 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnPruner: Rethinking Attention-based Token Pruning in Vision Language Models
Apr 27, 2026Vision-Language Models (VLMs) have recently demonstrated remarkable capabilities in visual understanding and reasoning, but they also impose significant computational burdens due to long visual sequence inputs. Recent works address this issue by pruning unimportant visual tokens, achieving substantial computational reduction while maintaining model performance. The core of token pruning lies in determining token importance, with current approaches primarily relying on attention scores from vision encoders or Large Language Models (LLMs). In this paper, we analyze the effectiveness of attention mechanisms in both vision encoders and LLMs. We find that vision encoders suffer from attention sink, leading to poor focus on informative foreground regions, while in LLMs, although prior studies have identified attention bias toward token positions, text-to-vision attention demonstrates resistance to this bias and enables effective pruning guidance in middle layers. Based on these observations, we propose LearnPruner, a two-stage token pruning framework that first removes redundant vision tokens via a learnable pruning module after the vision encoder, then retains only task-relevant tokens in the LLM's middle layer. Experimental results show that our LearnPruner can preserve approximately 95% of the original performance while using only 5.5% of vision tokens, and achieve 3.2$\times$ inference acceleration, demonstrating a superior accuracy-efficiency trade-off.
ITO: Images and Texts as One via Synergizing Multiple Alignment and Training-Time Fusion
Mar 04, 2026Image-text contrastive pretraining has become a dominant paradigm for visual representation learning, yet existing methods often yield representations that remain partially organized by modality. We propose ITO, a framework addressing this limitation through two synergistic mechanisms. Multimodal multiple alignment enriches supervision by mining diverse image-text correspondences, while a lightweight training-time multimodal fusion module enforces structured cross-modal interaction. Crucially, the fusion module is discarded at inference, preserving the efficiency of standard dual-encoder architectures. Extensive experiments show that ITO consistently outperforms strong baselines across classification, retrieval, and multimodal benchmarks. Our analysis reveals that while multiple alignment drives discriminative power, training-time fusion acts as a critical structural regularizer -- eliminating the modality gap and stabilizing training dynamics to prevent the early saturation often observed in aggressive contrastive learning.
iGVLM: Dynamic Instruction-Guided Vision Encoding for Question-Aware Multimodal Understanding
Mar 03, 2026Despite the success of Large Vision--Language Models (LVLMs), most existing architectures suffer from a representation bottleneck: they rely on static, instruction-agnostic vision encoders whose visual representations are utilized in an invariant manner across different textual tasks. This rigidity hinders fine-grained reasoning where task-specific visual cues are critical. To address this issue, we propose iGVLM, a general framework for instruction-guided visual modulation. iGVLM introduces a decoupled dual-branch architecture: a frozen representation branch that preserves task-agnostic visual representations learned during pre-training, and a dynamic conditioning branch that performs affine feature modulation via Adaptive Layer Normalization (AdaLN). This design enables a smooth transition from general-purpose perception to instruction-aware reasoning while maintaining the structural integrity and stability of pre-trained visual priors. Beyond standard benchmarks, we introduce MM4, a controlled diagnostic probe for quantifying logical consistency under multi-query, multi-instruction settings. Extensive results show that iGVLM consistently enhances instruction sensitivity across diverse language backbones, offering a plug-and-play paradigm for bridging passive perception and active reasoning.
DenseAttentionSeg: Segment Hands from Interacted Objects Using Depth Input
Apr 23, 2019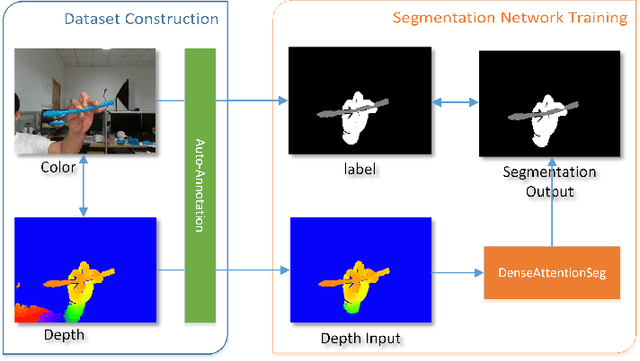

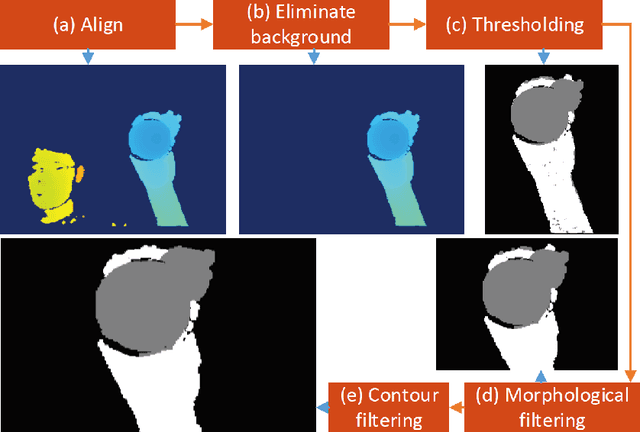
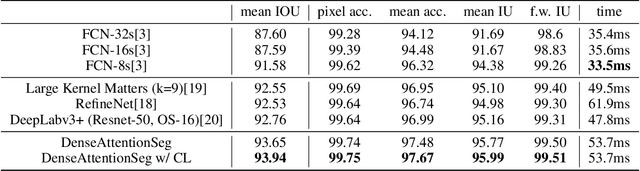
We propose a real-time DNN-based technique to segment hand and object of interacting motions from depth inputs. Our model is called DenseAttentionSeg, which contains a dense attention mechanism to fuse information in different scales and improves the results quality with skip-connections. Besides, we introduce a contour loss in model training, which helps to generate accurate hand and object boundaries. Finally, we propose and release our InterSegHands dataset, a fine-scale hand segmentation dataset containing about 52k depth maps of hand-object interactions. Our experiments evaluate the effectiveness of our techniques and datasets, and indicate that our method outperforms the current state-of-the-art deep segmentation methods on interaction segmentation.