 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilized SVRG: Simple Variance Reduction for Nonconvex Optimization
May 01, 2019
Variance reduction techniques like SVRG provide simple and fast algorithms for optimizing a convex finite-sum objective. For nonconvex objectives, these techniques can also find a first-order stationary point (with small gradient). However, in nonconvex optimization it is often crucial to find a second-order stationary point (with small gradient and almost PSD hessian). In this paper, we show that Stabilized SVRG (a simple variant of SVRG) can find an $\epsilon$-second-order stationary point using only $\widetilde{O}(n^{2/3}/\epsilon^2+n/\epsilon^{1.5})$ stochastic gradients. To our best knowledge, this is the first second-order guarantee for a simple variant of SVRG. The running time almost matches the known guarantees for finding $\epsilon$-first-order stationary points.
The Step Decay Schedule: A Near Optimal, Geometrically Decaying Learning Rate Procedure
Apr 29, 2019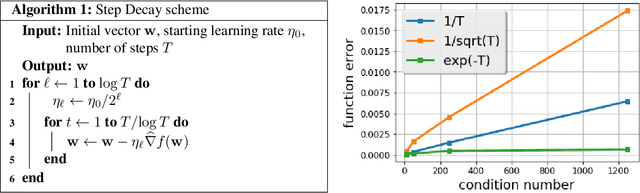
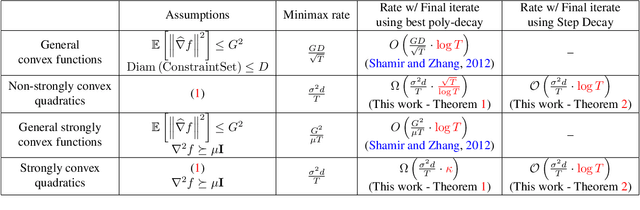

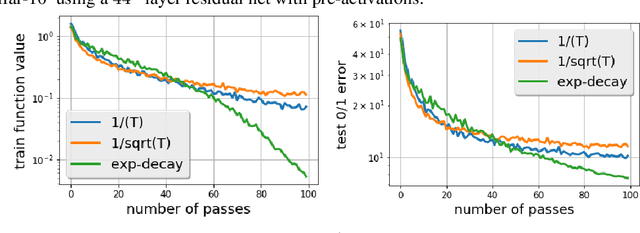
There is a stark disparity between the step size schedules used in practical large scale machine learning and those that are considered optimal by the theory of stochastic approximation. In theory, most results utilize polynomially decaying learning rate schedules, while, in practice, the "Step Decay" schedule is among the most popular schedules, where the learning rate is cut every constant number of epochs (i.e. this is a geometrically decaying schedule). This work examines the step-decay schedule for the stochastic optimization problem of streaming least squares regression (both in the non-strongly convex and strongly convex case), where we show that a sharp theoretical characterization of an optimal learning rate schedule is far more nuanced than suggested by previous work. We focus specifically on the rate that is achievable when using the final iterate of stochastic gradient descent, as is commonly done in practice. Our main result provably shows that a properly tuned geometrically decaying learning rate schedule provides an exponential improvement (in terms of the condition number) over any polynomially decaying learning rate schedule. We also provide experimental support for wider applicability of these results, including for training modern deep neural networks.
