 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Evaluation Protocol of Domain Generalization
May 24, 2023



Domain generalization aims to solve the challenge of Out-of-Distribution (OOD) generalization by leveraging common knowledge learned from multiple training domains to generalize to unseen test domains. To accurately evaluate the OOD generalization ability, it is necessary to ensure that test data information is unavailable. However, the current domain generalization protocol may still have potential test data information leakage. This paper examines the potential risks of test data information leakage in two aspects of the current protocol: pretraining on ImageNet and oracle model selection. We propose that training from scratch and using multiple test domains would result in a more precise evaluation of OOD generalization ability. We also rerun the algorithms with the modified protocol and introduce a new leaderboard to encourage future research in domain generalization with a fairer comparison.
Gradient Norm Aware Minimization Seeks First-Order Flatness and Improves Generalization
Mar 03, 2023



Recently, flat minima are proven to be effective for improving generalization and sharpness-aware minimization (SAM) achieves state-of-the-art performance. Yet the current definition of flatness discussed in SAM and its follow-ups are limited to the zeroth-order flatness (i.e., the worst-case loss within a perturbation radius). We show that the zeroth-order flatness can be insufficient to discriminate minima with low generalization error from those with high generalization error both when there is a single minimum or multiple minima within the given perturbation radius. Thus we present first-order flatness, a stronger measure of flatness focusing on the maximal gradient norm within a perturbation radius which bounds both the maximal eigenvalue of Hessian at local minima and the regularization function of SAM. We also present a novel training procedure named Gradient norm Aware Minimization (GAM) to seek minima with uniformly small curvature across all directions. Experimental results show that GAM improves the generalization of models trained with current optimizers such as SGD and AdamW on various datasets and networks. Furthermore, we show that GAM can help SAM find flatter minima and achieve better generalization.
Model Agnostic Sample Reweighting for Out-of-Distribution Learning
Jan 24, 2023



Distributionally robust optimization (DRO) and invariant risk minimization (IRM) are two popular methods proposed to improve out-of-distribution (OOD) generalization performance of machine learning models. While effective for small models, it has been observed that these methods can be vulnerable to overfitting with large overparameterized models. This work proposes a principled method, \textbf{M}odel \textbf{A}gnostic sam\textbf{PL}e r\textbf{E}weighting (\textbf{MAPLE}), to effectively address OOD problem, especially in overparameterized scenarios. Our key idea is to find an effective reweighting of the training samples so that the standard empirical risk minimization training of a large model on the weighted training data leads to superior OOD generalization performance. The overfitting issue is addressed by considering a bilevel formulation to search for the sample reweighting, in which the generalization complexity depends on the search space of sample weights instead of the model size. We present theoretical analysis in linear case to prove the insensitivity of MAPLE to model size, and empirically verify its superiority in surpassing state-of-the-art methods by a large margin. Code is available at \url{https://github.com/x-zho14/MAPLE}.
Stable Learning via Sparse Variable Independence
Dec 02, 2022The problem of covariate-shift generalization has attracted intensive research attention. Previous stable learning algorithms employ sample reweighting schemes to decorrelate the covariates when there is no explicit domain information about training data. However, with finite samples, it is difficult to achieve the desirable weights that ensure perfect independence to get rid of the unstable variables. Besides, decorrelating within stable variables may bring about high variance of learned models because of the over-reduced effective sample size. A tremendous sample size is required for these algorithms to work. In this paper, with theoretical justification, we propose SVI (Sparse Variable Independence) for the covariate-shift generalization problem. We introduce sparsity constraint to compensate for the imperfectness of sample reweighting under the finite-sample setting in previous methods. Furthermore, we organically combine independence-based sample reweighting and sparsity-based variable selection in an iterative way to avoid decorrelating within stable variables, increasing the effective sample size to alleviate variance inflation. Experiments on both synthetic and real-world datasets demonstrate the improvement of covariate-shift generalization performance brought by SVI.
