 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Neural Beamforming for Multi-channel Speech Separation Against Location Uncertainty
Feb 27, 2023



Multi-channel speech separation using speaker's directional information has demonstrated significant gains over blind speech separation. However, it has two limitations. First, substantial performance degradation is observed when the coming directions of two sounds are close. Second, the result highly relies on the precise estimation of the speaker's direction. To overcome these issues, this paper proposes 3D features and an associated 3D neural beamformer for multi-channel speech separation. Previous works in this area are extended in two important directions. First, the traditional 1D directional beam patterns are generalized to 3D. This enables the model to extract speech from any target region in the 3D space. Thus, speakers with similar directions but different elevations or distances become separable. Second, to handle the speaker location uncertainty, previously proposed spatial feature is extended to a new 3D region feature. The proposed 3D region feature and 3D neural beamformer are evaluated under an in-car scenario. Experimental results demonstrated that the combination of 3D feature and 3D beamformer can achieve comparable performance to the separation model with ground truth speaker location as input.
Towards Unified All-Neural Beamforming for Time and Frequency Domain Speech Separation
Dec 24, 2022Recently, frequency domain all-neural beamforming methods have achieved remarkable progress for multichannel speech separation. In parallel, the integration of time domain network structure and beamforming also gains significant attention. This study proposes a novel all-neural beamforming method in time domain and makes an attempt to unify the all-neural beamforming pipelines for time domain and frequency domain multichannel speech separation. The proposed model consists of two modules: separation and beamforming. Both modules perform temporal-spectral-spatial modeling and are trained from end-to-end using a joint loss function. The novelty of this study lies in two folds. Firstly, a time domain directional feature conditioned on the direction of the target speaker is proposed, which can be jointly optimized within the time domain architecture to enhance target signal estimation. Secondly, an all-neural beamforming network in time domain is designed to refine the pre-separated results. This module features with parametric time-variant beamforming coefficient estimation, without explicitly following the derivation of optimal filters that may lead to an upper bound. The proposed method is evaluated on simulated reverberant overlapped speech data derived from the AISHELL-1 corpus. Experimental results demonstrate significant performance improvements over frequency domain state-of-the-arts, ideal magnitude masks and existing time domain neural beamforming methods.
Probing Deep Speaker Embeddings for Speaker-related Tasks
Dec 14, 2022



Deep speaker embeddings have shown promising results in speaker recognition, as well as in other speaker-related tasks. However, some issues are still under explored, for instance, the information encoded in these representations and their influence on downstream tasks. Four deep speaker embeddings are studied in this paper, namely, d-vector, x-vector, ResNetSE-34 and ECAPA-TDNN. Inspired by human voice mechanisms, we explored possibly encoded information from perspectives of identity, contents and channels; Based on this, experiments were conducted on three categories of speaker-related tasks to further explore impacts of different deep embeddings, including discriminative tasks (speaker verification and diarization), guiding tasks (target speaker detection and extraction) and regulating tasks (multi-speaker text-to-speech). Results show that all deep embeddings encoded channel and content information in addition to speaker identity, but the extent could vary and their performance on speaker-related tasks can be tremendously different: ECAPA-TDNN is dominant in discriminative tasks, and d-vector leads the guiding tasks, while regulating task is less sensitive to the choice of speaker representations. These may benefit future research utilizing speaker embeddings.
High Fidelity Speech Enhancement with Band-split RNN
Dec 01, 2022This report presents the development of our speech enhancement system, which includes the use of a recently proposed music separation model, the band-split recurrent neural network (BSRNN), and a MetricGAN-based training objective to improve non-differentiable quality metrics such as perceptual evaluation of speech quality (PESQ) score. Experiment conducted on Interspeech 2021 DNS challenge shows that our BSRNN system outperforms various top-ranking benchmark systems in previous deep noise suppression (DNS) challenges and achieves state-of-the-art (SOTA) result on the DNS-2020 non-blind test set in both offline and online scenarios.
Parameter-efficient transfer learning of pre-trained Transformer models for speaker verification using adapters
Oct 28, 2022



Recently, the pre-trained Transformer models have received a rising interest in the field of speech processing thanks to their great success in various downstream tasks. However, most fine-tuning approaches update all the parameters of the pre-trained model, which becomes prohibitive as the model size grows and sometimes results in overfitting on small datasets. In this paper, we conduct a comprehensive analysis of applying parameter-efficient transfer learning (PETL) methods to reduce the required learnable parameters for adapting to speaker verification tasks. Specifically, during the fine-tuning process, the pre-trained models are frozen, and only lightweight modules inserted in each Transformer block are trainable (a method known as adapters). Moreover, to boost the performance in a cross-language low-resource scenario, the Transformer model is further tuned on a large intermediate dataset before directly fine-tuning it on a small dataset. With updating fewer than 4% of parameters, (our proposed) PETL-based methods achieve comparable performances with full fine-tuning methods (Vox1-O: 0.55%, Vox1-E: 0.82%, Vox1-H:1.73%).
