 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovaCOMET: Open Commonsense Foundation Models with Symbolic Knowledge Distillation
Dec 10, 2023



We present NovaCOMET, an open commonsense knowledge model, that combines the best aspects of knowledge and general task models. Compared to previous knowledge models, NovaCOMET allows open-format relations enabling direct application to reasoning tasks; compared to general task models like Flan-T5, it explicitly centers knowledge, enabling superior performance for commonsense reasoning. NovaCOMET leverages the knowledge of opaque proprietary models to create an open knowledge pipeline. First, knowledge is symbolically distilled into NovATOMIC, a publicly-released discrete knowledge graph which can be audited, critiqued, and filtered. Next, we train NovaCOMET on NovATOMIC by fine-tuning an open-source pretrained model. NovaCOMET uses an open-format training objective, replacing the fixed relation sets of past knowledge models, enabling arbitrary structures within the data to serve as inputs or outputs. The resulting generation model, optionally augmented with human annotation, matches or exceeds comparable open task models like Flan-T5 on a range of commonsense generation tasks. NovaCOMET serves as a counterexample to the contemporary focus on instruction tuning only, demonstrating a distinct advantage to explicitly modeling commonsense knowledge as well.
MacGyver: Are Large Language Models Creative Problem Solvers?
Nov 16, 2023



We explore the creative problem-solving capabilities of modern large language models (LLMs) in a constrained setting. The setting requires circumventing a cognitive bias known in psychology as ''functional fixedness'' to use familiar objects in innovative or unconventional ways. To this end, we create MacGyver, an automatically generated dataset consisting of 1,600 real-world problems that deliberately trigger functional fixedness and require thinking 'out-of-the-box'. We then present our collection of problems to both LLMs and humans to compare and contrast their problem-solving abilities. We show that MacGyver is challenging for both groups, but in unique and complementary ways. For example, humans typically excel in solving problems that they are familiar with but may struggle with tasks requiring domain-specific knowledge, leading to a higher variance. On the other hand, LLMs, being exposed to a variety of highly specialized knowledge, attempt broader problems but are prone to overconfidence and propose actions that are physically infeasible or inefficient. We also provide a detailed error analysis of LLMs, and demonstrate the potential of enhancing their problem-solving ability with novel prompting techniques such as iterative step-wise reflection and divergent-convergent thinking. This work provides insight into the creative problem-solving capabilities of humans and AI and illustrates how psychological paradigms can be extended into large-scale tasks for comparing humans and machines.
FANToM: A Benchmark for Stress-testing Machine Theory of Mind in Interactions
Oct 31, 2023Theory of mind (ToM) evaluations currently focus on testing models using passive narratives that inherently lack interactivity. We introduce FANToM, a new benchmark designed to stress-test ToM within information-asymmetric conversational contexts via question answering. Our benchmark draws upon important theoretical requisites from psychology and necessary empirical considerations when evaluating large language models (LLMs). In particular, we formulate multiple types of questions that demand the same underlying reasoning to identify illusory or false sense of ToM capabilities in LLMs. We show that FANToM is challenging for state-of-the-art LLMs, which perform significantly worse than humans even with chain-of-thought reasoning or fine-tuning.
Commonsense Knowledge Transfer for Pre-trained Language Models
Jun 04, 2023Despite serving as the foundation models for a wide range of NLP benchmarks, pre-trained language models have shown limited capabilities of acquiring implicit commonsense knowledge from self-supervision alone, compared to learning linguistic and factual knowledge that appear more explicitly in the surface patterns in text. In this work, we introduce commonsense knowledge transfer, a framework to transfer the commonsense knowledge stored in a neural commonsense knowledge model to a general-purpose pre-trained language model. It first exploits general texts to form queries for extracting commonsense knowledge from the neural commonsense knowledge model and then refines the language model with two self-supervised objectives: commonsense mask infilling and commonsense relation prediction, which align human language with the underlying commonsense knowledge. Empirical results show that our approach consistently improves the model's performance on downstream tasks that require commonsense reasoning. Moreover, we find that the improvement is more significant in the few-shot setting. This suggests that our approach helps language models better transfer to downstream tasks without extensive supervision by injecting commonsense knowledge into their parameters.
Modular Transformers: Compressing Transformers into Modularized Layers for Flexible Efficient Inference
Jun 04, 2023



