 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Nearest Neighbor Approaches for Image Captioning
May 17, 2015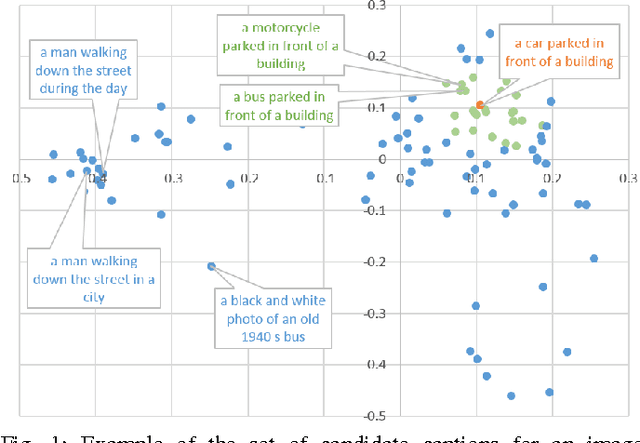
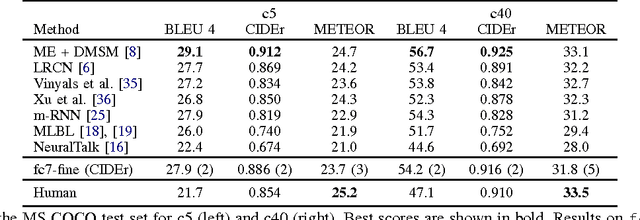

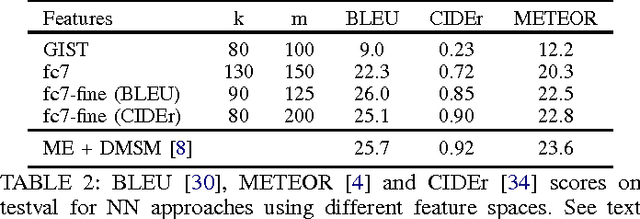
We explore a variety of nearest neighbor baseline approaches for image captioning. These approaches find a set of nearest neighbor images in the training set from which a caption may be borrowed for the query image. We select a caption for the query image by finding the caption that best represents the "consensus" of the set of candidate captions gathered from the nearest neighbor images. When measured by automatic evaluation metrics on the MS COCO caption evaluation server, these approaches perform as well as many recent approaches that generate novel captions. However, human studies show that a method that generates novel captions is still preferred over the nearest neighbor approach.
Actions and Attributes from Wholes and Parts
May 05, 2015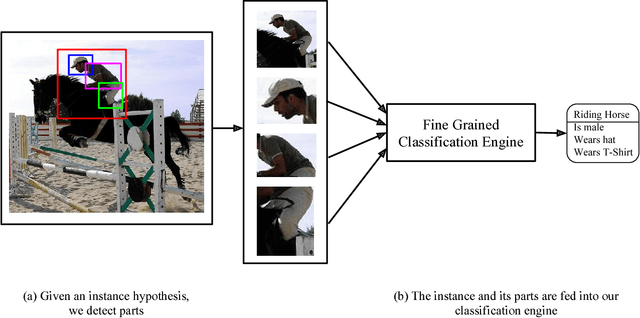
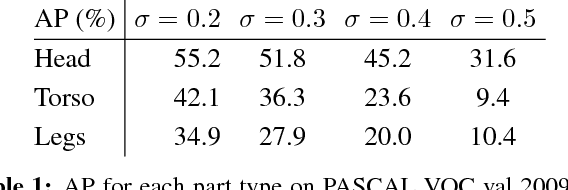
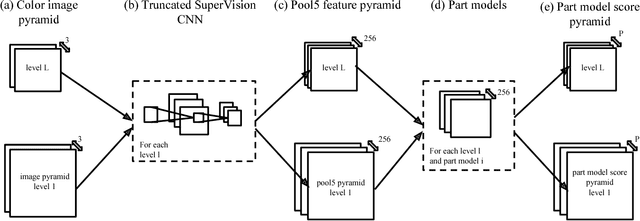

We investigate the importance of parts for the tasks of action and attribute classification. We develop a part-based approach by leveraging convolutional network features inspired by recent advances in computer vision. Our part detectors are a deep version of poselets and capture parts of the human body under a distinct set of poses. For the tasks of action and attribute classification, we train holistic convolutional neural networks and show that adding parts leads to top-performing results for both tasks. In addition, we demonstrate the effectiveness of our approach when we replace an oracle person detector, as is the default in the current evaluation protocol for both tasks, with a state-of-the-art person detection system.
