 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Semi-Supervised VAE for Learning Disentangled Representations
Jun 22, 2020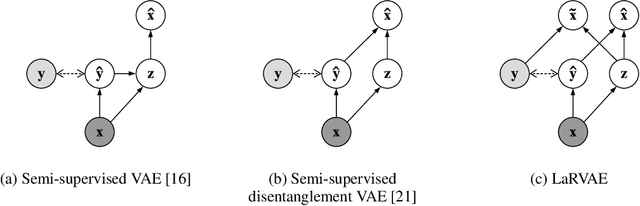
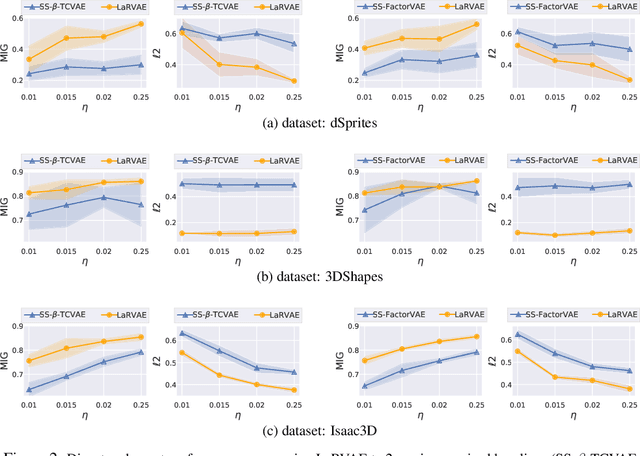
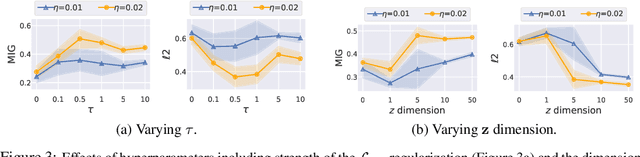
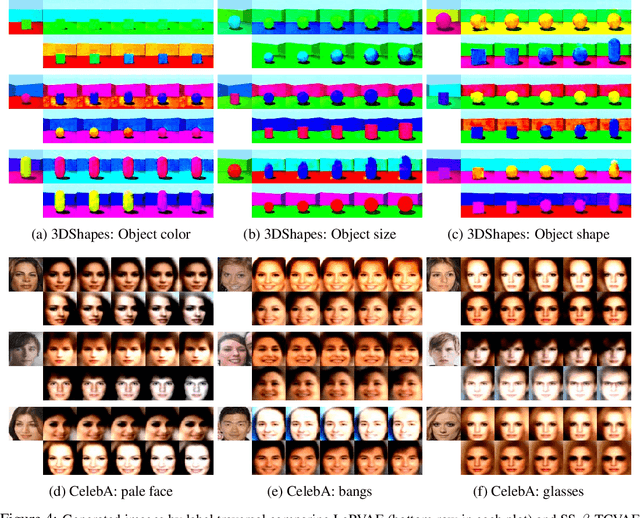
Learning interpretable and disentangled representations is a crucial yet challenging task in representation learning. In this work, we focus on semi-supervised disentanglement learning and extend work by Locatello et al. (2019) by introducing another source of supervision that we denote as label replacement. Specifically, during training, we replace the inferred representation associated with a data point with its ground-truth representation whenever it is available. Our extension is theoretically inspired by our proposed general framework of semi-supervised disentanglement learning in the context of VAEs which naturally motivates the supervised terms commonly used in existing semi-supervised VAEs (but not for disentanglement learning). Extensive experiments on synthetic and real datasets demonstrate both quantitatively and qualitatively the ability of our extension to significantly and consistently improve disentanglement with very limited supervision.