Improving Dual-Microphone Speech Enhancement by Learning Cross-Channel Features with Multi-Head Attention
May 03, 2022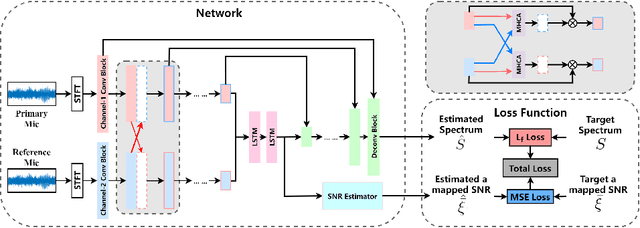
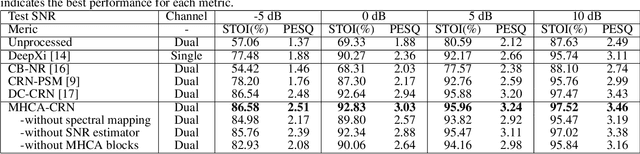
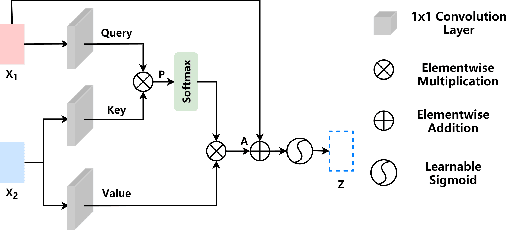
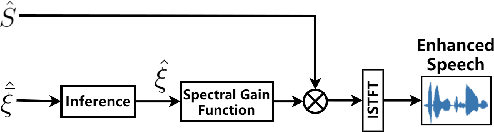
Hand-crafted spatial features, such as inter-channel intensity difference (IID) and inter-channel phase difference (IPD), play a fundamental role in recent deep learning based dual-microphone speech enhancement (DMSE) systems. However, learning the mutual relationship between artificially designed spatial and spectral features is hard in the end-to-end DMSE. In this work, a novel architecture for DMSE using a multi-head cross-attention based convolutional recurrent network (MHCA-CRN) is presented. The proposed MHCA-CRN model includes a channel-wise encoding structure for preserving intra-channel features and a multi-head cross-attention mechanism for fully exploiting cross-channel features. In addition, the proposed approach specifically formulates the decoder with an extra SNR estimator to estimate frame-level SNR under a multi-task learning framework, which is expected to avoid speech distortion led by end-to-end DMSE module. Finally, a spectral gain function is adopted to further suppress the unnatural residual noise. Experiment results demonstrated superior performance of the proposed model against several state-of-the-art models.
Speaker-Aware Mixture of Mixtures Training for Weakly Supervised Speaker Extraction
Apr 15, 2022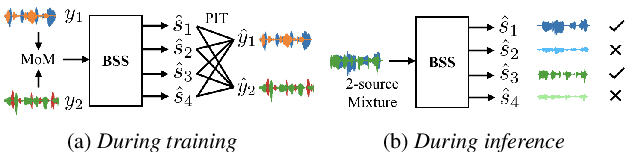

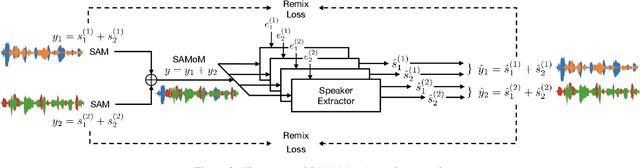
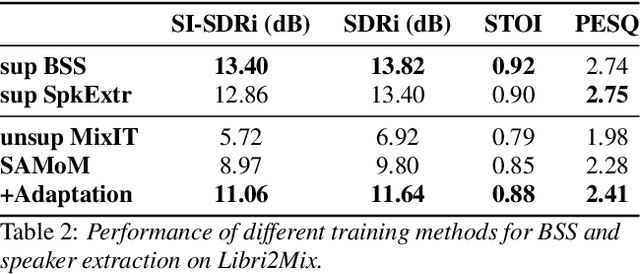
Dominant researches adopt supervised training for speaker extraction, while the scarcity of ideally clean corpus and channel mismatch problem are rarely considered. To this end, we propose speaker-aware mixture of mixtures training (SAMoM), utilizing the consistency of speaker identity among target source, enrollment utterance and target estimate to weakly supervise the training of a deep speaker extractor. In SAMoM, the input is constructed by mixing up different speaker-aware mixtures (SAMs), each contains multiple speakers with their identities known and enrollment utterances available. Informed by enrollment utterances, target speech is extracted from the input one by one, such that the estimated targets can approximate the original SAMs after a remix in accordance with the identity consistency. Moreover, using SAMoM in a semi-supervised setting with a certain amount of clean sources enables application in noisy scenarios. Extensive experiments on Libri2Mix show that the proposed method achieves promising results without access to any clean sources (11.06dB SI-SDRi). With a domain adaptation, our approach even outperformed supervised framework in a cross-domain evaluation on AISHELL-1.
