomy, the special points of anterior and posterior interventricular grooves (APIGs) were manually marked in both SPECT and CTA image volumes. Thirdly, we developed an in-house program for coarsely registering the special points of APIGs to ensure a correct cardiac orientation alignment between SPECT and CTA images. Fourthly, we employed ICP, SICP or CPD algorithm to achieve a fine registration for the point clouds (together with the special points of APIGs) of the LV epicardial surfaces (LVERs) in SPECT and CTA images. Finally, the image fusion between SPECT and CTA was realized after the fine registration. The experimental results showed that the cardiac orientation was aligned well and the mean distance error of the optimal registration method (CPD with affine transform) was consistently less than 3 mm. The proposed method could effectively fuse the structures from cardiac CTA and SPECT functional images, and demonstrated a potential in assisting in accurate diagnosis of cardiac diseases by combining complementary advantages of the two imaging modalities.
Aleatoric and Epistemic Discrimination in Classification
Jan 27, 2023



Machine learning (ML) models can underperform on certain population groups due to choices made during model development and bias inherent in the data. We categorize sources of discrimination in the ML pipeline into two classes: aleatoric discrimination, which is inherent in the data distribution, and epistemic discrimination, which is due to decisions during model development. We quantify aleatoric discrimination by determining the performance limits of a model under fairness constraints, assuming perfect knowledge of the data distribution. We demonstrate how to characterize aleatoric discrimination by applying Blackwell's results on comparing statistical experiments. We then quantify epistemic discrimination as the gap between a model's accuracy given fairness constraints and the limit posed by aleatoric discrimination. We apply this approach to benchmark existing interventions and investigate fairness risks in data with missing values. Our results indicate that state-of-the-art fairness interventions are effective at removing epistemic discrimination. However, when data has missing values, there is still significant room for improvement in handling aleatoric discrimination.
Node-Element Hypergraph Message Passing for Fluid Dynamics Simulations
Dec 30, 2022



A recent trend in deep learning research features the application of graph neural networks for mesh-based continuum mechanics simulations. Most of these frameworks operate on graphs in which each edge connects two nodes. Inspired by the data connectivity in the finite element method, we connect the nodes by elements rather than edges, effectively forming a hypergraph. We implement a message-passing network on such a node-element hypergraph and explore the capability of the network for the modeling of fluid flow. The network is tested on two common benchmark problems, namely the fluid flow around a circular cylinder and airfoil configurations. The results show that such a message-passing network defined on the node-element hypergraph is able to generate more stable and accurate temporal roll-out predictions compared to the baseline generalized message-passing network defined on a normal graph. Along with adjustments in activation function and training loss, we expect this work to set a new strong baseline for future explorations of mesh-based fluid simulations with graph neural networks.
Combined space-time reduced-order model with 3D deep convolution for extrapolating fluid dynamics
Nov 01, 2022



There is a critical need for efficient and reliable active flow control strategies to reduce drag and noise in aerospace and marine engineering applications. While traditional full-order models based on the Navier-Stokes equations are not feasible, advanced model reduction techniques can be inefficient for active control tasks, especially with strong non-linearity and convection-dominated phenomena. Using convolutional recurrent autoencoder network architectures, deep learning-based reduced-order models have been recently shown to be effective while performing several orders of magnitude faster than full-order simulations. However, these models encounter significant challenges outside the training data, limiting their effectiveness for active control and optimization tasks. In this study, we aim to improve the extrapolation capability by modifying network architecture and integrating coupled space-time physics as an implicit bias. Reduced-order models via deep learning generally employ decoupling in spatial and temporal dimensions, which can introduce modeling and approximation errors. To alleviate these errors, we propose a novel technique for learning coupled spatial-temporal correlation using a 3D convolution network. We assess the proposed technique against a standard encoder-propagator-decoder model and demonstrate a superior extrapolation performance. To demonstrate the effectiveness of 3D convolution network, we consider a benchmark problem of the flow past a circular cylinder at laminar flow conditions and use the spatio-temporal snapshots from the full-order simulations. Our proposed 3D convolution architecture accurately captures the velocity and pressure fields for varying Reynolds numbers. Compared to the standard encoder-propagator-decoder network, the spatio-temporal-based 3D convolution network improves the prediction range of Reynolds numbers outside of the training data.
Quasi-Monolithic Graph Neural Network for Fluid-Structure Interaction
Oct 09, 2022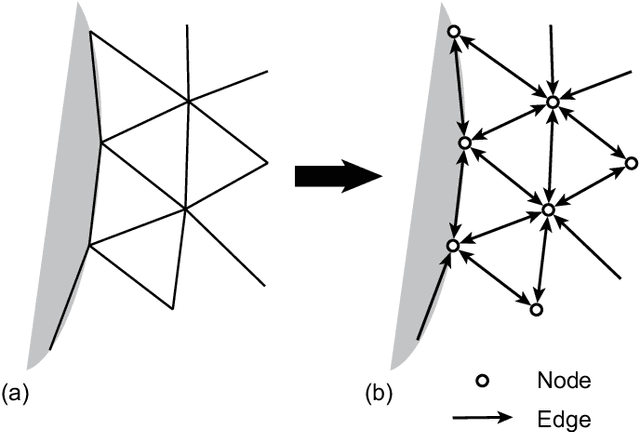

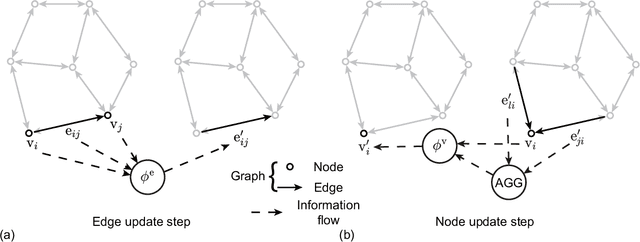
Using convolutional neural networks, deep learning-based reduced-order models have demonstrated great potential in accelerating the simulations of coupled fluid-structure systems for downstream optimization and control tasks. However, these networks have to operate on a uniform Cartesian grid due to the inherent restriction of convolutions, leading to difficulties in extracting fine physical details along a fluid-structure interface without excessive computational burden. In this work, we present a quasi-monolithic graph neural network framework for the reduced-order modelling of fluid-structure interaction systems. With the aid of an arbitrary Lagrangian-Eulerian formulation, the mesh and fluid states are evolved temporally with two sub-networks. The movement of the mesh is reduced to the evolution of several coefficients via proper orthogonal decomposition, and these coefficients are propagated through time via a multi-layer perceptron. A graph neural network is employed to predict the evolution of the fluid state based on the state of the whole system. The structural state is implicitly modelled by the movement of the mesh on the fluid-structure boundary; hence it makes the proposed data-driven methodology quasi-monolithic. The effectiveness of the proposed quasi-monolithic graph neural network architecture is assessed on a prototypical fluid-structure system of the flow around an elastically-mounted cylinder. We use the full-order flow snapshots and displacements as target physical data to learn and infer coupled fluid-structure dynamics. The proposed framework tracks the interface description and provides the state predictions during roll-out with acceptable accuracy. We also directly extract the lift and drag forces from the predicted fluid and mesh states, in contrast to existing convolution-based architectures.
A Simple Duality Proof for Wasserstein Distributionally Robust Optimization
Apr 30, 2022
We present a short and elementary proof of the duality for Wasserstein distributionally robust optimization, which holds for any arbitrary Kantorovich transport distance, any arbitrary measurable loss function, and any arbitrary nominal probability distribution, as long as certain interchangeability principle holds.