Analytical Probability Distributions and EM-Learning for Deep Generative Networks
Jun 17, 2020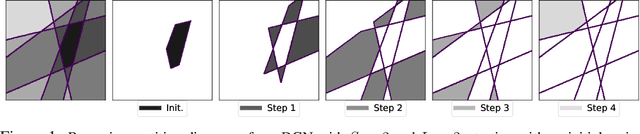

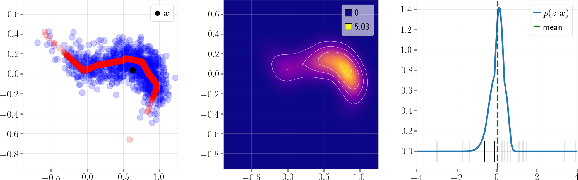
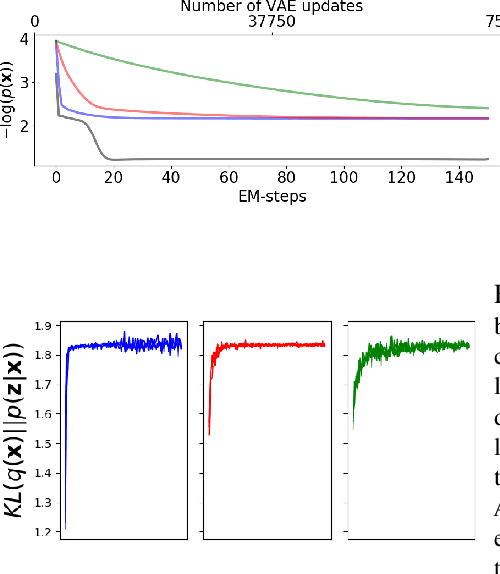
Deep Generative Networks (DGNs) with probabilistic modeling of their output and latent space are currently trained via Variational Autoencoders (VAEs). In the absence of a known analytical form for the posterior and likelihood expectation, VAEs resort to approximations, including (Amortized) Variational Inference (AVI) and Monte-Carlo (MC) sampling. We exploit the Continuous Piecewise Affine (CPA) property of modern DGNs to derive their posterior and marginal distributions as well as the latter's first moments. These findings enable us to derive an analytical Expectation-Maximization (EM) algorithm that enables gradient-free DGN learning. We demonstrate empirically that EM training of DGNs produces greater likelihood than VAE training. Our findings will guide the design of new VAE AVI that better approximate the true posterior and open avenues to apply standard statistical tools for model comparison, anomaly detection, and missing data imputation.
Interpretable Super-Resolution via a Learned Time-Series Representation
Jun 13, 2020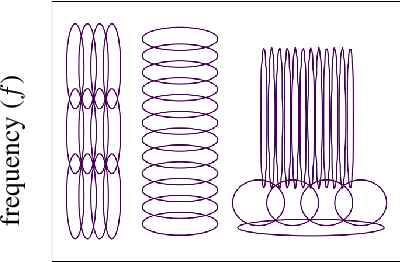
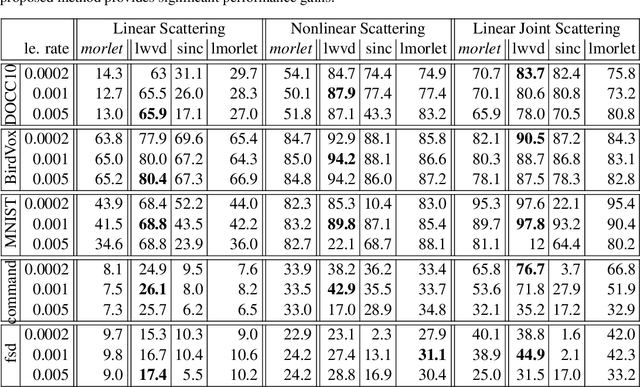
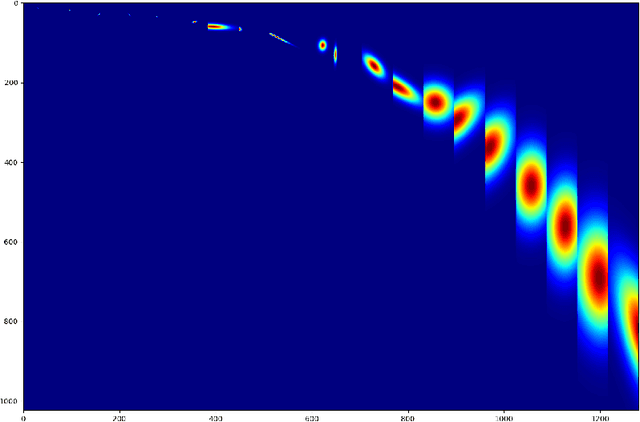

We develop an interpretable and learnable Wigner-Ville distribution that produces a super-resolved quadratic signal representation for time-series analysis. Our approach has two main hallmarks. First, it interpolates between known time-frequency representations (TFRs) in that it can reach super-resolution with increased time and frequency resolution beyond what the Heisenberg uncertainty principle prescribes and thus beyond commonly employed TFRs, Second, it is interpretable thanks to an explicit low-dimensional and physical parameterization of the Wigner-Ville distribution. We demonstrate that our approach is able to learn highly adapted TFRs and is ready and able to tackle various large-scale classification tasks, where we reach state-of-the-art performance compared to baseline and learned TFRs.