Hypercolumns for Object Segmentation and Fine-grained Localization
Apr 25, 2015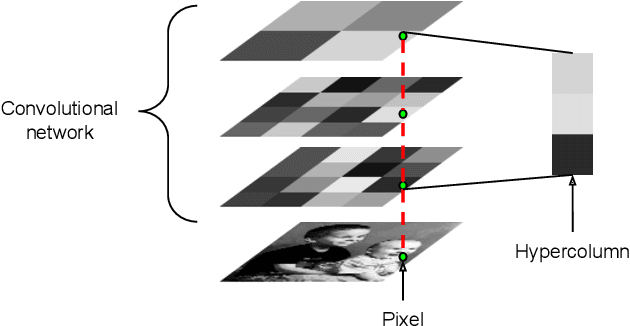
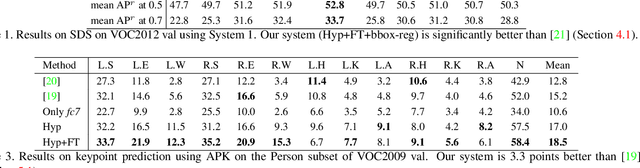
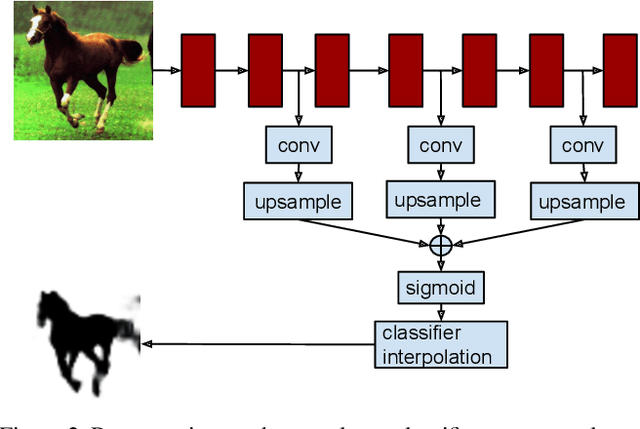
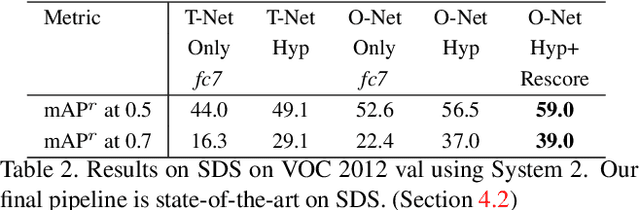
Recognition algorithms based on convolutional networks (CNNs) typically use the output of the last layer as feature representation. However, the information in this layer may be too coarse to allow precise localization. On the contrary, earlier layers may be precise in localization but will not capture semantics. To get the best of both worlds, we define the hypercolumn at a pixel as the vector of activations of all CNN units above that pixel. Using hypercolumns as pixel descriptors, we show results on three fine-grained localization tasks: simultaneous detection and segmentation[22], where we improve state-of-the-art from 49.7[22] mean AP^r to 60.0, keypoint localization, where we get a 3.3 point boost over[20] and part labeling, where we show a 6.6 point gain over a strong baseline.