Stochastic Gradient Descent Escapes Saddle Points Efficiently
Feb 13, 2019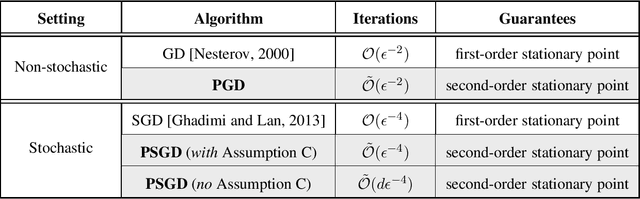
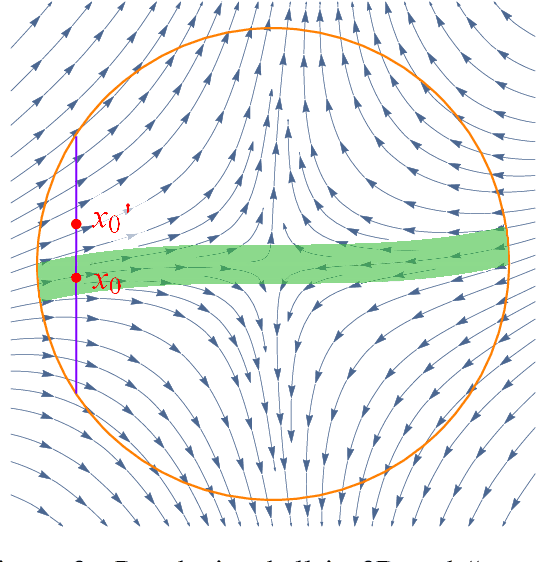
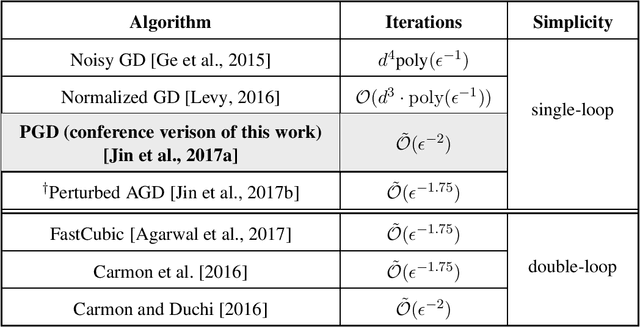
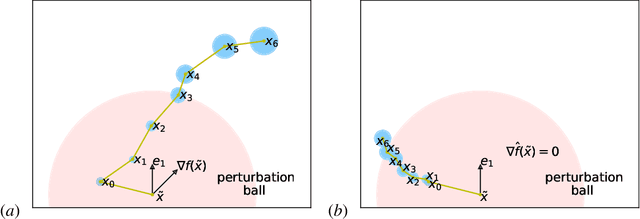
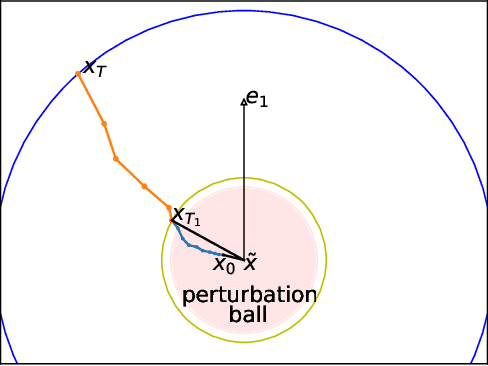
This paper considers the perturbed stochastic gradient descent algorithm and shows that it finds $\epsilon$-second order stationary points ($\left\|\nabla f(x)\right\|\leq \epsilon$ and $\nabla^2 f(x) \succeq -\sqrt{\epsilon} \mathbf{I}$) in $\tilde{O}(d/\epsilon^4)$ iterations, giving the first result that has linear dependence on dimension for this setting. For the special case, where stochastic gradients are Lipschitz, the dependence on dimension reduces to polylogarithmic. In addition to giving new results, this paper also presents a simplified proof strategy that gives a shorter and more elegant proof of previously known results (Jin et al. 2017) on perturbed gradient descent algorithm.
A Short Note on Concentration Inequalities for Random Vectors with SubGaussian Norm
Feb 11, 2019In this note, we derive concentration inequalities for random vectors with subGaussian norm (a generalization of both subGaussian random vectors and norm bounded random vectors), which are tight up to logarithmic factors.
Understanding Composition of Word Embeddings via Tensor Decomposition
Feb 02, 2019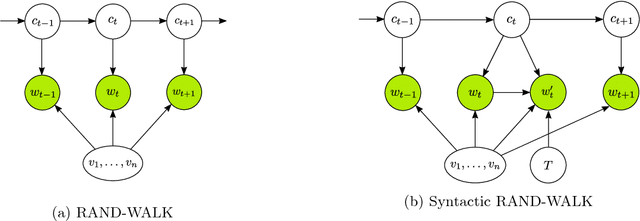

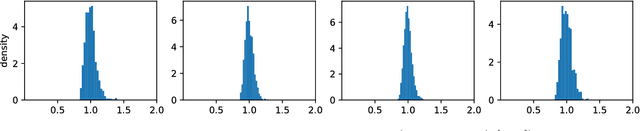
Word embedding is a powerful tool in natural language processing. In this paper we consider the problem of word embedding composition \--- given vector representations of two words, compute a vector for the entire phrase. We give a generative model that can capture specific syntactic relations between words. Under our model, we prove that the correlations between three words (measured by their PMI) form a tensor that has an approximate low rank Tucker decomposition. The result of the Tucker decomposition gives the word embeddings as well as a core tensor, which can be used to produce better compositions of the word embeddings. We also complement our theoretical results with experiments that verify our assumptions, and demonstrate the effectiveness of the new composition method.
