 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding the Capabilities of Reinforcement Learning via Text Feedback
Feb 02, 2026The success of RL for LLM post-training stems from an unreasonably uninformative source: a single bit of information per rollout as binary reward or preference label. At the other extreme, distillation offers dense supervision but requires demonstrations, which are costly and difficult to scale. We study text feedback as an intermediate signal: richer than scalar rewards, yet cheaper than complete demonstrations. Textual feedback is a natural mode of human interaction and is already abundant in many real-world settings, where users, annotators, and automated judges routinely critique LLM outputs. Towards leveraging text feedback at scale, we formalize a multi-turn RL setup, RL from Text Feedback (RLTF), where text feedback is available during training but not at inference. Therefore, models must learn to internalize the feedback in order to improve their test-time single-turn performance. To do this, we propose two methods: Self Distillation (RLTF-SD), which trains the single-turn policy to match its own feedback-conditioned second-turn generations; and Feedback Modeling (RLTF-FM), which predicts the feedback as an auxiliary objective. We provide theoretical analysis on both methods, and empirically evaluate on reasoning puzzles, competition math, and creative writing tasks. Our results show that both methods consistently outperform strong baselines across benchmarks, highlighting the potential of RL with an additional source of rich supervision at scale.
Outcome-based Exploration for LLM Reasoning
Sep 08, 2025Reinforcement learning (RL) has emerged as a powerful method for improving the reasoning abilities of large language models (LLMs). Outcome-based RL, which rewards policies solely for the correctness of the final answer, yields substantial accuracy gains but also induces a systematic loss in generation diversity. This collapse undermines real-world performance, where diversity is critical for test-time scaling. We analyze this phenomenon by viewing RL post-training as a sampling process and show that, strikingly, RL can reduce effective diversity even on the training set relative to the base model. Our study highlights two central findings: (i) a transfer of diversity degradation, where reduced diversity on solved problems propagates to unsolved ones, and (ii) the tractability of the outcome space, since reasoning tasks admit only a limited set of distinct answers. Motivated by these insights, we propose outcome-based exploration, which assigns exploration bonuses according to final outcomes. We introduce two complementary algorithms: historical exploration, which encourages rarely observed answers via UCB-style bonuses, and batch exploration, which penalizes within-batch repetition to promote test-time diversity. Experiments on standard competition math with Llama and Qwen models demonstrate that both methods improve accuracy while mitigating diversity collapse. On the theoretical side, we formalize the benefit of outcome-based exploration through a new model of outcome-based bandits. Together, these contributions chart a practical path toward RL methods that enhance reasoning without sacrificing the diversity essential for scalable deployment.
Soft Policy Optimization: Online Off-Policy RL for Sequence Models
Mar 07, 2025

RL-based post-training of language models is almost exclusively done using on-policy methods such as PPO. These methods cannot learn from arbitrary sequences such as those produced earlier in training, in earlier runs, by human experts or other policies, or by decoding and exploration methods. This results in severe sample inefficiency and exploration difficulties, as well as a potential loss of diversity in the policy responses. Moreover, asynchronous PPO implementations require frequent and costly model transfers, and typically use value models which require a large amount of memory. In this paper we introduce Soft Policy Optimization (SPO), a simple, scalable and principled Soft RL method for sequence model policies that can learn from arbitrary online and offline trajectories and does not require a separate value model. In experiments on code contests, we shows that SPO outperforms PPO on pass@10, is significantly faster and more memory efficient, is able to benefit from off-policy data, enjoys improved stability, and learns more diverse (i.e. soft) policies.
Offline Regularised Reinforcement Learning for Large Language Models Alignment
May 29, 2024The dominant framework for alignment of large language models (LLM), whether through reinforcement learning from human feedback or direct preference optimisation, is to learn from preference data. This involves building datasets where each element is a quadruplet composed of a prompt, two independent responses (completions of the prompt) and a human preference between the two independent responses, yielding a preferred and a dis-preferred response. Such data is typically scarce and expensive to collect. On the other hand, \emph{single-trajectory} datasets where each element is a triplet composed of a prompt, a response and a human feedback is naturally more abundant. The canonical element of such datasets is for instance an LLM's response to a user's prompt followed by a user's feedback such as a thumbs-up/down. Consequently, in this work, we propose DRO, or \emph{Direct Reward Optimisation}, as a framework and associated algorithms that do not require pairwise preferences. DRO uses a simple mean-squared objective that can be implemented in various ways. We validate our findings empirically, using T5 encoder-decoder language models, and show DRO's performance over selected baselines such as Kahneman-Tversky Optimization (KTO). Thus, we confirm that DRO is a simple and empirically compelling method for single-trajectory policy optimisation.
Super-Exponential Regret for UCT, AlphaGo and Variants
May 07, 2024We improve the proofs of the lower bounds of Coquelin and Munos (2007) that demonstrate that UCT can have $\exp(\dots\exp(1)\dots)$ regret (with $\Omega(D)$ exp terms) on the $D$-chain environment, and that a `polynomial' UCT variant has $\exp_2(\exp_2(D - O(\log D)))$ regret on the same environment -- the original proofs contain an oversight for rewards bounded in $[0, 1]$, which we fix in the present draft. We also adapt the proofs to AlphaGo's MCTS and its descendants (e.g., AlphaZero, Leela Zero) to also show $\exp_2(\exp_2(D - O(\log D)))$ regret.
Human Alignment of Large Language Models through Online Preference Optimisation
Mar 13, 2024