Product Ranking for Revenue Maximization with Multiple Purchases
Oct 15, 2022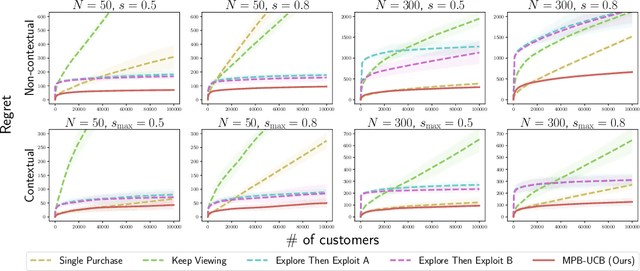
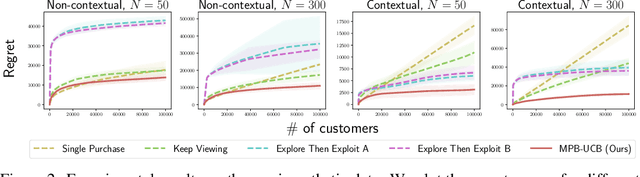
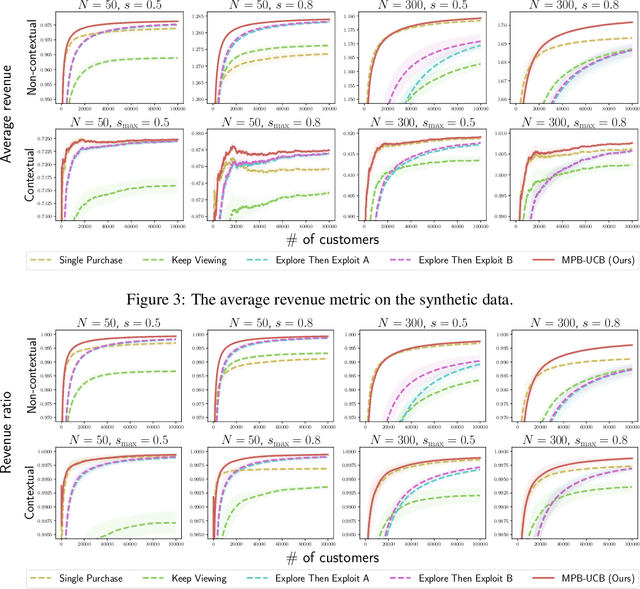
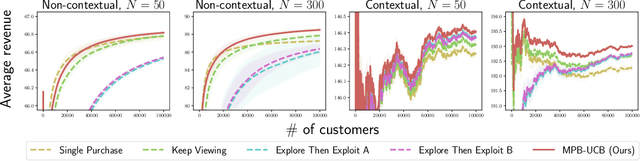
Product ranking is the core problem for revenue-maximizing online retailers. To design proper product ranking algorithms, various consumer choice models are proposed to characterize the consumers' behaviors when they are provided with a list of products. However, existing works assume that each consumer purchases at most one product or will keep viewing the product list after purchasing a product, which does not agree with the common practice in real scenarios. In this paper, we assume that each consumer can purchase multiple products at will. To model consumers' willingness to view and purchase, we set a random attention span and purchase budget, which determines the maximal amount of products that he/she views and purchases, respectively. Under this setting, we first design an optimal ranking policy when the online retailer can precisely model consumers' behaviors. Based on the policy, we further develop the Multiple-Purchase-with-Budget UCB (MPB-UCB) algorithms with $\~O(\sqrt{T})$ regret that estimate consumers' behaviors and maximize revenue simultaneously in online settings. Experiments on both synthetic and semi-synthetic datasets prove the effectiveness of the proposed algorithms.
