 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-Resampler: Multi-Scope Visual Resampling for Efficient Multimodal LLMs
Jun 30, 2026Multimodal large language models (MLLMs) typically employ resampling-based projectors to transform dense visual features into a compact token sequence for language modeling. Most existing resamplers adopt a single, fixed aggregation scope via global cross-attention, which can blur fine-grained local evidence and limit the ability to capture both local details and global context within a fixed token budget. In this work, we propose MS-Resampler, a multi-scope visual resampling framework for MLLMs. MS-Resampler instantiates multiple scope-specific resamplers by injecting explicit spatial scope priors into the resampling attention, enabling each branch to aggregate visual information at a particular granularity from local to global. The outputs of these scope-specific resamplers are then adaptively fused to produce the final visual representations for language modeling. Extensive experiments on ten public multimodal benchmarks show that MS-Resampler consistently improves visual understanding and multimodal reasoning over conventional single-scope resamplers, while introducing only minimal computational overhead.
SMoES: Soft Modality-Guided Expert Specialization in MoE-VLMs
Apr 27, 2026Mixture-of-Experts (MoE) has become a prevalent backbone for large vision-language models (VLMs), yet how modality-specific signals should guide expert routing remains under-explored. Existing routing strategies are either hand-crafted or modality-agnostic, relying on idealized priors that ignore the layer-dependent modality fusion patterns in MoE-VLMs and provide little guidance for expert specialization. We propose Soft Modality-guided Expert Specialization (SMoES), which consists of dynamic soft modality scores that capture layer-dependent fusion patterns, an expert binning mechanism aligned with expert-parallel deployment, and an inter-bin mutual information regularization that encourages coherent modality specialization. Our method leverages attention-based or Gaussian-statistics modality scores to optimize mutual information regularization. Experiments across four MoE-based VLMs and 16 benchmarks demonstrate improvement on both effectiveness and efficiency: 0.9% and 4.2% average gain on multimodal and language-only tasks, 56.1% reduction in EP communication overhead, and 12.3% throughput improvement under realistic deployment. These results validate that aligning routing with modality-aware expert specialization unlocks MoE-VLM capacity and efficiency.
LearnPruner: Rethinking Attention-based Token Pruning in Vision Language Models
Apr 27, 2026Vision-Language Models (VLMs) have recently demonstrated remarkable capabilities in visual understanding and reasoning, but they also impose significant computational burdens due to long visual sequence inputs. Recent works address this issue by pruning unimportant visual tokens, achieving substantial computational reduction while maintaining model performance. The core of token pruning lies in determining token importance, with current approaches primarily relying on attention scores from vision encoders or Large Language Models (LLMs). In this paper, we analyze the effectiveness of attention mechanisms in both vision encoders and LLMs. We find that vision encoders suffer from attention sink, leading to poor focus on informative foreground regions, while in LLMs, although prior studies have identified attention bias toward token positions, text-to-vision attention demonstrates resistance to this bias and enables effective pruning guidance in middle layers. Based on these observations, we propose LearnPruner, a two-stage token pruning framework that first removes redundant vision tokens via a learnable pruning module after the vision encoder, then retains only task-relevant tokens in the LLM's middle layer. Experimental results show that our LearnPruner can preserve approximately 95% of the original performance while using only 5.5% of vision tokens, and achieve 3.2$\times$ inference acceleration, demonstrating a superior accuracy-efficiency trade-off.