Simulated Tempering Langevin Monte Carlo II: An Improved Proof using Soft Markov Chain Decomposition
Nov 29, 2018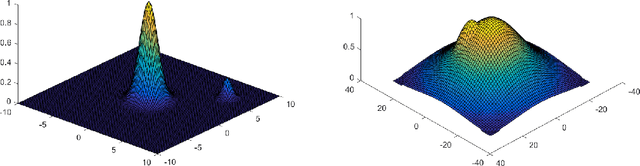
A key task in Bayesian machine learning is sampling from distributions that are only specified up to a partition function (i.e., constant of proportionality). One prevalent example of this is sampling posteriors in parametric distributions, such as latent-variable generative models. However sampling (even very approximately) can be #P-hard. Classical results going back to Bakry and \'Emery (1985) on sampling focus on log-concave distributions, and show a natural Markov chain called Langevin diffusion mixes in polynomial time. However, all log-concave distributions are uni-modal, while in practice it is very common for the distribution of interest to have multiple modes. In this case, Langevin diffusion suffers from torpid mixing. We address this problem by combining Langevin diffusion with simulated tempering. The result is a Markov chain that mixes more rapidly by transitioning between different temperatures of the distribution. We analyze this Markov chain for a mixture of (strongly) log-concave distributions of the same shape. In particular, our technique applies to the canonical multi-modal distribution: a mixture of gaussians (of equal variance). Our algorithm efficiently samples from these distributions given only access to the gradient of the log-pdf. For the analysis, we introduce novel techniques for proving spectral gaps based on decomposing the action of the generator of the diffusion. Previous approaches rely on decomposing the state space as a partition of sets, while our approach can be thought of as decomposing the stationary measure as a mixture of distributions (a "soft partition"). Additional materials for the paper can be found at http://tiny.cc/glr17. The proof and results have been improved and generalized from the precursor at www.arxiv.org/abs/1710.02736.
* 55 pages. arXiv admin note: text overlap with arXiv:1710.02736
High-Dimensional Robust Mean Estimation in Nearly-Linear Time
Nov 23, 2018
We study the fundamental problem of high-dimensional mean estimation in a robust model where a constant fraction of the samples are adversarially corrupted. Recent work gave the first polynomial time algorithms for this problem with dimension-independent error guarantees for several families of structured distributions. In this work, we give the first nearly-linear time algorithms for high-dimensional robust mean estimation. Specifically, we focus on distributions with (i) known covariance and sub-gaussian tails, and (ii) unknown bounded covariance. Given $N$ samples on $\mathbb{R}^d$, an $\epsilon$-fraction of which may be arbitrarily corrupted, our algorithms run in time $\tilde{O}(Nd) / \mathrm{poly}(\epsilon)$ and approximate the true mean within the information-theoretically optimal error, up to constant factors. Previous robust algorithms with comparable error guarantees have running times $\tilde{\Omega}(N d^2)$, for $\epsilon = \Omega(1)$. Our algorithms rely on a natural family of SDPs parameterized by our current guess $\nu$ for the unknown mean $\mu^\star$. We give a win-win analysis establishing the following: either a near-optimal solution to the primal SDP yields a good candidate for $\mu^\star$ -- independent of our current guess $\nu$ -- or the dual SDP yields a new guess $\nu'$ whose distance from $\mu^\star$ is smaller by a constant factor. We exploit the special structure of the corresponding SDPs to show that they are approximately solvable in nearly-linear time. Our approach is quite general, and we believe it can also be applied to obtain nearly-linear time algorithms for other high-dimensional robust learning problems.