Target Confusion in End-to-end Speaker Extraction: Analysis and Approaches
Apr 04, 2022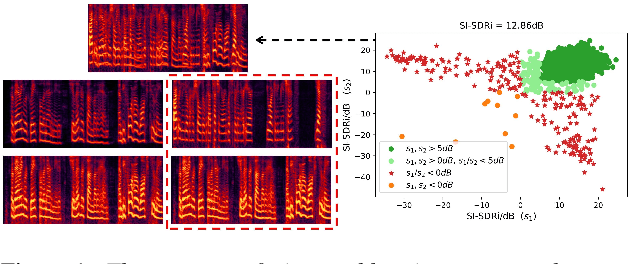
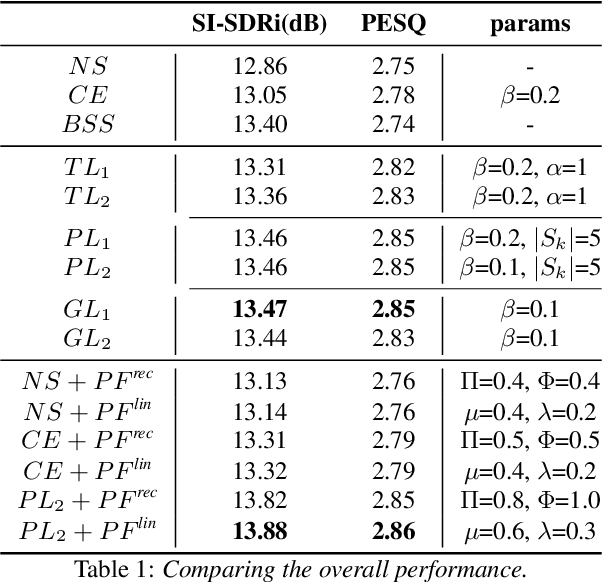

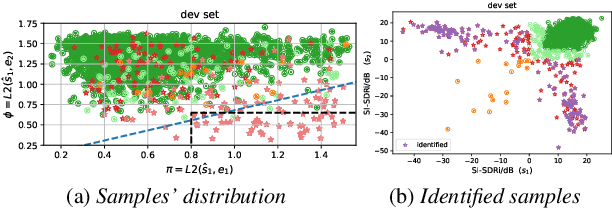
Recently, end-to-end speaker extraction has attracted increasing attention and shown promising results. However, its performance is often inferior to that of a blind source separation (BSS) counterpart with a similar network architecture, due to the auxiliary speaker encoder may sometimes generate ambiguous speaker embeddings. Such ambiguous guidance information may confuse the separation network and hence lead to wrong extraction results, which deteriorates the overall performance. We refer to this as the target confusion problem. In this paper, we conduct an analysis of such an issue and solve it in two stages. In the training phase, we propose to integrate metric learning methods to improve the distinguishability of embeddings produced by the speaker encoder. While for inference, a novel post-filtering strategy is designed to revise the wrong results. Specifically, we first identify these confusion samples by measuring the similarities between output estimates and enrollment utterances, after which the true target sources are recovered by a subtraction operation. Experiments show that performance improvement of more than 1dB SI-SDRi can be brought, which validates the effectiveness of our methods and emphasizes the impact of the target confusion problem.
Learning Decoupling Features Through Orthogonality Regularization
Mar 31, 2022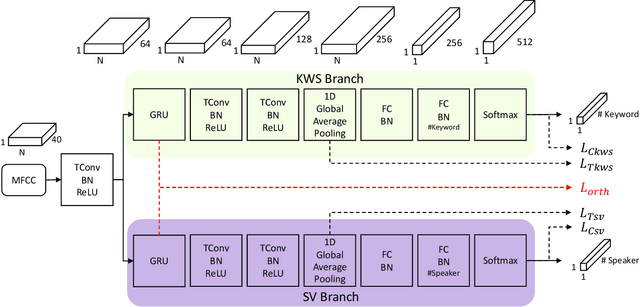
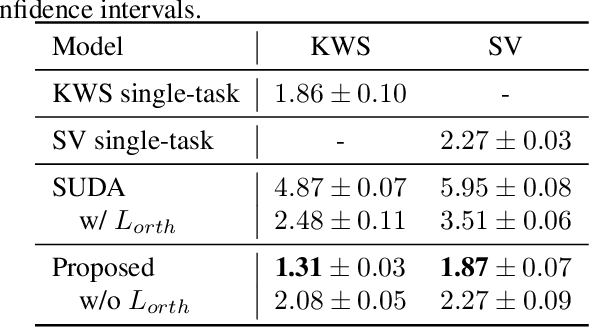
Keyword spotting (KWS) and speaker verification (SV) are two important tasks in speech applications. Research shows that the state-of-art KWS and SV models are trained independently using different datasets since they expect to learn distinctive acoustic features. However, humans can distinguish language content and the speaker identity simultaneously. Motivated by this, we believe it is important to explore a method that can effectively extract common features while decoupling task-specific features. Bearing this in mind, a two-branch deep network (KWS branch and SV branch) with the same network structure is developed and a novel decoupling feature learning method is proposed to push up the performance of KWS and SV simultaneously where speaker-invariant keyword representations and keyword-invariant speaker representations are expected respectively. Experiments are conducted on Google Speech Commands Dataset (GSCD). The results demonstrate that the orthogonality regularization helps the network to achieve SOTA EER of 1.31% and 1.87% on KWS and SV, respectively.
