 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWS-GRPO: Weakly-Supervised Group-Relative Policy Optimization for Rollout-Efficient Reasoning
Feb 19, 2026Group Relative Policy Optimization (GRPO) is effective for training language models on complex reasoning. However, since the objective is defined relative to a group of sampled trajectories, extended deliberation can create more chances to realize relative gains, leading to inefficient reasoning and overthinking, and complicating the trade-off between correctness and rollout efficiency. Controlling this behavior is difficult in practice, considering (i) Length penalties are hard to calibrate because longer rollouts may reflect harder problems that require longer reasoning, penalizing tokens risks truncating useful reasoning along with redundant continuation; and (ii) supervision that directly indicates when to continue or stop is typically unavailable beyond final answer correctness. We propose Weakly Supervised GRPO (WS-GRPO), which improves rollout efficiency by converting terminal rewards into correctness-aware guidance over partial trajectories. Unlike global length penalties that are hard to calibrate, WS-GRPO trains a preference model from outcome-only correctness to produce prefix-level signals that indicate when additional continuation is beneficial. Thus, WS-GRPO supplies outcome-derived continue/stop guidance, reducing redundant deliberation while maintaining accuracy. We provide theoretical results and empirically show on reasoning benchmarks that WS-GRPO substantially reduces rollout length while remaining competitive with GRPO baselines.
SceneAlign: Aligning Multimodal Reasoning to Scene Graphs in Complex Visual Scenes
Jan 09, 2026Multimodal large language models often struggle with faithful reasoning in complex visual scenes, where intricate entities and relations require precise visual grounding at each step. This reasoning unfaithfulness frequently manifests as hallucinated entities, mis-grounded relations, skipped steps, and over-specified reasoning. Existing preference-based approaches, typically relying on textual perturbations or answer-conditioned rationales, fail to address this challenge as they allow models to exploit language priors to bypass visual grounding. To address this, we propose SceneAlign, a framework that leverages scene graphs as structured visual information to perform controllable structural interventions. By identifying reasoning-critical nodes and perturbing them through four targeted strategies that mimic typical grounding failures, SceneAlign constructs hard negative rationales that remain linguistically plausible but are grounded in inaccurate visual facts. These contrastive pairs are used in Direct Preference Optimization to steer models toward fine-grained, structure-faithful reasoning. Across seven visual reasoning benchmarks, SceneAlign consistently improves answer accuracy and reasoning faithfulness, highlighting the effectiveness of grounding-aware alignment for multimodal reasoning.
Realistic CDSS Drug Dosing with End-to-end Recurrent Q-learning for Dual Vasopressor Control
Oct 01, 2025Reinforcement learning (RL) applications in Clinical Decision Support Systems (CDSS) frequently encounter skepticism from practitioners regarding inoperable dosing decisions. We address this challenge with an end-to-end approach for learning optimal drug dosing and control policies for dual vasopressor administration in intensive care unit (ICU) patients with septic shock. For realistic drug dosing, we apply action space design that accommodates discrete, continuous, and directional dosing strategies in a system that combines offline conservative Q-learning with a novel recurrent modeling in a replay buffer to capture temporal dependencies in ICU time-series data. Our comparative analysis of norepinephrine dosing strategies across different action space formulations reveals that the designed action spaces improve interpretability and facilitate clinical adoption while preserving efficacy. Empirical results1 on eICU and MIMIC demonstrate that action space design profoundly influences learned behavioral policies. The proposed methods achieve improved patient outcomes of over 15% in survival improvement probability, while aligning with established clinical protocols.
In-Context Algorithm Emulation in Fixed-Weight Transformers
Aug 24, 2025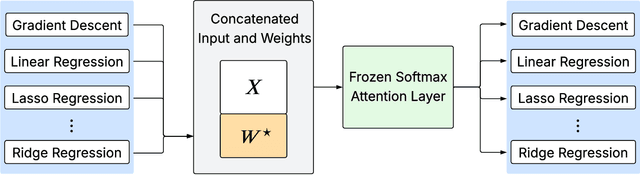
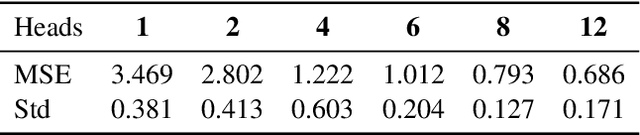
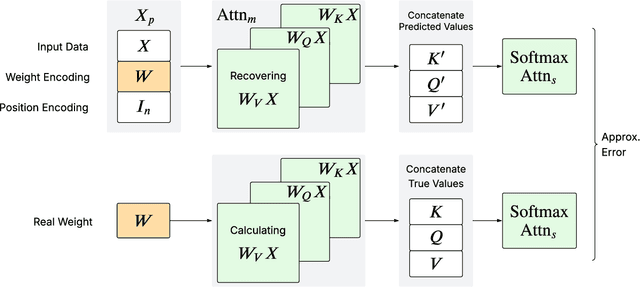

We prove that a minimal Transformer architecture with frozen weights is capable of emulating a broad class of algorithms by in-context prompting. In particular, for any algorithm implementable by a fixed-weight attention head (e.g. one-step gradient descent or linear/ridge regression), there exists a prompt that drives a two-layer softmax attention module to reproduce the algorithm's output with arbitrary precision. This guarantee extends even to a single-head attention layer (using longer prompts if necessary), achieving architectural minimality. Our key idea is to construct prompts that encode an algorithm's parameters into token representations, creating sharp dot-product gaps that force the softmax attention to follow the intended computation. This construction requires no feed-forward layers and no parameter updates. All adaptation happens through the prompt alone. These findings forge a direct link between in-context learning and algorithmic emulation, and offer a simple mechanism for large Transformers to serve as prompt-programmable libraries of algorithms. They illuminate how GPT-style foundation models may swap algorithms via prompts alone, establishing a form of algorithmic universality in modern Transformer models.