Double Double Descent: On Generalization Errors in Transfer Learning between Linear Regression Tasks
Jun 12, 2020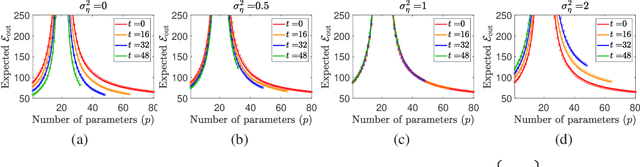
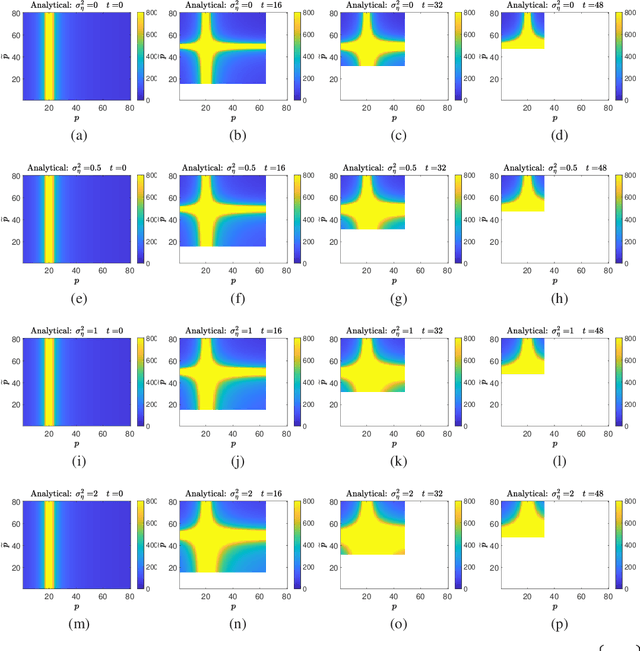
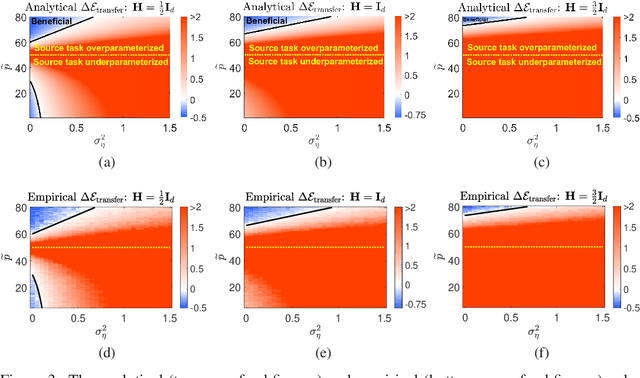
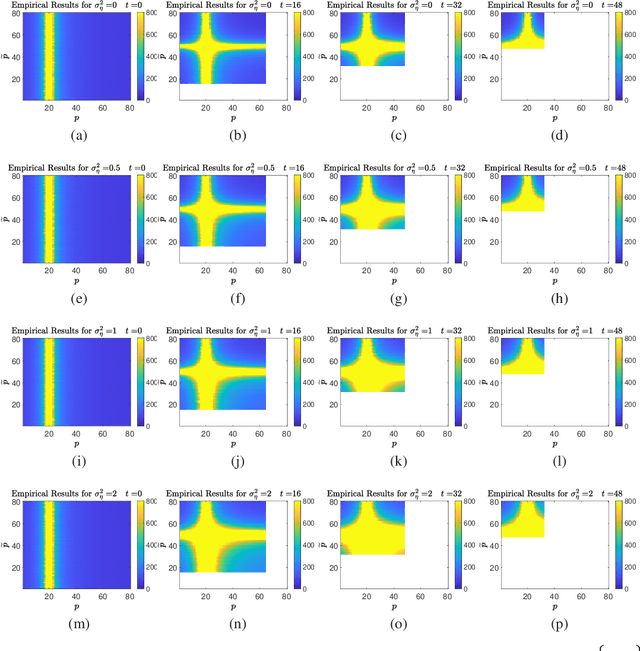
We study the transfer learning process between two linear regression problems. An important and timely special case is when the regressors are overparameterized and perfectly interpolate their training data. We examine a parameter transfer mechanism whereby a subset of the parameters of the target task solution are constrained to the values learned for a related source task. We analytically characterize the generalization error of the target task in terms of the salient factors in the transfer learning architecture, i.e., the number of examples available, the number of (free) parameters in each of the tasks, the number of parameters transferred from the source to target task, and the correlation between the two tasks. Our non-asymptotic analysis shows that the generalization error of the target task follows a two-dimensional double descent trend (with respect to the number of free parameters in each of the tasks) that is controlled by the transfer learning factors. Our analysis points to specific cases where the transfer of parameters is beneficial.
MomentumRNN: Integrating Momentum into Recurrent Neural Networks