NICO++: Towards Better Benchmarking for Domain Generalization
Apr 21, 2022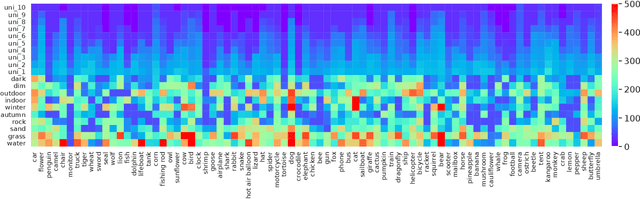

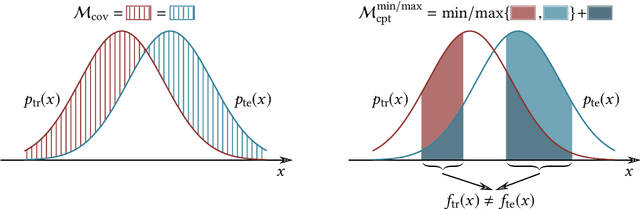
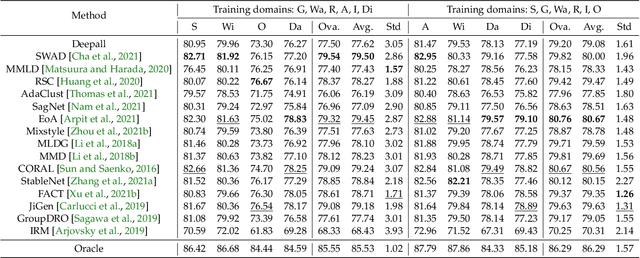
Despite the remarkable performance that modern deep neural networks have achieved on independent and identically distributed (I.I.D.) data, they can crash under distribution shifts. Most current evaluation methods for domain generalization (DG) adopt the leave-one-out strategy as a compromise on the limited number of domains. We propose a large-scale benchmark with extensive labeled domains named NICO++ along with more rational evaluation methods for comprehensively evaluating DG algorithms. To evaluate DG datasets, we propose two metrics to quantify covariate shift and concept shift, respectively. Two novel generalization bounds from the perspective of data construction are proposed to prove that limited concept shift and significant covariate shift favor the evaluation capability for generalization. Through extensive experiments, NICO++ shows its superior evaluation capability compared with current DG datasets and its contribution in alleviating unfairness caused by the leak of oracle knowledge in model selection.
Towards Domain Generalization in Object Detection
Mar 27, 2022
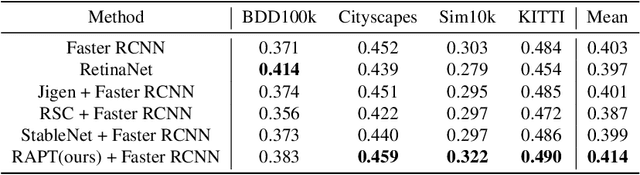
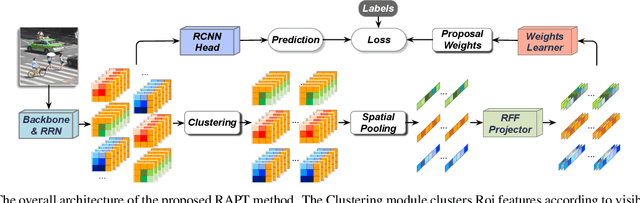
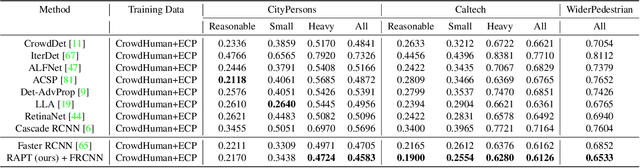
Despite the striking performance achieved by modern detectors when training and test data are sampled from the same or similar distribution, the generalization ability of detectors under unknown distribution shifts remains hardly studied. Recently several works discussed the detectors' adaptation ability to a specific target domain which are not readily applicable in real-world applications since detectors may encounter various environments or situations while pre-collecting all of them before training is inconceivable. In this paper, we study the critical problem, domain generalization in object detection (DGOD), where detectors are trained with source domains and evaluated on unknown target domains. To thoroughly evaluate detectors under unknown distribution shifts, we formulate the DGOD problem and propose a comprehensive evaluation benchmark to fill the vacancy. Moreover, we propose a novel method named Region Aware Proposal reweighTing (RAPT) to eliminate dependence within RoI features. Extensive experiments demonstrate that current DG methods fail to address the DGOD problem and our method outperforms other state-of-the-art counterparts.
