 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiLM-Based Speaker Conditioning of a SpeechLLM for Pathological Speech Recognition
Jun 04, 2026Automatic speech recognition (ASR) has advanced remarkably for standard speech; however, pathological speech from neurological conditions remains a significant challenge. We investigate speaker conditioning via Feature-wise Linear Modulation (FiLM), injecting x-vector-derived information into each transformer layer of a frozen ASR encoder to adapt internal representations to individual pathological speakers without modifying base model weights. We benchmark this for the ASR task against standard and parameter-efficient fine-tuning baselines, complemented by post-processing, on Spanish and English pathological speech. Additionally, we evaluate if the adapted model preserves the ability to answer speech-related questions. Results show that speaker-conditioned ASR is competitive with established adaptation strategies while retaining performance on non-conditioned speech.
"OK Aura, Be Fair With Me": Demographics-Agnostic Training for Bias Mitigation in Wake-up Word Detection
Apr 07, 2026Voice-based interfaces are widely used; however, achieving fair Wake-up Word detection across diverse speaker populations remains a critical challenge due to persistent demographic biases. This study evaluates the effectiveness of demographics-agnostic training techniques in mitigating performance disparities among speakers of varying sex, age, and accent. We utilize the OK Aura database for our experiments, employing a training methodology that excludes demographic labels, which are reserved for evaluation purposes. We explore (i) data augmentation techniques to enhance model generalization and (ii) knowledge distillation of pre-trained foundational speech models. The experimental results indicate that these demographics-agnostic training techniques markedly reduce demographic bias, leading to a more equitable performance profile across different speaker groups. Specifically, one of the evaluated techniques achieves a Predictive Disparity reduction of 39.94\% for sex, 83.65\% for age, and 40.48\% for accent when compared to the baseline. This study highlights the effectiveness of label-agnostic methodologies in fostering fairness in Wake-up Word detection.
Optimizing Multilingual LLMs via Federated Learning: A Study of Client Language Composition
Mar 25, 2026Federated Learning (FL) of Large Language Models (LLMs) in multilingual environments presents significant challenges stemming from heterogeneous language distributions across clients and disparities in language resource availability. To address these challenges, we extended the FederatedScope-LLM framework to support multilingual instruction-tuning experiments with LLMs. We also introduced a novel client-specific early stopping mechanism, Local Dynamic Early Stopping (LDES-FL), which allows clients to pause and resume local training based on client-side validation performance, enhancing training efficiency and sustainability. Through a series of experiments, we studied how client language composition - from fully monolingual to increasingly multilingual clients - affects multilingual quality, fairness and training cost. Monolingual local fine-tuning remains the most effective for single-language specialization, whereas federated training is better suited to learning a single balanced multilingual model. In FL, increasing within-client multilinguality leads to stronger and fairer global models, narrows the gap to centralized multilingual fine-tuning, and yields the largest gains for lower-resource languages, albeit at the cost of more optimization steps. Overall, our results identify client language composition as a key design variable in multilingual FL, shaping performance, fairness and efficiency
Robustness assessment of large audio language models in multiple-choice evaluation
Oct 06, 2025



Recent advances in large audio language models (LALMs) have primarily been assessed using a multiple-choice question answering (MCQA) framework. However, subtle changes, such as shifting the order of choices, result in substantially different results. Existing MCQA frameworks do not account for this variability and report a single accuracy number per benchmark or category. We dive into the MCQA evaluation framework and conduct a systematic study spanning three benchmarks (MMAU, MMAR and MMSU) and four models: Audio Flamingo 2, Audio Flamingo 3, Qwen2.5-Omni-7B-Instruct, and Kimi-Audio-7B-Instruct. Our findings indicate that models are sensitive not only to the ordering of choices, but also to the paraphrasing of the question and the choices. Finally, we propose a simpler evaluation protocol and metric that account for subtle variations and provide a more detailed evaluation report of LALMs within the MCQA framework.
Word Sense Disambiguation in Native Spanish: A Comprehensive Lexical Evaluation Resource
Sep 30, 2024



Human language, while aimed at conveying meaning, inherently carries ambiguity. It poses challenges for speech and language processing, but also serves crucial communicative functions. Efficiently solve ambiguity is both a desired and a necessary characteristic. The lexical meaning of a word in context can be determined automatically by Word Sense Disambiguation (WSD) algorithms that rely on external knowledge often limited and biased toward English. When adapting content to other languages, automated translations are frequently inaccurate and a high degree of expert human validation is necessary to ensure both accuracy and understanding. The current study addresses previous limitations by introducing a new resource for Spanish WSD. It includes a sense inventory and a lexical dataset sourced from the Diccionario de la Lengua Espa\~nola which is maintained by the Real Academia Espa\~nola. We also review current resources for Spanish and report metrics on them by a state-of-the-art system.
Robust Wake-Up Word Detection by Two-stage Multi-resolution Ensembles
Oct 17, 2023