Microsoft COCO: Common Objects in Context
Feb 21, 2015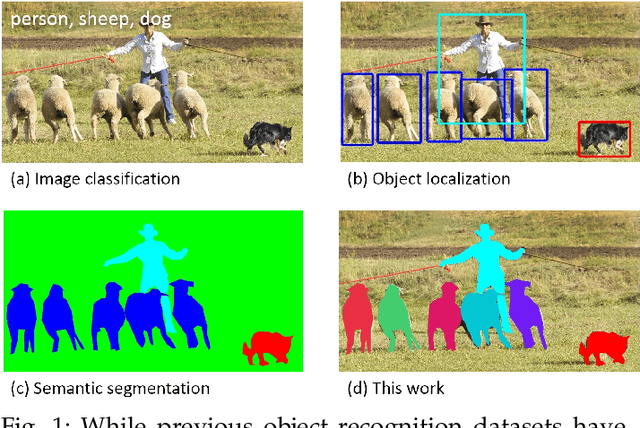



We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding. This is achieved by gathering images of complex everyday scenes containing common objects in their natural context. Objects are labeled using per-instance segmentations to aid in precise object localization. Our dataset contains photos of 91 objects types that would be easily recognizable by a 4 year old. With a total of 2.5 million labeled instances in 328k images, the creation of our dataset drew upon extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation. We present a detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet, and SUN. Finally, we provide baseline performance analysis for bounding box and segmentation detection results using a Deformable Parts Model.
Inferring 3D Object Pose in RGB-D Images
Feb 16, 2015
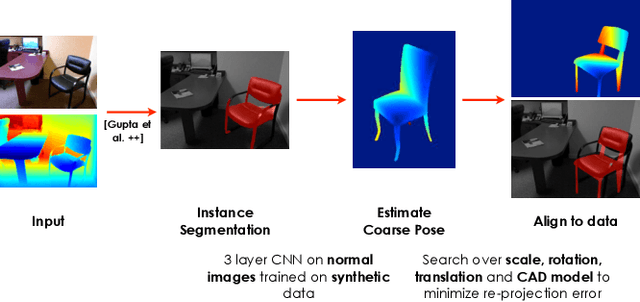
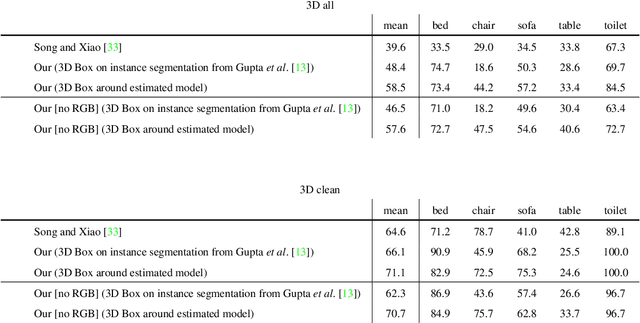
The goal of this work is to replace objects in an RGB-D scene with corresponding 3D models from a library. We approach this problem by first detecting and segmenting object instances in the scene using the approach from Gupta et al. [13]. We use a convolutional neural network (CNN) to predict the pose of the object. This CNN is trained using pixel normals in images containing rendered synthetic objects. When tested on real data, it outperforms alternative algorithms trained on real data. We then use this coarse pose estimate along with the inferred pixel support to align a small number of prototypical models to the data, and place the model that fits the best into the scene. We observe a 48% relative improvement in performance at the task of 3D detection over the current state-of-the-art [33], while being an order of magnitude faster at the same time.
LSDA: Large Scale Detection Through Adaptation
Nov 01, 2014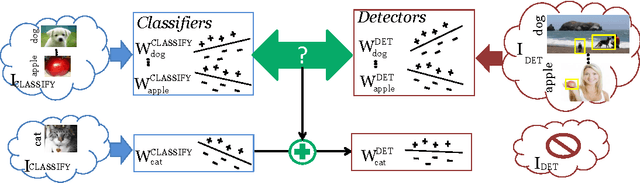
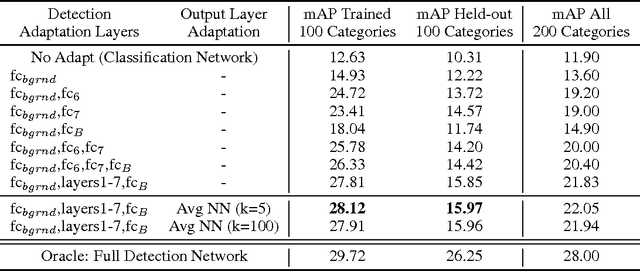
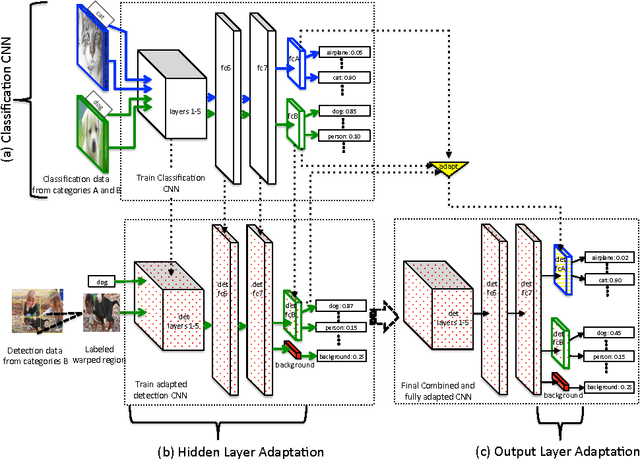
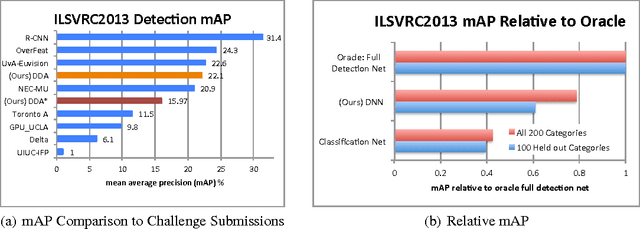