Jun 12, 2020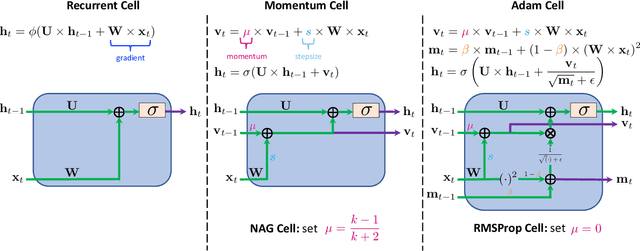
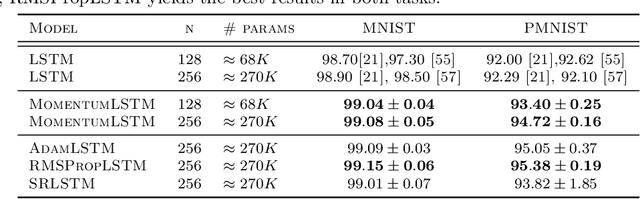
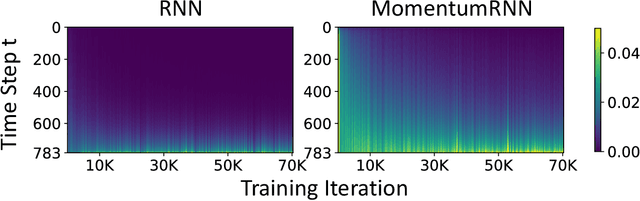
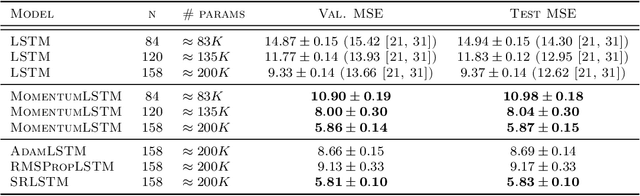
Designing deep neural networks is an art that often involves an expensive search over candidate architectures. To overcome this for recurrent neural nets (RNNs), we establish a connection between the hidden state dynamics in an RNN and gradient descent (GD). We then integrate momentum into this framework and propose a new family of RNNs, called {\em MomentumRNNs}. We theoretically prove and numerically demonstrate that MomentumRNNs alleviate the vanishing gradient issue in training RNNs. We study the momentum long-short term memory (MomentumLSTM) and verify its advantages in convergence speed and accuracy over its LSTM counterpart across a variety of benchmarks, with little compromise in computational or memory efficiency. We also demonstrate that MomentumRNN is applicable to many types of recurrent cells, including those in the state-of-the-art orthogonal RNNs. Finally, we show that other advanced momentum-based optimization methods, such as Adam and Nesterov accelerated gradients with a restart, can be easily incorporated into the MomentumRNN framework for designing new recurrent cells with even better performance. The code is available at \url{https://github.com/minhtannguyen/MomentumRNN}.