Stronger generalization bounds for deep nets via a compression approach
Nov 05, 2018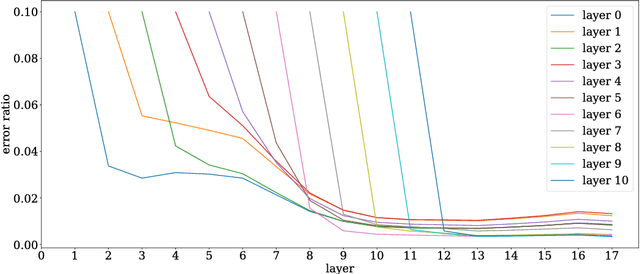
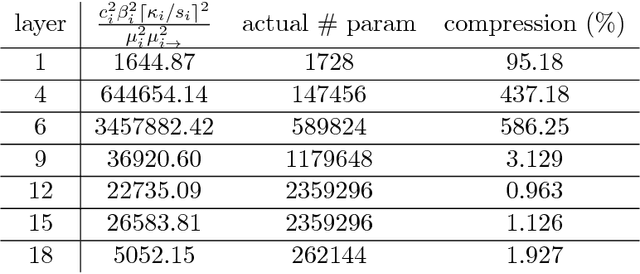
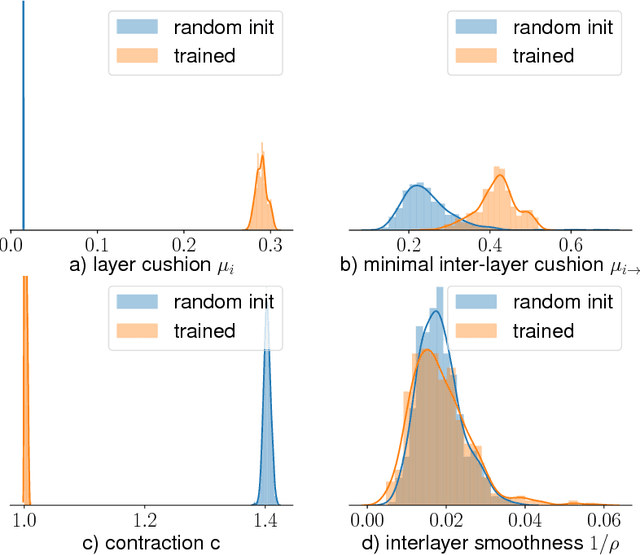
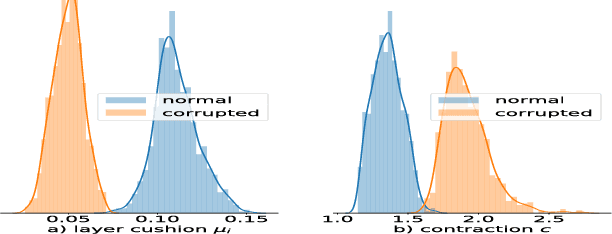
Deep nets generalize well despite having more parameters than the number of training samples. Recent works try to give an explanation using PAC-Bayes and Margin-based analyses, but do not as yet result in sample complexity bounds better than naive parameter counting. The current paper shows generalization bounds that're orders of magnitude better in practice. These rely upon new succinct reparametrizations of the trained net --- a compression that is explicit and efficient. These yield generalization bounds via a simple compression-based framework introduced here. Our results also provide some theoretical justification for widespread empirical success in compressing deep nets. Analysis of correctness of our compression relies upon some newly identified \textquotedblleft noise stability\textquotedblright properties of trained deep nets, which are also experimentally verified. The study of these properties and resulting generalization bounds are also extended to convolutional nets, which had eluded earlier attempts on proving generalization.