A major challenge in scaling object detection is the difficulty of obtaining labeled images for large numbers of categories. Recently, deep convolutional neural networks (CNNs) have emerged as clear winners on object classification benchmarks, in part due to training with 1.2M+ labeled classification images. Unfortunately, only a small fraction of those labels are available for the detection task. It is much cheaper and easier to collect large quantities of image-level labels from search engines than it is to collect detection data and label it with precise bounding boxes. In this paper, we propose Large Scale Detection through Adaptation (LSDA), an algorithm which learns the difference between the two tasks and transfers this knowledge to classifiers for categories without bounding box annotated data, turning them into detectors. Our method has the potential to enable detection for the tens of thousands of categories that lack bounding box annotations, yet have plenty of classification data. Evaluation on the ImageNet LSVRC-2013 detection challenge demonstrates the efficacy of our approach. This algorithm enables us to produce a >7.6K detector by using available classification data from leaf nodes in the ImageNet tree. We additionally demonstrate how to modify our architecture to produce a fast detector (running at 2fps for the 7.6K detector). Models and software are available at
Rich feature hierarchies for accurate object detection and semantic segmentation
Oct 22, 2014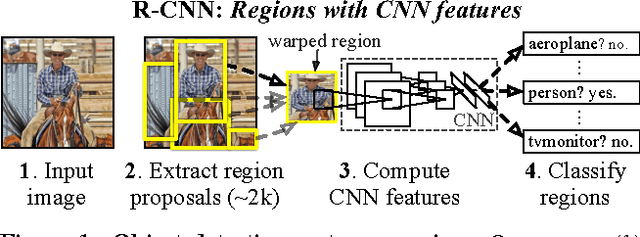


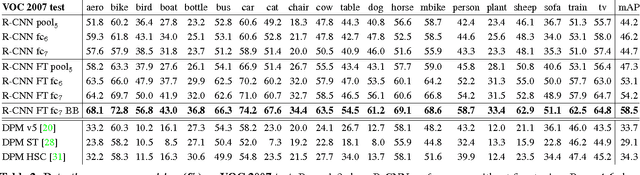
Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few years. The best-performing methods are complex ensemble systems that typically combine multiple low-level image features with high-level context. In this paper, we propose a simple and scalable detection algorithm that improves mean average precision (mAP) by more than 30% relative to the previous best result on VOC 2012---achieving a mAP of 53.3%. Our approach combines two key insights: (1) one can apply high-capacity convolutional neural networks (CNNs) to bottom-up region proposals in order to localize and segment objects and (2) when labeled training data is scarce, supervised pre-training for an auxiliary task, followed by domain-specific fine-tuning, yields a significant performance boost. Since we combine region proposals with CNNs, we call our method R-CNN: Regions with CNN features. We also compare R-CNN to OverFeat, a recently proposed sliding-window detector based on a similar CNN architecture. We find that R-CNN outperforms OverFeat by a large margin on the 200-class ILSVRC2013 detection dataset. Source code for the complete system is available at http://www.cs.berkeley.edu/~rbg/rcnn.