Attention Word Embedding
Jun 01, 2020
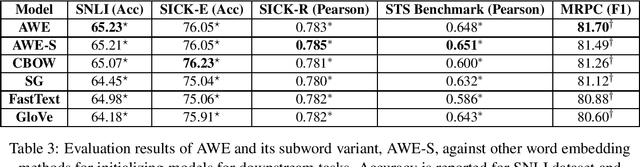
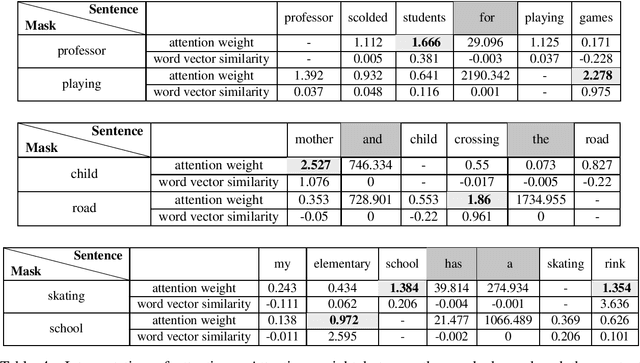
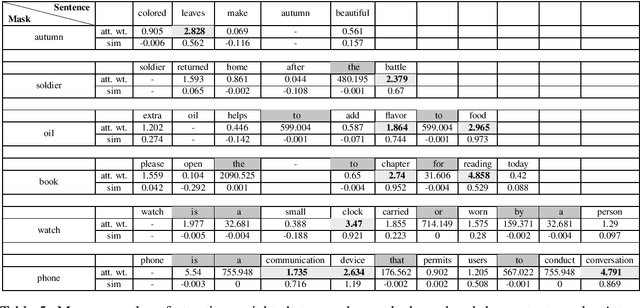
Word embedding models learn semantically rich vector representations of words and are widely used to initialize natural processing language (NLP) models. The popular continuous bag-of-words (CBOW) model of word2vec learns a vector embedding by masking a given word in a sentence and then using the other words as a context to predict it. A limitation of CBOW is that it equally weights the context words when making a prediction, which is inefficient, since some words have higher predictive value than others. We tackle this inefficiency by introducing the Attention Word Embedding (AWE) model, which integrates the attention mechanism into the CBOW model. We also propose AWE-S, which incorporates subword information. We demonstrate that AWE and AWE-S outperform the state-of-the-art word embedding models both on a variety of word similarity datasets and when used for initialization of NLP models.
qDKT: Question-centric Deep Knowledge Tracing
May 25, 2020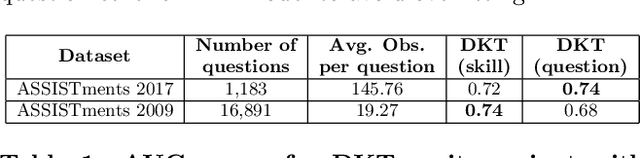
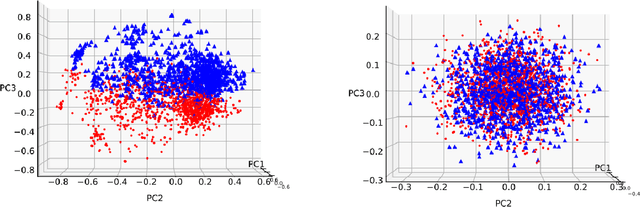

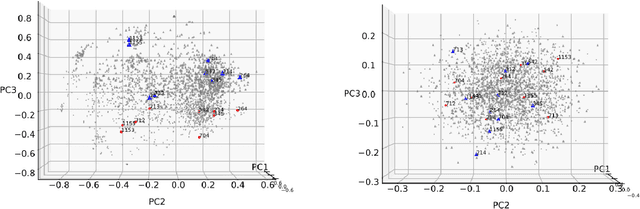
Knowledge tracing (KT) models, e.g., the deep knowledge tracing (DKT) model, track an individual learner's acquisition of skills over time by examining the learner's performance on questions related to those skills. A practical limitation in most existing KT models is that all questions nested under a particular skill are treated as equivalent observations of a learner's ability, which is an inaccurate assumption in real-world educational scenarios. To overcome this limitation we introduce qDKT, a variant of DKT that models every learner's success probability on individual questions over time. First, qDKT incorporates graph Laplacian regularization to smooth predictions under each skill, which is particularly useful when the number of questions in the dataset is big. Second, qDKT uses an initialization scheme inspired by the fastText algorithm, which has found success in a variety of language modeling tasks. Our experiments on several real-world datasets show that qDKT achieves state-of-art performance on predicting learner outcomes. Because of this, qDKT can serve as a simple, yet tough-to-beat, baseline for new question-centric KT models.