Regulatory Instruments for Fair Personalized Pricing
Feb 09, 2022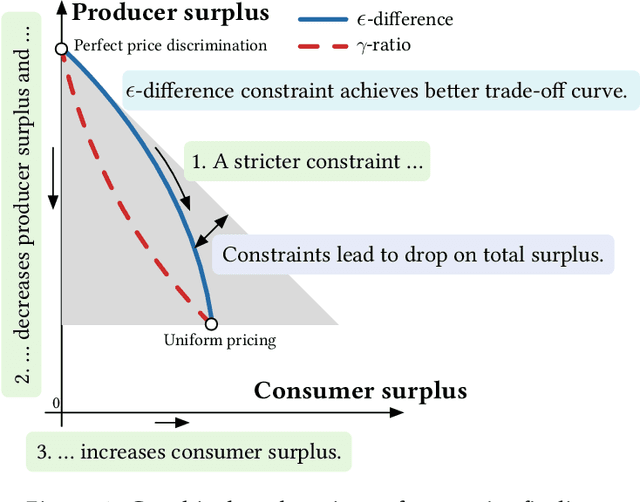

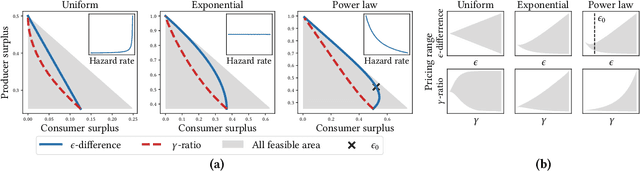
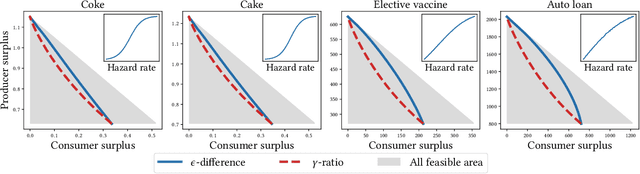
Personalized pricing is a business strategy to charge different prices to individual consumers based on their characteristics and behaviors. It has become common practice in many industries nowadays due to the availability of a growing amount of high granular consumer data. The discriminatory nature of personalized pricing has triggered heated debates among policymakers and academics on how to design regulation policies to balance market efficiency and equity. In this paper, we propose two sound policy instruments, i.e., capping the range of the personalized prices or their ratios. We investigate the optimal pricing strategy of a profit-maximizing monopoly under both regulatory constraints and the impact of imposing them on consumer surplus, producer surplus, and social welfare. We theoretically prove that both proposed constraints can help balance consumer surplus and producer surplus at the expense of total surplus for common demand distributions, such as uniform, logistic, and exponential distributions. Experiments on both simulation and real-world datasets demonstrate the correctness of these theoretical results. Our findings and insights shed light on regulatory policy design for the increasingly monopolized business in the digital era.
Why Stable Learning Works? A Theory of Covariate Shift Generalization
Nov 03, 2021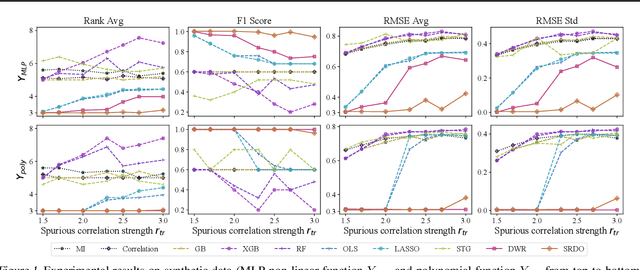
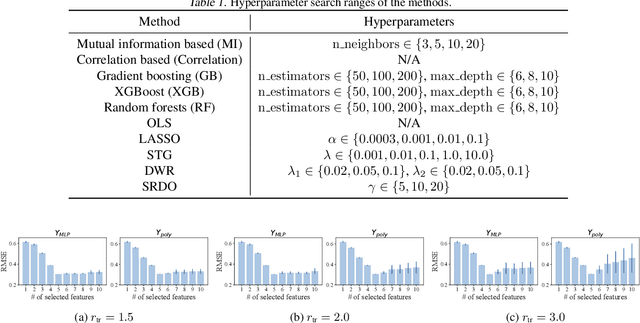
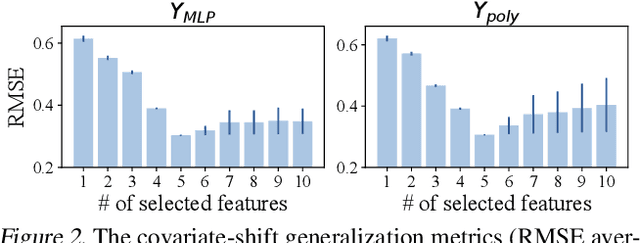
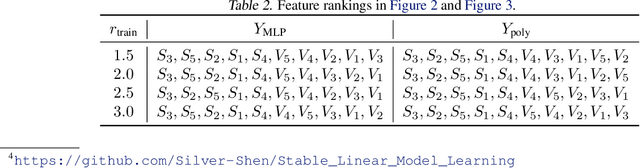
Covariate shift generalization, a typical case in out-of-distribution (OOD) generalization, requires a good performance on the unknown testing distribution, which varies from the accessible training distribution in the form of covariate shift. Recently, stable learning algorithms have shown empirical effectiveness to deal with covariate shift generalization on several learning models involving regression algorithms and deep neural networks. However, the theoretical explanations for such effectiveness are still missing. In this paper, we take a step further towards the theoretical analysis of stable learning algorithms by explaining them as feature selection processes. We first specify a set of variables, named minimal stable variable set, that is minimal and optimal to deal with covariate shift generalization for common loss functions, including the mean squared loss and binary cross entropy loss. Then we prove that under ideal conditions, stable learning algorithms could identify the variables in this set. Further analysis on asymptotic properties and error propagation are also provided. These theories shed light on why stable learning works for covariate shift generalization.