Deformable Part Models are Convolutional Neural Networks
Oct 01, 2014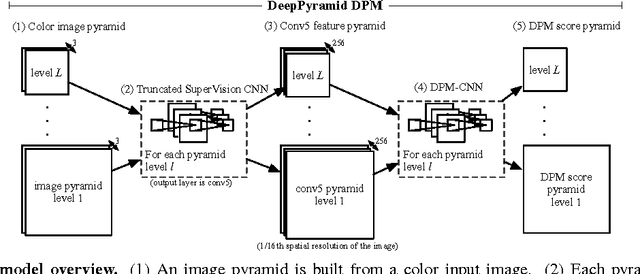
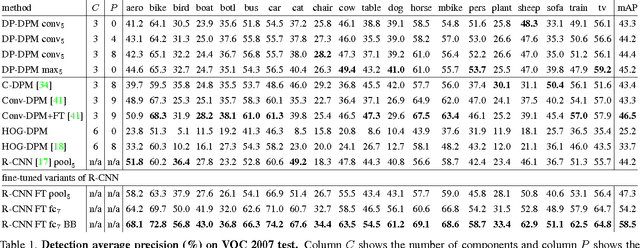
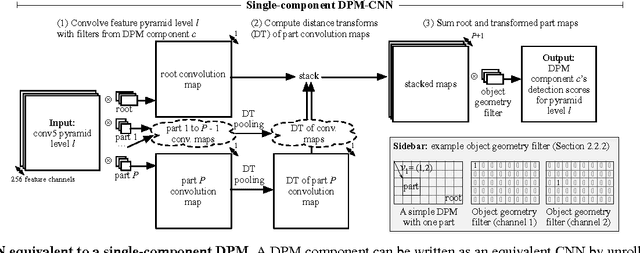
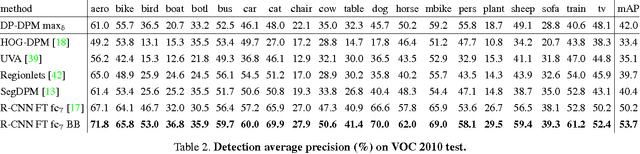
Deformable part models (DPMs) and convolutional neural networks (CNNs) are two widely used tools for visual recognition. They are typically viewed as distinct approaches: DPMs are graphical models (Markov random fields), while CNNs are "black-box" non-linear classifiers. In this paper, we show that a DPM can be formulated as a CNN, thus providing a novel synthesis of the two ideas. Our construction involves unrolling the DPM inference algorithm and mapping each step to an equivalent (and at times novel) CNN layer. From this perspective, it becomes natural to replace the standard image features used in DPM with a learned feature extractor. We call the resulting model DeepPyramid DPM and experimentally validate it on PASCAL VOC. DeepPyramid DPM significantly outperforms DPMs based on histograms of oriented gradients features (HOG) and slightly outperforms a comparable version of the recently introduced R-CNN detection system, while running an order of magnitude faster.
Analyzing the Performance of Multilayer Neural Networks for Object Recognition
Sep 22, 2014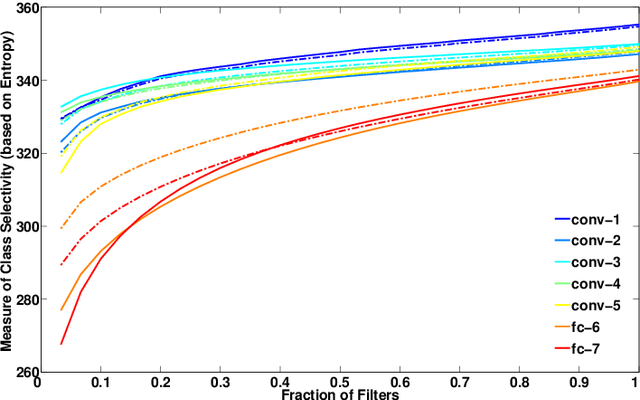


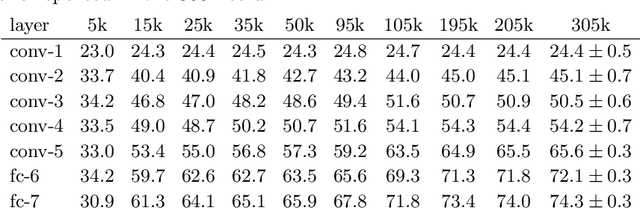
In the last two years, convolutional neural networks (CNNs) have achieved an impressive suite of results on standard recognition datasets and tasks. CNN-based features seem poised to quickly replace engineered representations, such as SIFT and HOG. However, compared to SIFT and HOG, we understand much less about the nature of the features learned by large CNNs. In this paper, we experimentally probe several aspects of CNN feature learning in an attempt to help practitioners gain useful, evidence-backed intuitions about how to apply CNNs to computer vision problems.