Deep Learning Techniques for Inverse Problems in Imaging
May 12, 2020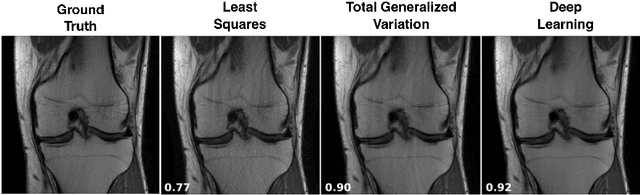
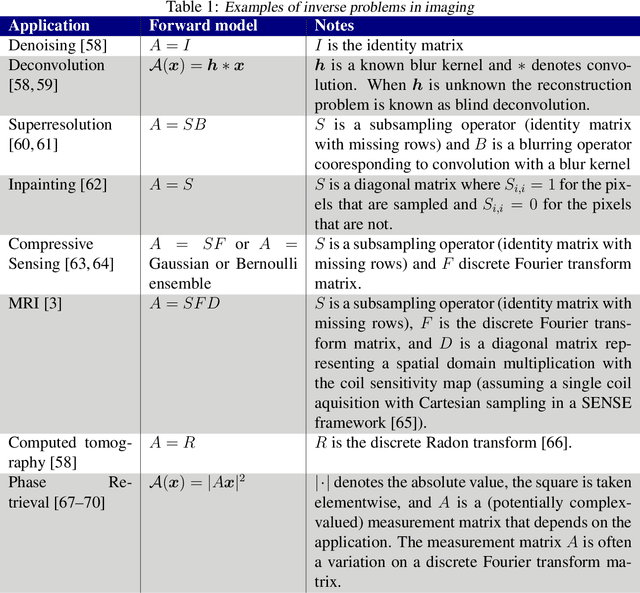

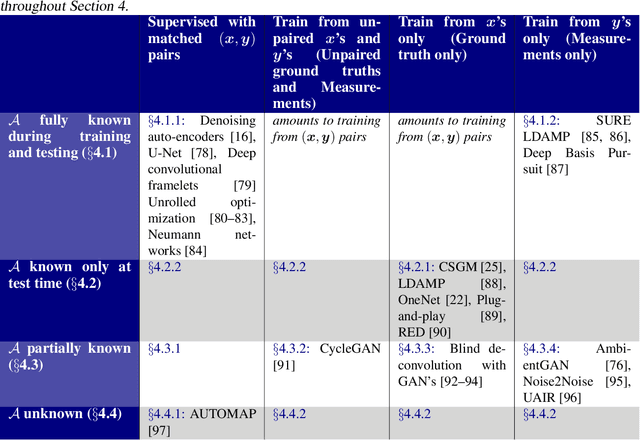
Recent work in machine learning shows that deep neural networks can be used to solve a wide variety of inverse problems arising in computational imaging. We explore the central prevailing themes of this emerging area and present a taxonomy that can be used to categorize different problems and reconstruction methods. Our taxonomy is organized along two central axes: (1) whether or not a forward model is known and to what extent it is used in training and testing, and (2) whether or not the learning is supervised or unsupervised, i.e., whether or not the training relies on access to matched ground truth image and measurement pairs. We also discuss the trade-offs associated with these different reconstruction approaches, caveats and common failure modes, plus open problems and avenues for future work.
