 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining A Multi-stage Deep Classifier with Feedback Signals
Nov 12, 2023



Multi-Stage Classifier (MSC) - several classifiers working sequentially in an arranged order and classification decision is partially made at each step - is widely used in industrial applications for various resource limitation reasons. The classifiers of a multi-stage process are usually Neural Network (NN) models trained independently or in their inference order without considering the signals from the latter stages. Aimed at two-stage binary classification process, the most common type of MSC, we propose a novel training framework, named Feedback Training. The classifiers are trained in an order reverse to their actual working order, and the classifier at the later stage is used to guide the training of initial-stage classifier via a sample weighting method. We experimentally show the efficacy of our proposed approach, and its great superiority under the scenario of few-shot training.
CLUE: A Chinese Language Understanding Evaluation Benchmark
Apr 14, 2020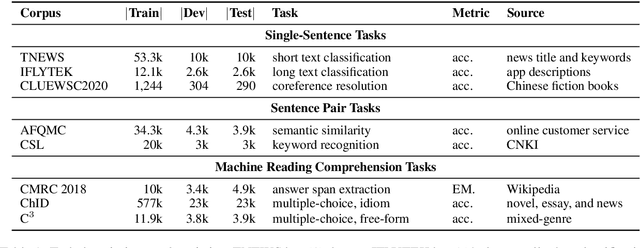
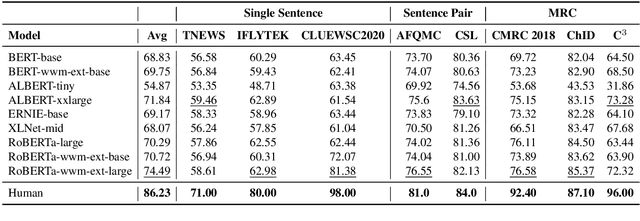
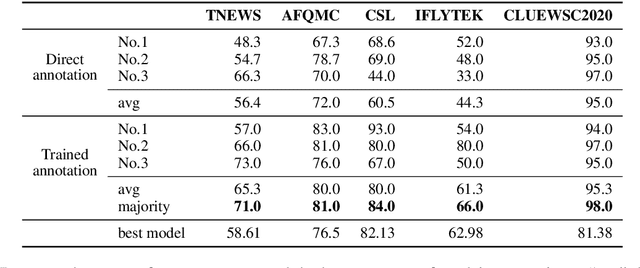
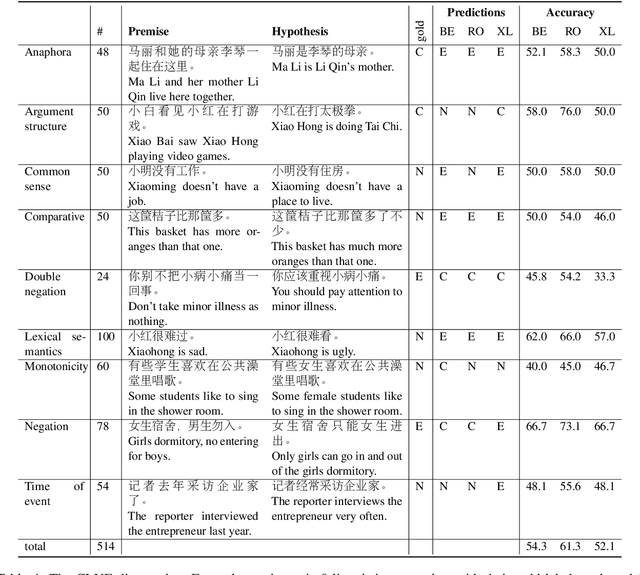
We introduce CLUE, a Chinese Language Understanding Evaluation benchmark. It contains eight different tasks, including single-sentence classification, sentence pair classification, and machine reading comprehension. We evaluate CLUE on a number of existing full-network pre-trained models for Chinese. We also include a small hand-crafted diagnostic test set designed to probe specific linguistic phenomena using different models, some of which are unique to Chinese. Along with CLUE, we release a large clean crawled raw text corpus that can be used for model pre-training. We release CLUE, baselines and pre-training dataset on Github.