Voice-based interfaces rely on a wake-up word mechanism to initiate communication with devices. However, achieving a robust, energy-efficient, and fast detection remains a challenge. This paper addresses these real production needs by enhancing data with temporal alignments and using detection based on two phases with multi-resolution. It employs two models: a lightweight on-device model for real-time processing of the audio stream and a verification model on the server-side, which is an ensemble of heterogeneous architectures that refine detection. This scheme allows the optimization of two operating points. To protect privacy, audio features are sent to the cloud instead of raw audio. The study investigated different parametric configurations for feature extraction to select one for on-device detection and another for the verification model. Furthermore, thirteen different audio classifiers were compared in terms of performance and inference time. The proposed ensemble outperforms our stronger classifier in every noise condition.
Scheduling Inference Workloads on Distributed Edge Clusters with Reinforcement Learning
Jan 31, 2023



Many real-time applications (e.g., Augmented/Virtual Reality, cognitive assistance) rely on Deep Neural Networks (DNNs) to process inference tasks. Edge computing is considered a key infrastructure to deploy such applications, as moving computation close to the data sources enables us to meet stringent latency and throughput requirements. However, the constrained nature of edge networks poses several additional challenges to the management of inference workloads: edge clusters can not provide unlimited processing power to DNN models, and often a trade-off between network and processing time should be considered when it comes to end-to-end delay requirements. In this paper, we focus on the problem of scheduling inference queries on DNN models in edge networks at short timescales (i.e., few milliseconds). By means of simulations, we analyze several policies in the realistic network settings and workloads of a large ISP, highlighting the need for a dynamic scheduling policy that can adapt to network conditions and workloads. We therefore design ASET, a Reinforcement Learning based scheduling algorithm able to adapt its decisions according to the system conditions. Our results show that ASET effectively provides the best performance compared to static policies when scheduling over a distributed pool of edge resources.
Iterative pseudo-forced alignment by acoustic CTC loss for self-supervised ASR domain adaptation
Oct 27, 2022