Pre-trained Transformer models like T5 and BART have advanced the state of the art on a wide range of text generation tasks. Compressing these models into smaller ones has become critically important for practical use. Common neural network compression techniques such as knowledge distillation or quantization are limited to static compression where the compression ratio is fixed. In this paper, we introduce Modular Transformers, a modularized encoder-decoder framework for flexible sequence-to-sequence model compression. Modular Transformers train modularized layers that have the same function of two or more consecutive layers in the original model via module replacing and knowledge distillation. After training, the modularized layers can be flexibly assembled into sequence-to-sequence models that meet different performance-efficiency trade-offs. Experimental results show that after a single training phase, by simply varying the assembling strategy, Modular Transformers can achieve flexible compression ratios from 1.1x to 6x with little to moderate relative performance drop.
NLPositionality: Characterizing Design Biases of Datasets and Models
Jun 02, 2023



Design biases in NLP systems, such as performance differences for different populations, often stem from their creator's positionality, i.e., views and lived experiences shaped by identity and background. Despite the prevalence and risks of design biases, they are hard to quantify because researcher, system, and dataset positionality is often unobserved. We introduce NLPositionality, a framework for characterizing design biases and quantifying the positionality of NLP datasets and models. Our framework continuously collects annotations from a diverse pool of volunteer participants on LabintheWild, and statistically quantifies alignment with dataset labels and model predictions. We apply NLPositionality to existing datasets and models for two tasks -- social acceptability and hate speech detection. To date, we have collected 16,299 annotations in over a year for 600 instances from 1,096 annotators across 87 countries. We find that datasets and models align predominantly with Western, White, college-educated, and younger populations. Additionally, certain groups, such as non-binary people and non-native English speakers, are further marginalized by datasets and models as they rank least in alignment across all tasks. Finally, we draw from prior literature to discuss how researchers can examine their own positionality and that of their datasets and models, opening the door for more inclusive NLP systems.
Faith and Fate: Limits of Transformers on Compositionality
Jun 01, 2023