Text Anchor Based Metric Learning for Small-footprint Keyword Spotting
Aug 12, 2021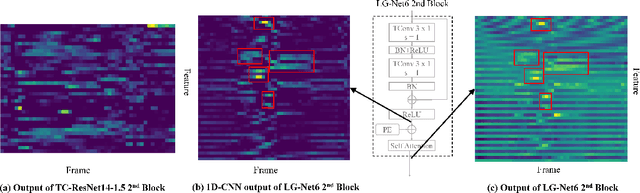

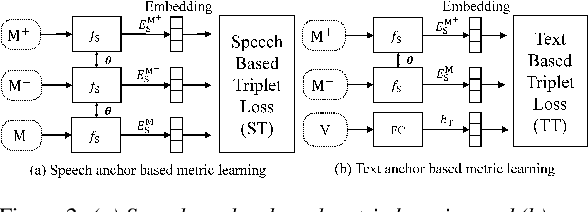
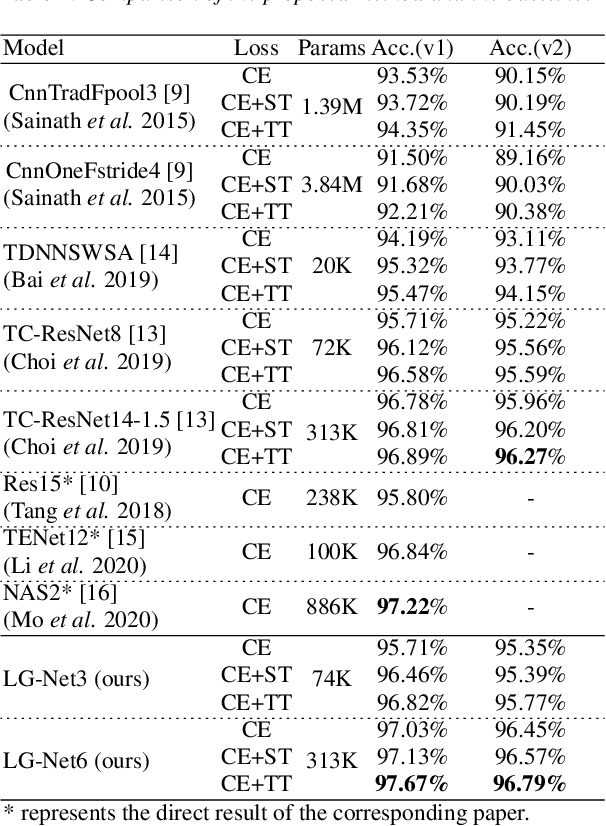
Keyword Spotting (KWS) remains challenging to achieve the trade-off between small footprint and high accuracy. Recently proposed metric learning approaches improved the generalizability of models for the KWS task, and 1D-CNN based KWS models have achieved the state-of-the-arts (SOTA) in terms of model size. However, for metric learning, due to data limitations, the speech anchor is highly susceptible to the acoustic environment and speakers. Also, we note that the 1D-CNN models have limited capability to capture long-term temporal acoustic features. To address the above problems, we propose to utilize text anchors to improve the stability of anchors. Furthermore, a new type of model (LG-Net) is exquisitely designed to promote long-short term acoustic feature modeling based on 1D-CNN and self-attention. Experiments are conducted on Google Speech Commands Dataset version 1 (GSCDv1) and 2 (GSCDv2). The results demonstrate that the proposed text anchor based metric learning method shows consistent improvements over speech anchor on representative CNN-based models. Moreover, our LG-Net model achieves SOTA accuracy of 97.67% and 96.79% on two datasets, respectively. It is encouraged to see that our lighter LG-Net with only 74k parameters obtains 96.82% KWS accuracy on the GSCDv1 and 95.77% KWS accuracy on the GSCDv2.