High-quality data labeling from specific domains is costly and human time-consuming. In this work, we propose a self-supervised domain adaptation method, based upon an iterative pseudo-forced alignment algorithm. The produced alignments are employed to customize an end-to-end Automatic Speech Recognition (ASR) and iteratively refined. The algorithm is fed with frame-wise character posteriors produced by a seed ASR, trained with out-of-domain data, and optimized throughout a Connectionist Temporal Classification (CTC) loss. The alignments are computed iteratively upon a corpus of broadcast TV. The process is repeated by reducing the quantity of text to be aligned or expanding the alignment window until finding the best possible audio-text alignment. The starting timestamps, or temporal anchors, are produced uniquely based on the confidence score of the last aligned utterance. This score is computed with the paths of the CTC-alignment matrix. With this methodology, no human-revised text references are required. Alignments from long audio files with low-quality transcriptions, like TV captions, are filtered out by confidence score and ready for further ASR adaptation. The obtained results, on both the Spanish RTVE2022 and CommonVoice databases, underpin the feasibility of using CTC-based systems to perform: highly accurate audio-text alignments, domain adaptation and semi-supervised training of end-to-end ASR.
Data Augmentation for Low-Resource Quechua ASR Improvement
Jul 14, 2022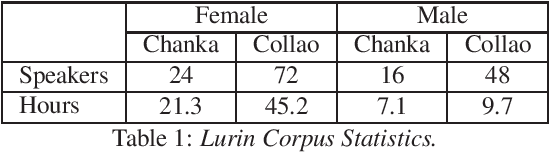
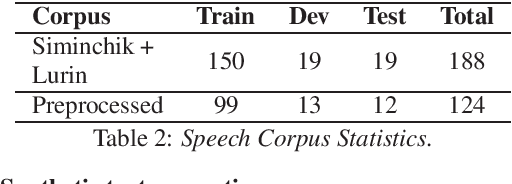
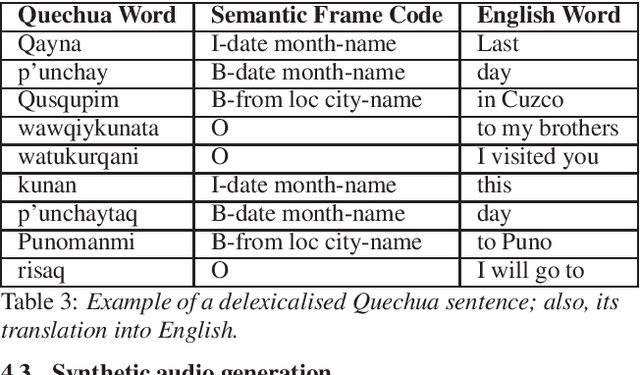
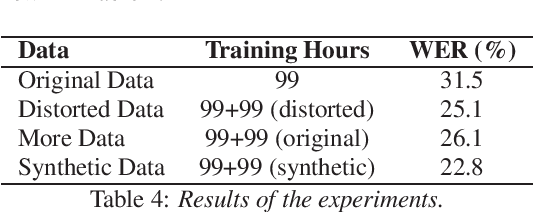
Automatic Speech Recognition (ASR) is a key element in new services that helps users to interact with an automated system. Deep learning methods have made it possible to deploy systems with word error rates below 5% for ASR of English. However, the use of these methods is only available for languages with hundreds or thousands of hours of audio and their corresponding transcriptions. For the so-called low-resource languages to speed up the availability of resources that can improve the performance of their ASR systems, methods of creating new resources on the basis of existing ones are being investigated. In this paper we describe our data augmentation approach to improve the results of ASR models for low-resource and agglutinative languages. We carry out experiments developing an ASR for Quechua using the wav2letter++ model. We reduced WER by 8.73% through our approach to the base model. The resulting ASR model obtained 22.75% WER and was trained with 99 hours of original resources and 99 hours of synthetic data obtained with a combination of text augmentation and synthetic speech generati
Voice Quality and Pitch Features in Transformer-Based Speech Recognition
Dec 21, 2021
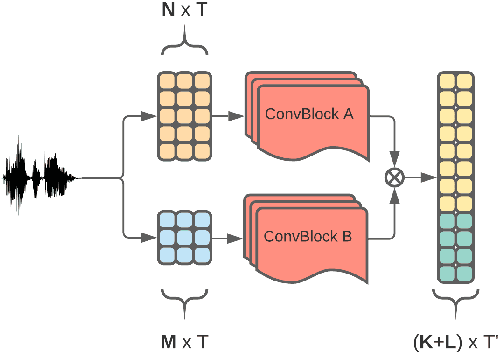
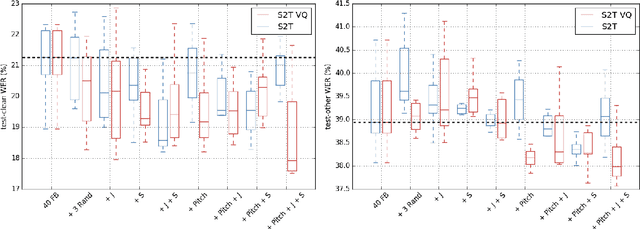
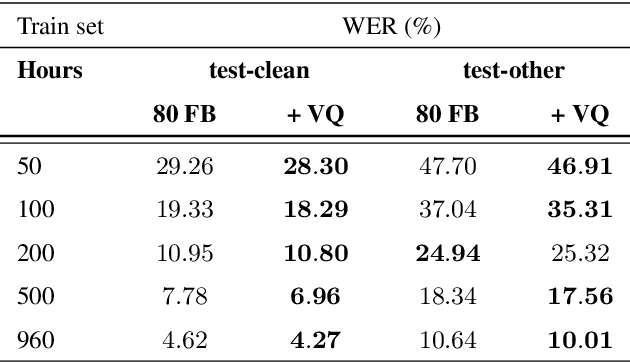
Jitter and shimmer measurements have shown to be carriers of voice quality and prosodic information which enhance the performance of tasks like speaker recognition, diarization or automatic speech recognition (ASR). However, such features have been seldom used in the context of neural-based ASR, where spectral features often prevail. In this work, we study the effects of incorporating voice quality and pitch features altogether and separately to a Transformer-based ASR model, with the intuition that the attention mechanisms might exploit latent prosodic traits. For doing so, we propose separated convolutional front-ends for prosodic and spectral features, showing that this architectural choice yields better results than simple concatenation of such pitch and voice quality features to mel-spectrogram filterbanks. Furthermore, we find mean Word Error Rate relative reductions of up to 5.6% with the LibriSpeech benchmark. Such findings motivate further research on the application of prosody knowledge for increasing the robustness of Transformer-based ASR.