Transformer large language models (LLMs) have sparked admiration for their exceptional performance on tasks that demand intricate multi-step reasoning. Yet, these models simultaneously show failures on surprisingly trivial problems. This begs the question: Are these errors incidental, or do they signal more substantial limitations? In an attempt to demystify Transformers, we investigate the limits of these models across three representative compositional tasks -- multi-digit multiplication, logic grid puzzles, and a classic dynamic programming problem. These tasks require breaking problems down into sub-steps and synthesizing these steps into a precise answer. We formulate compositional tasks as computation graphs to systematically quantify the level of complexity, and break down reasoning steps into intermediate sub-procedures. Our empirical findings suggest that Transformers solve compositional tasks by reducing multi-step compositional reasoning into linearized subgraph matching, without necessarily developing systematic problem-solving skills. To round off our empirical study, we provide theoretical arguments on abstract multi-step reasoning problems that highlight how Transformers' performance will rapidly decay with increased task complexity.
From Dogwhistles to Bullhorns: Unveiling Coded Rhetoric with Language Models
May 26, 2023Dogwhistles are coded expressions that simultaneously convey one meaning to a broad audience and a second one, often hateful or provocative, to a narrow in-group; they are deployed to evade both political repercussions and algorithmic content moderation. For example, in the sentence 'we need to end the cosmopolitan experiment,' the word 'cosmopolitan' likely means 'worldly' to many, but secretly means 'Jewish' to a select few. We present the first large-scale computational investigation of dogwhistles. We develop a typology of dogwhistles, curate the largest-to-date glossary of over 300 dogwhistles with rich contextual information and examples, and analyze their usage in historical U.S. politicians' speeches. We then assess whether a large language model (GPT-3) can identify dogwhistles and their meanings, and find that GPT-3's performance varies widely across types of dogwhistles and targeted groups. Finally, we show that harmful content containing dogwhistles avoids toxicity detection, highlighting online risks of such coded language. This work sheds light on the theoretical and applied importance of dogwhistles in both NLP and computational social science, and provides resources for future research in modeling dogwhistles and mitigating their online harms.
Improving Language Models with Advantage-based Offline Policy Gradients
May 24, 2023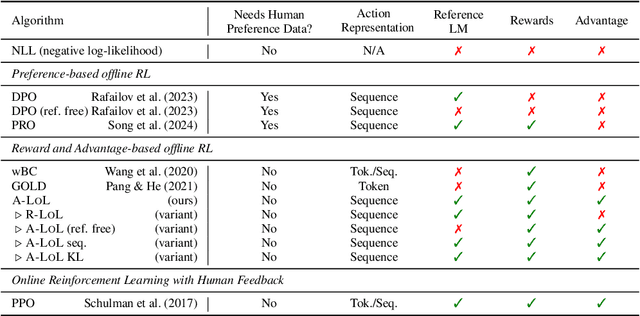
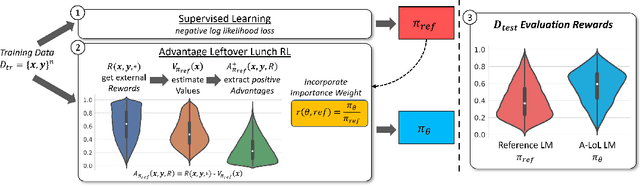
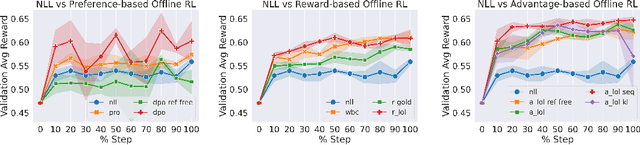

Improving language model generations according to some user-defined quality or style constraints is challenging. Typical approaches include learning on additional human-written data, filtering ``low-quality'' data using heuristics and/or using reinforcement learning with human feedback (RLHF). However, filtering can remove valuable training signals, whereas data collection and RLHF constantly require additional human-written or LM exploration data which can be costly to obtain. A natural question to ask is ``Can we leverage RL to optimize LM utility on existing crowd-sourced and internet data?'' To this end, we present Left-over Lunch RL (LoL-RL), a simple training algorithm that uses offline policy gradients for learning language generation tasks as a 1-step RL game. LoL-RL can finetune LMs to optimize arbitrary classifier-based or human-defined utility functions on any sequence-to-sequence data. Experiments with five different language generation tasks using models of varying sizes and multiple rewards show that models trained with LoL-RL can consistently outperform the best supervised learning models. We also release our experimental code. https://github.com/abaheti95/LoL-RL
SODA: Million-scale Dialogue Distillation with Social Commonsense Contextualization
Dec 20, 2022



We present SODA: the first publicly available, million-scale high-quality social dialogue dataset. Using SODA, we train COSMO: a generalizable conversation agent outperforming previous best-performing agents on both in- and out-of-domain datasets. In contrast to most existing crowdsourced, small-scale dialogue corpora, we distill 1.5M socially-grounded dialogues from a pre-trained language model (InstructGPT; Ouyang et al., 2022). Dialogues are distilled by contextualizing social commonsense knowledge from a knowledge graph (Atomic10x; West et al., 2022). Human evaluation shows that dialogues in SODA are more consistent, specific, and (surprisingly) natural than prior human-authored datasets - e.g., DailyDialog (Li et al., 2017), BlendedSkillTalk (Smith et al., 2020). In addition, extensive evaluations show that COSMO is significantly more natural and consistent on unseen datasets than best-performing dialogue models - e.g., GODEL (Peng et al., 2022), BlenderBot (Roller et al., 2021), DialoGPT (Zhang et al., 2020). Furthermore, it is sometimes even preferred to the original human-written gold responses. We make our data, models, and code public.