Subspace Fitting Meets Regression: The Effects of Supervision and Orthonormality Constraints on Double Descent of Generalization Errors
Feb 25, 2020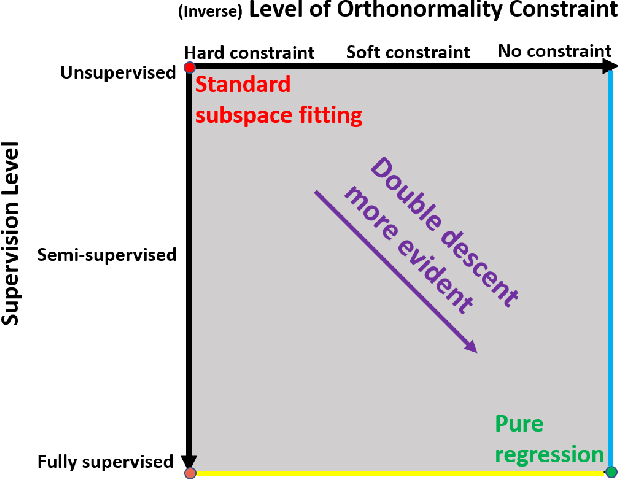
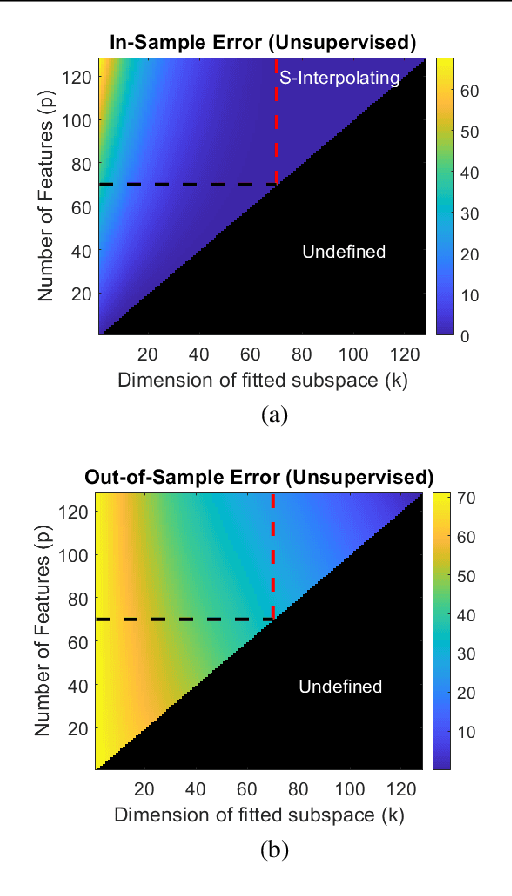
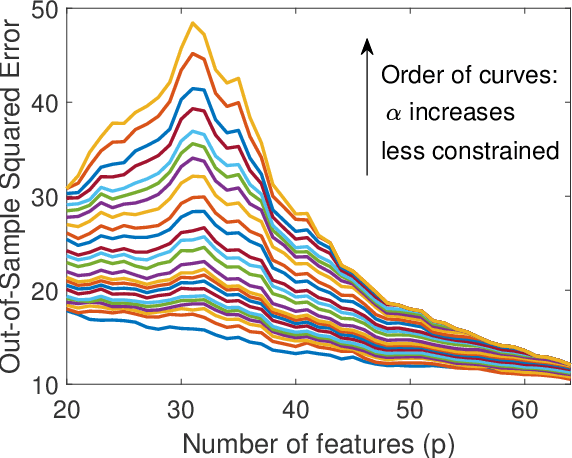
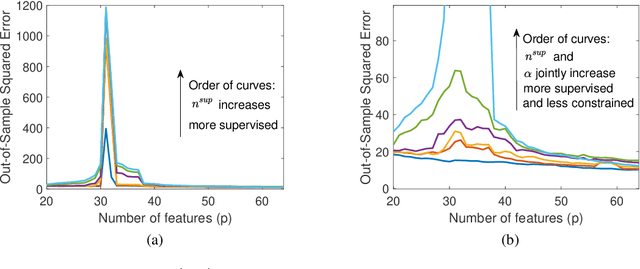
We study the linear subspace fitting problem in the overparameterized setting, where the estimated subspace can perfectly interpolate the training examples. Our scope includes the least-squares solutions to subspace fitting tasks with varying levels of supervision in the training data (i.e., the proportion of input-output examples of the desired low-dimensional mapping) and orthonormality of the vectors defining the learned operator. This flexible family of problems connects standard, unsupervised subspace fitting that enforces strict orthonormality with a corresponding regression task that is fully supervised and does not constrain the linear operator structure. This class of problems is defined over a supervision-orthonormality plane, where each coordinate induces a problem instance with a unique pair of supervision level and softness of orthonormality constraints. We explore this plane and show that the generalization errors of the corresponding subspace fitting problems follow double descent trends as the settings become more supervised and less orthonormally constrained.