Global Convergence of Policy Gradient Methods for the Linear Quadratic Regulator
Oct 21, 2018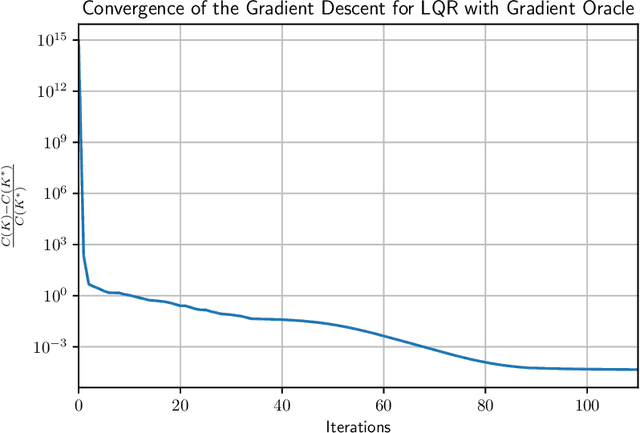
Direct policy gradient methods for reinforcement learning and continuous control problems are a popular approach for a variety of reasons: 1) they are easy to implement without explicit knowledge of the underlying model 2) they are an "end-to-end" approach, directly optimizing the performance metric of interest 3) they inherently allow for richly parameterized policies. A notable drawback is that even in the most basic continuous control problem (that of linear quadratic regulators), these methods must solve a non-convex optimization problem, where little is understood about their efficiency from both computational and statistical perspectives. In contrast, system identification and model based planning in optimal control theory have a much more solid theoretical footing, where much is known with regards to their computational and statistical properties. This work bridges this gap showing that (model free) policy gradient methods globally converge to the optimal solution and are efficient (polynomially so in relevant problem dependent quantities) with regards to their sample and computational complexities.
On the Local Minima of the Empirical Risk
Oct 17, 2018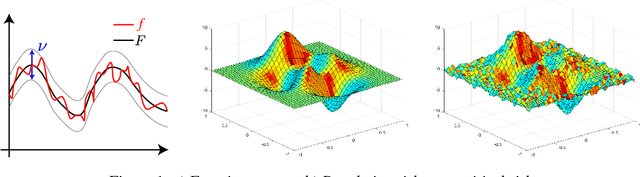
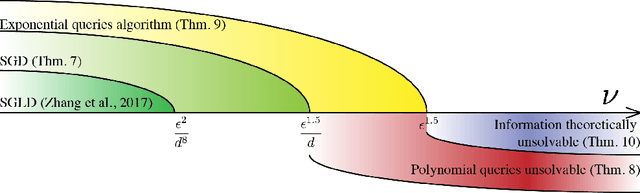
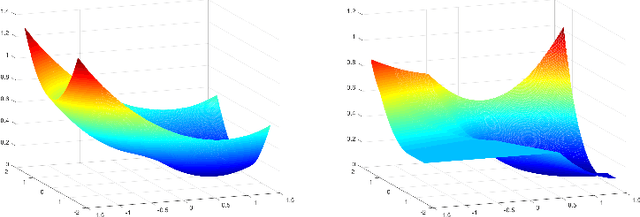
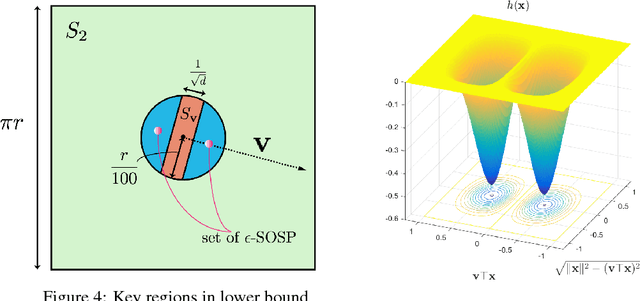
Population risk is always of primary interest in machine learning; however, learning algorithms only have access to the empirical risk. Even for applications with nonconvex nonsmooth losses (such as modern deep networks), the population risk is generally significantly more well-behaved from an optimization point of view than the empirical risk. In particular, sampling can create many spurious local minima. We consider a general framework which aims to optimize a smooth nonconvex function $F$ (population risk) given only access to an approximation $f$ (empirical risk) that is pointwise close to $F$ (i.e., $\|F-f\|_{\infty} \le \nu$). Our objective is to find the $\epsilon$-approximate local minima of the underlying function $F$ while avoiding the shallow local minima---arising because of the tolerance $\nu$---which exist only in $f$. We propose a simple algorithm based on stochastic gradient descent (SGD) on a smoothed version of $f$ that is guaranteed to achieve our goal as long as $\nu \le O(\epsilon^{1.5}/d)$. We also provide an almost matching lower bound showing that our algorithm achieves optimal error tolerance $\nu$ among all algorithms making a polynomial number of queries of $f$. As a concrete example, we show that our results can be directly used to give sample complexities for learning a ReLU unit.