QMoP: Query Guided Mixture-of-Projector for Efficient Visual Token Compression
Mar 22, 2026Multimodal large language models suffer from severe computational and memory bottlenecks, as the number of visual tokens far exceeds that of textual tokens. While recent methods employ projector modules to align and compress visual tokens into text-aligned features, they typically depend on fixed heuristics that limit adaptability across diverse scenarios. In this paper, we first propose Query Guided Mixture-of-Projector (QMoP), a novel and flexible framework that adaptively compresses visual tokens via three collaborative branches: (1) a pooling-based branch for coarse-grained global semantics, (2) a resampler branch for extracting high-level semantic representations, and (3) a pruning-based branch for fine-grained token selection to preserve critical visual detail. To adaptively coordinate these branches, we introduce the Query Guided Router (QGR), which dynamically selects and weights the outputs from different branches based on both visual input and textual queries. A Mixture-of-Experts-style fusion mechanism is designed to aggregate the outputs, harnessing the strengths of each strategy while suppressing noise. To systematically evaluate the effects of Visual Token Compression, we also develop VTCBench, a dedicated benchmark for evaluating the information loss induced by visual token compression. Extensive experiments demonstrate that despite relying on fundamental compression modules, QMoP outperforms strong baselines and delivers significant savings in memory, computation, and inference time.
ITO: Images and Texts as One via Synergizing Multiple Alignment and Training-Time Fusion
Mar 04, 2026Image-text contrastive pretraining has become a dominant paradigm for visual representation learning, yet existing methods often yield representations that remain partially organized by modality. We propose ITO, a framework addressing this limitation through two synergistic mechanisms. Multimodal multiple alignment enriches supervision by mining diverse image-text correspondences, while a lightweight training-time multimodal fusion module enforces structured cross-modal interaction. Crucially, the fusion module is discarded at inference, preserving the efficiency of standard dual-encoder architectures. Extensive experiments show that ITO consistently outperforms strong baselines across classification, retrieval, and multimodal benchmarks. Our analysis reveals that while multiple alignment drives discriminative power, training-time fusion acts as a critical structural regularizer -- eliminating the modality gap and stabilizing training dynamics to prevent the early saturation often observed in aggressive contrastive learning.
iGVLM: Dynamic Instruction-Guided Vision Encoding for Question-Aware Multimodal Understanding
Mar 03, 2026Despite the success of Large Vision--Language Models (LVLMs), most existing architectures suffer from a representation bottleneck: they rely on static, instruction-agnostic vision encoders whose visual representations are utilized in an invariant manner across different textual tasks. This rigidity hinders fine-grained reasoning where task-specific visual cues are critical. To address this issue, we propose iGVLM, a general framework for instruction-guided visual modulation. iGVLM introduces a decoupled dual-branch architecture: a frozen representation branch that preserves task-agnostic visual representations learned during pre-training, and a dynamic conditioning branch that performs affine feature modulation via Adaptive Layer Normalization (AdaLN). This design enables a smooth transition from general-purpose perception to instruction-aware reasoning while maintaining the structural integrity and stability of pre-trained visual priors. Beyond standard benchmarks, we introduce MM4, a controlled diagnostic probe for quantifying logical consistency under multi-query, multi-instruction settings. Extensive results show that iGVLM consistently enhances instruction sensitivity across diverse language backbones, offering a plug-and-play paradigm for bridging passive perception and active reasoning.
Deep Active Learning for Computer Vision: Past and Future
Nov 27, 2022



As an important data selection schema, active learning emerges as the essential component when iterating an Artificial Intelligence (AI) model. It becomes even more critical given the dominance of deep neural network based models, which are composed of a large number of parameters and data hungry, in application. Despite its indispensable role for developing AI models, research on active learning is not as intensive as other research directions. In this paper, we present a review of active learning through deep active learning approaches from the following perspectives: 1) technical advancements in active learning, 2) applications of active learning in computer vision, 3) industrial systems leveraging or with potential to leverage active learning for data iteration, 4) current limitations and future research directions. We expect this paper to clarify the significance of active learning in a modern AI model manufacturing process and to bring additional research attention to active learning. By addressing data automation challenges and coping with automated machine learning systems, active learning will facilitate democratization of AI technologies by boosting model production at scale.