Scheduled Restart Momentum for Accelerated Stochastic Gradient Descent
Feb 24, 2020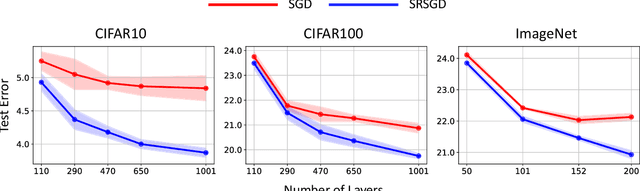

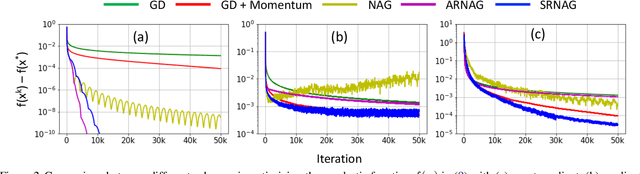
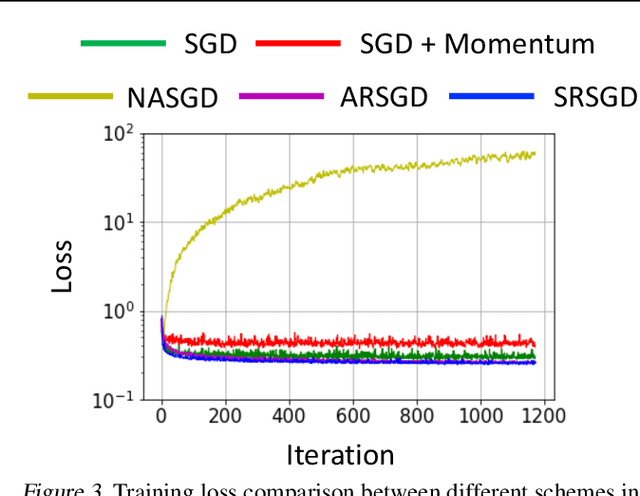
Stochastic gradient descent (SGD) with constant momentum and its variants such as Adam are the optimization algorithms of choice for training deep neural networks (DNNs). Since DNN training is incredibly computationally expensive, there is great interest in speeding up convergence. Nesterov accelerated gradient (NAG) improves the convergence rate of gradient descent (GD) for convex optimization using a specially designed momentum; however, it accumulates error when an inexact gradient is used (such as in SGD), slowing convergence at best and diverging at worst. In this paper, we propose Scheduled Restart SGD (SRSGD), a new NAG-style scheme for training DNNs. SRSGD replaces the constant momentum in SGD by the increasing momentum in NAG but stabilizes the iterations by resetting the momentum to zero according to a schedule. Using a variety of models and benchmarks for image classification, we demonstrate that, in training DNNs, SRSGD significantly improves convergence and generalization; for instance in training ResNet200 for ImageNet classification, SRSGD achieves an error rate of 20.93% vs. the benchmark of 22.13%. These improvements become more significant as the network grows deeper. Furthermore, on both CIFAR and ImageNet, SRSGD reaches similar or even better error rates with fewer training epochs compared to the SGD baseline. We provide code for SRSGD at https://github.com/minhtannguyen/SRSGD.