Ensuring alignment of language models' outputs with human preferences is critical to guarantee a useful, safe, and pleasant user experience. Thus, human alignment has been extensively studied recently and several methods such as Reinforcement Learning from Human Feedback (RLHF), Direct Policy Optimisation (DPO) and Sequence Likelihood Calibration (SLiC) have emerged. In this paper, our contribution is two-fold. First, we show the equivalence between two recent alignment methods, namely Identity Policy Optimisation (IPO) and Nash Mirror Descent (Nash-MD). Second, we introduce a generalisation of IPO, named IPO-MD, that leverages the regularised sampling approach proposed by Nash-MD. This equivalence may seem surprising at first sight, since IPO is an offline method whereas Nash-MD is an online method using a preference model. However, this equivalence can be proven when we consider the online version of IPO, that is when both generations are sampled by the online policy and annotated by a trained preference model. Optimising the IPO loss with such a stream of data becomes then equivalent to finding the Nash equilibrium of the preference model through self-play. Building on this equivalence, we introduce the IPO-MD algorithm that generates data with a mixture policy (between the online and reference policy) similarly as the general Nash-MD algorithm. We compare online-IPO and IPO-MD to different online versions of existing losses on preference data such as DPO and SLiC on a summarisation task.
Model-free Posterior Sampling via Learning Rate Randomization
Oct 27, 2023



In this paper, we introduce Randomized Q-learning (RandQL), a novel randomized model-free algorithm for regret minimization in episodic Markov Decision Processes (MDPs). To the best of our knowledge, RandQL is the first tractable model-free posterior sampling-based algorithm. We analyze the performance of RandQL in both tabular and non-tabular metric space settings. In tabular MDPs, RandQL achieves a regret bound of order $\widetilde{\mathcal{O}}(\sqrt{H^{5}SAT})$, where $H$ is the planning horizon, $S$ is the number of states, $A$ is the number of actions, and $T$ is the number of episodes. For a metric state-action space, RandQL enjoys a regret bound of order $\widetilde{\mathcal{O}}(H^{5/2} T^{(d_z+1)/(d_z+2)})$, where $d_z$ denotes the zooming dimension. Notably, RandQL achieves optimistic exploration without using bonuses, relying instead on a novel idea of learning rate randomization. Our empirical study shows that RandQL outperforms existing approaches on baseline exploration environments.
Representations and Exploration for Deep Reinforcement Learning using Singular Value Decomposition
May 02, 2023



Representation learning and exploration are among the key challenges for any deep reinforcement learning agent. In this work, we provide a singular value decomposition based method that can be used to obtain representations that preserve the underlying transition structure in the domain. Perhaps interestingly, we show that these representations also capture the relative frequency of state visitations, thereby providing an estimate for pseudo-counts for free. To scale this decomposition method to large-scale domains, we provide an algorithm that never requires building the transition matrix, can make use of deep networks, and also permits mini-batch training. Further, we draw inspiration from predictive state representations and extend our decomposition method to partially observable environments. With experiments on multi-task settings with partially observable domains, we show that the proposed method can not only learn useful representation on DM-Lab-30 environments (that have inputs involving language instructions, pixel images, and rewards, among others) but it can also be effective at hard exploration tasks in DM-Hard-8 environments.
Fast Rates for Maximum Entropy Exploration
Mar 14, 2023