Towards Out-Of-Distribution Generalization: A Survey
Aug 31, 2021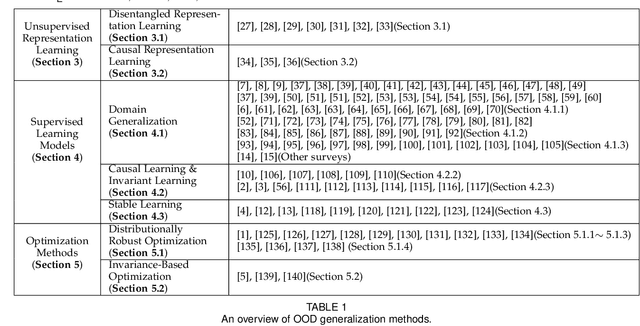
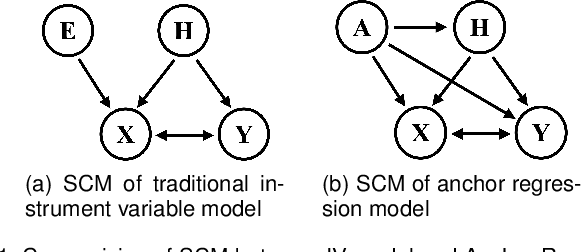
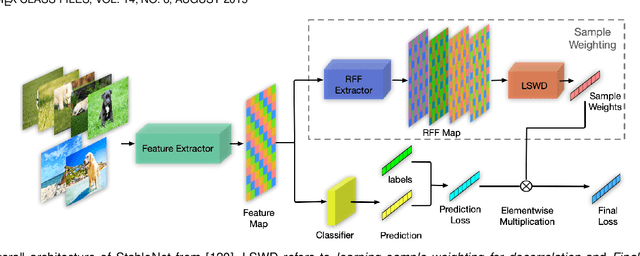
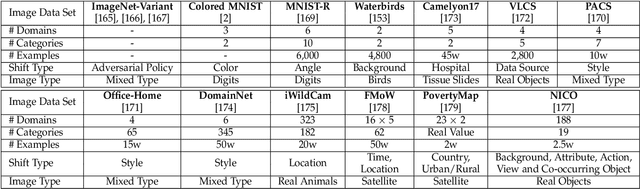
Classic machine learning methods are built on the $i.i.d.$ assumption that training and testing data are independent and identically distributed. However, in real scenarios, the $i.i.d.$ assumption can hardly be satisfied, rendering the sharp drop of classic machine learning algorithms' performances under distributional shifts, which indicates the significance of investigating the Out-of-Distribution generalization problem. Out-of-Distribution (OOD) generalization problem addresses the challenging setting where the testing distribution is unknown and different from the training. This paper serves as the first effort to systematically and comprehensively discuss the OOD generalization problem, from the definition, methodology, evaluation to the implications and future directions. Firstly, we provide the formal definition of the OOD generalization problem. Secondly, existing methods are categorized into three parts based on their positions in the whole learning pipeline, namely unsupervised representation learning, supervised model learning and optimization, and typical methods for each category are discussed in detail. We then demonstrate the theoretical connections of different categories, and introduce the commonly used datasets and evaluation metrics. Finally, we summarize the whole literature and raise some future directions for OOD generalization problem. The summary of OOD generalization methods reviewed in this survey can be found at http://out-of-distribution-generalization.com.