ALBench: A Framework for Evaluating Active Learning in Object Detection
Aug 10, 2022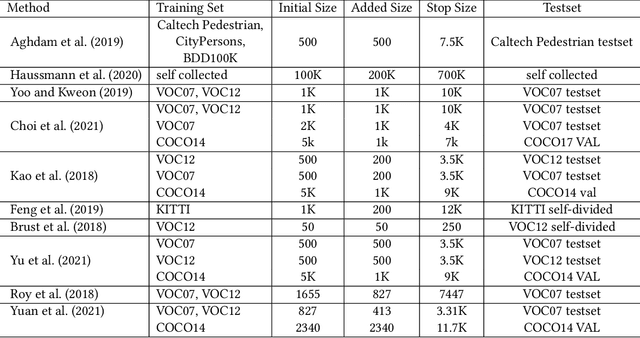
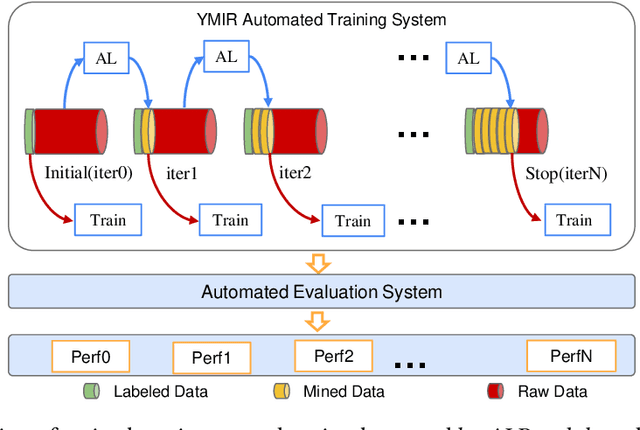
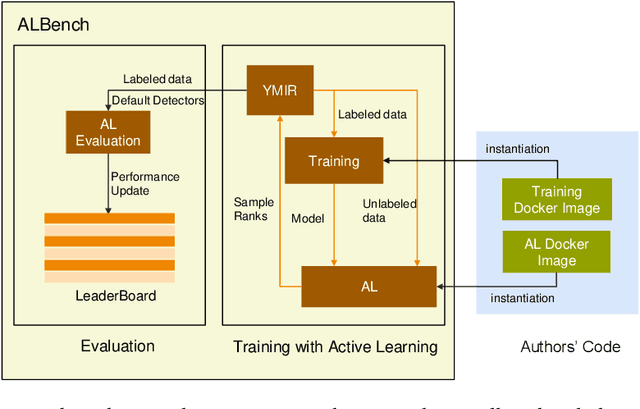
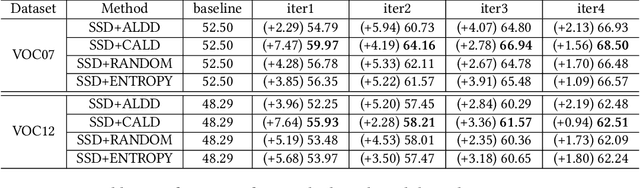
Active learning is an important technology for automated machine learning systems. In contrast to Neural Architecture Search (NAS) which aims at automating neural network architecture design, active learning aims at automating training data selection. It is especially critical for training a long-tailed task, in which positive samples are sparsely distributed. Active learning alleviates the expensive data annotation issue through incrementally training models powered with efficient data selection. Instead of annotating all unlabeled samples, it iteratively selects and annotates the most valuable samples. Active learning has been popular in image classification, but has not been fully explored in object detection. Most of current approaches on object detection are evaluated with different settings, making it difficult to fairly compare their performance. To facilitate the research in this field, this paper contributes an active learning benchmark framework named as ALBench for evaluating active learning in object detection. Developed on an automatic deep model training system, this ALBench framework is easy-to-use, compatible with different active learning algorithms, and ensures the same training and testing protocols. We hope this automated benchmark system help researchers to easily reproduce literature's performance and have objective comparisons with prior arts. The code will be release through Github.