Learning Rich Features from RGB-D Images for Object Detection and Segmentation
Jul 22, 2014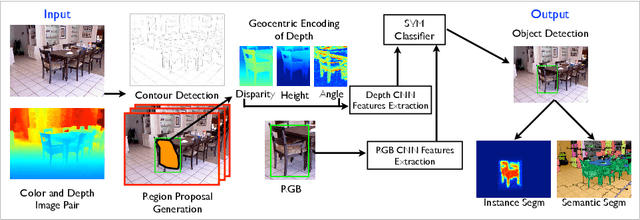
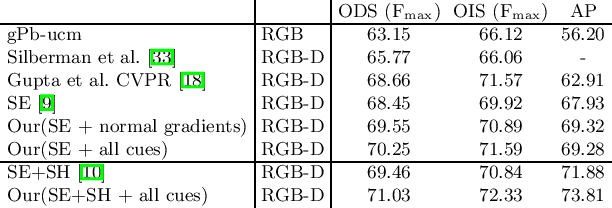

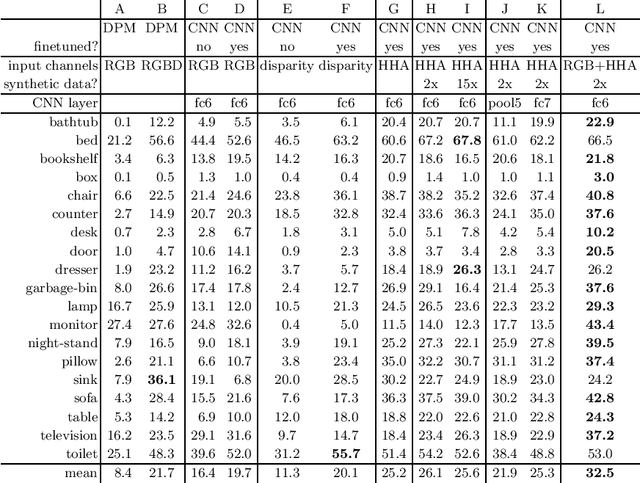
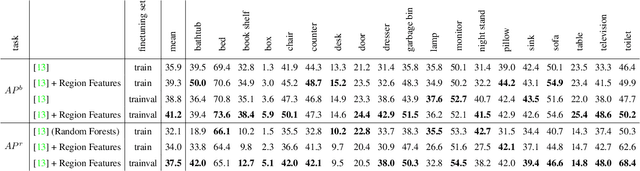
In this paper we study the problem of object detection for RGB-D images using semantically rich image and depth features. We propose a new geocentric embedding for depth images that encodes height above ground and angle with gravity for each pixel in addition to the horizontal disparity. We demonstrate that this geocentric embedding works better than using raw depth images for learning feature representations with convolutional neural networks. Our final object detection system achieves an average precision of 37.3%, which is a 56% relative improvement over existing methods. We then focus on the task of instance segmentation where we label pixels belonging to object instances found by our detector. For this task, we propose a decision forest approach that classifies pixels in the detection window as foreground or background using a family of unary and binary tests that query shape and geocentric pose features. Finally, we use the output from our object detectors in an existing superpixel classification framework for semantic scene segmentation and achieve a 24% relative improvement over current state-of-the-art for the object categories that we study. We believe advances such as those represented in this paper will facilitate the use of perception in fields like robotics.