We consider the reinforcement learning (RL) setting, in which the agent has to act in unknown environment driven by a Markov Decision Process (MDP) with sparse or even reward free signals. In this situation, exploration becomes the main challenge. In this work, we study the maximum entropy exploration problem of two different types. The first type is visitation entropy maximization that was previously considered by Hazan et al. (2019) in the discounted setting. For this type of exploration, we propose an algorithm based on a game theoretic representation that has $\widetilde{\mathcal{O}}(H^3 S^2 A / \varepsilon^2)$ sample complexity thus improving the $\varepsilon$-dependence of Hazan et al. (2019), where $S$ is a number of states, $A$ is a number of actions, $H$ is an episode length, and $\varepsilon$ is a desired accuracy. The second type of entropy we study is the trajectory entropy. This objective function is closely related to the entropy-regularized MDPs, and we propose a simple modification of the UCBVI algorithm that has a sample complexity of order $\widetilde{\mathcal{O}}(1/\varepsilon)$ ignoring dependence in $S, A, H$. Interestingly enough, it is the first theoretical result in RL literature establishing that the exploration problem for the regularized MDPs can be statistically strictly easier (in terms of sample complexity) than for the ordinary MDPs.
Optimistic Posterior Sampling for Reinforcement Learning with Few Samples and Tight Guarantees
Sep 28, 2022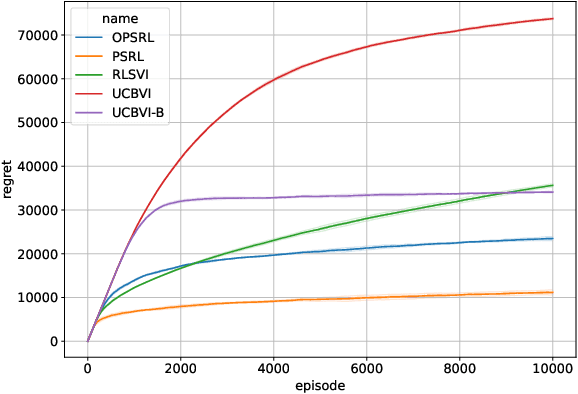
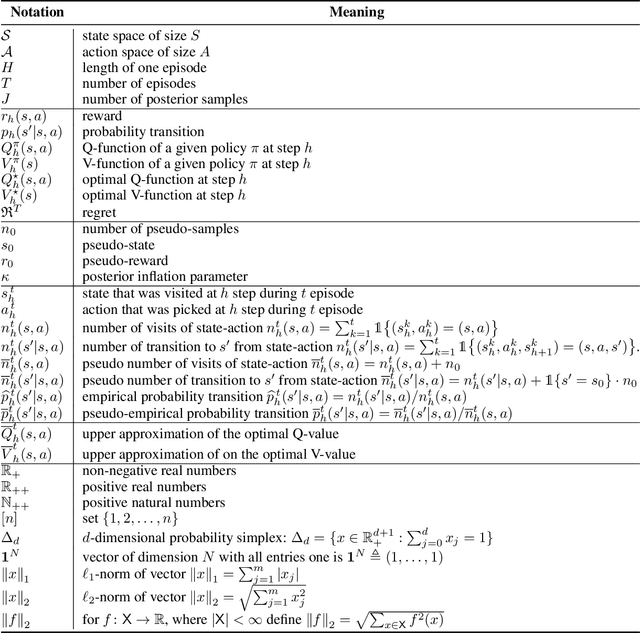
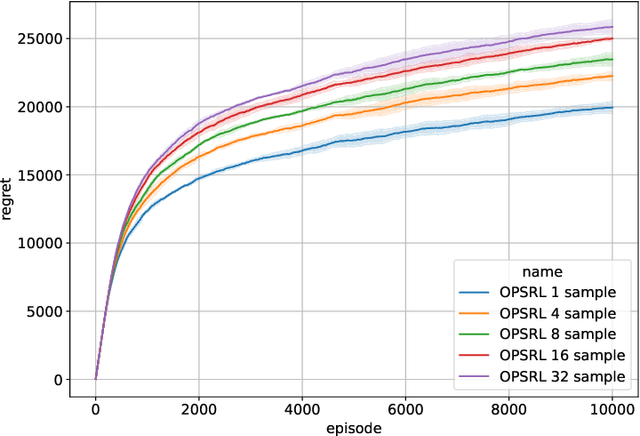
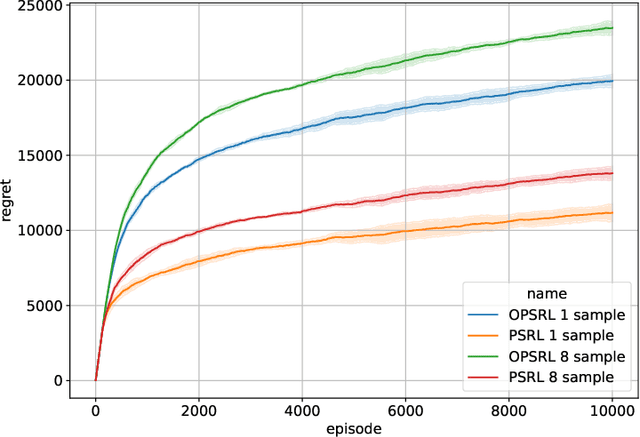
We consider reinforcement learning in an environment modeled by an episodic, finite, stage-dependent Markov decision process of horizon $H$ with $S$ states, and $A$ actions. The performance of an agent is measured by the regret after interacting with the environment for $T$ episodes. We propose an optimistic posterior sampling algorithm for reinforcement learning (OPSRL), a simple variant of posterior sampling that only needs a number of posterior samples logarithmic in $H$, $S$, $A$, and $T$ per state-action pair. For OPSRL we guarantee a high-probability regret bound of order at most $\widetilde{\mathcal{O}}(\sqrt{H^3SAT})$ ignoring $\text{poly}\log(HSAT)$ terms. The key novel technical ingredient is a new sharp anti-concentration inequality for linear forms which may be of independent interest. Specifically, we extend the normal approximation-based lower bound for Beta distributions by Alfers and Dinges [1984] to Dirichlet distributions. Our bound matches the lower bound of order $\Omega(\sqrt{H^3SAT})$, thereby answering the open problems raised by Agrawal and Jia [2017b] for the episodic setting.