 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Semantic Information and Deep Matching for Optical Flow
Aug 23, 2016
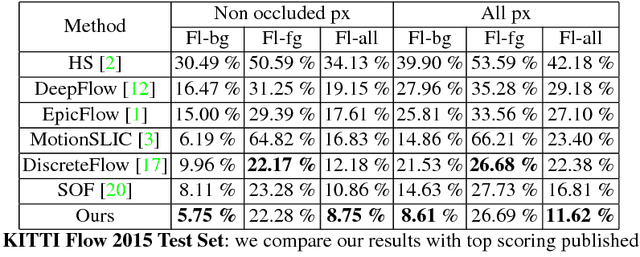
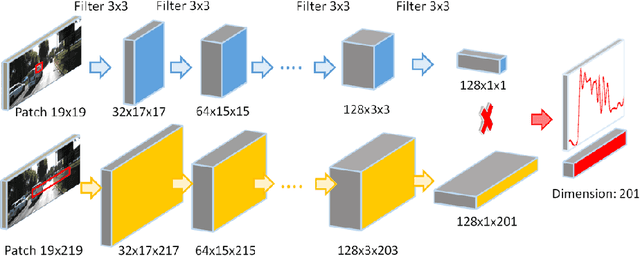
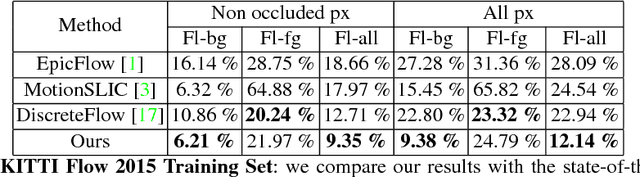
We tackle the problem of estimating optical flow from a monocular camera in the context of autonomous driving. We build on the observation that the scene is typically composed of a static background, as well as a relatively small number of traffic participants which move rigidly in 3D. We propose to estimate the traffic participants using instance-level segmentation. For each traffic participant, we use the epipolar constraints that govern each independent motion for faster and more accurate estimation. Our second contribution is a new convolutional net that learns to perform flow matching, and is able to estimate the uncertainty of its matches. This is a core element of our flow estimation pipeline. We demonstrate the effectiveness of our approach in the challenging KITTI 2015 flow benchmark, and show that our approach outperforms published approaches by a large margin.
Find your Way by Observing the Sun and Other Semantic Cues
Jun 23, 2016
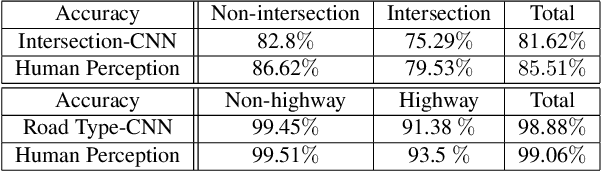


In this paper we present a robust, efficient and affordable approach to self-localization which does not require neither GPS nor knowledge about the appearance of the world. Towards this goal, we utilize freely available cartographic maps and derive a probabilistic model that exploits semantic cues in the form of sun direction, presence of an intersection, road type, speed limit as well as the ego-car trajectory in order to produce very reliable localization results. Our experimental evaluation shows that our approach can localize much faster (in terms of driving time) with less computation and more robustly than competing approaches, which ignore semantic information.
Training Deep Neural Networks via Direct Loss Minimization
Jun 02, 2016
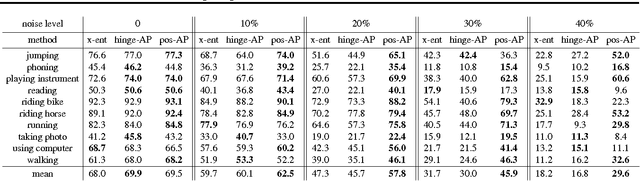

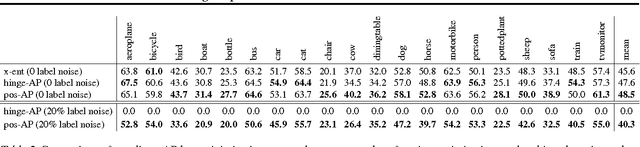
Supervised training of deep neural nets typically relies on minimizing cross-entropy. However, in many domains, we are interested in performing well on metrics specific to the application. In this paper we propose a direct loss minimization approach to train deep neural networks, which provably minimizes the application-specific loss function. This is often non-trivial, since these functions are neither smooth nor decomposable and thus are not amenable to optimization with standard gradient-based methods. We demonstrate the effectiveness of our approach in the context of maximizing average precision for ranking problems. Towards this goal, we develop a novel dynamic programming algorithm that can efficiently compute the weight updates. Our approach proves superior to a variety of baselines in the context of action classification and object detection, especially in the presence of label noise.
Instance-Level Segmentation for Autonomous Driving with Deep Densely Connected MRFs
Apr 27, 2016
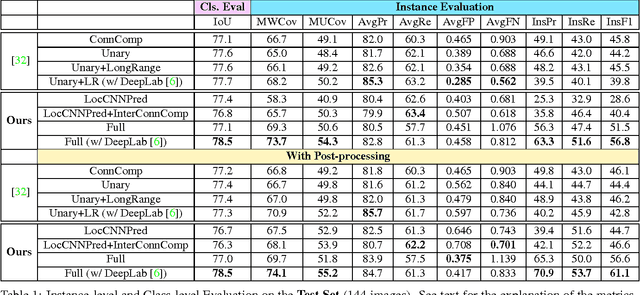
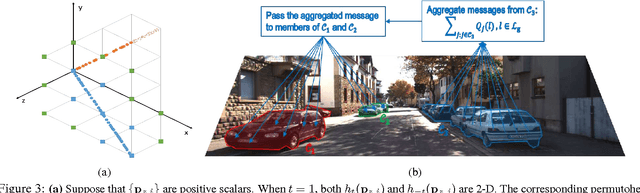

Our aim is to provide a pixel-wise instance-level labeling of a monocular image in the context of autonomous driving. We build on recent work [Zhang et al., ICCV15] that trained a convolutional neural net to predict instance labeling in local image patches, extracted exhaustively in a stride from an image. A simple Markov random field model using several heuristics was then proposed in [Zhang et al., ICCV15] to derive a globally consistent instance labeling of the image. In this paper, we formulate the global labeling problem with a novel densely connected Markov random field and show how to encode various intuitive potentials in a way that is amenable to efficient mean field inference [Kr\"ahenb\"uhl et al., NIPS11]. Our potentials encode the compatibility between the global labeling and the patch-level predictions, contrast-sensitive smoothness as well as the fact that separate regions form different instances. Our experiments on the challenging KITTI benchmark [Geiger et al., CVPR12] demonstrate that our method achieves a significant performance boost over the baseline [Zhang et al., ICCV15].
Soccer Field Localization from a Single Image
Apr 10, 2016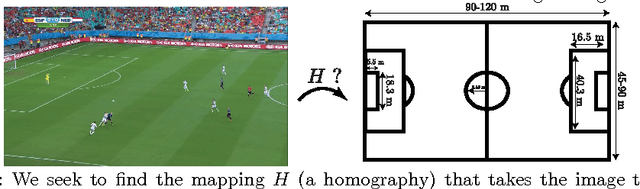
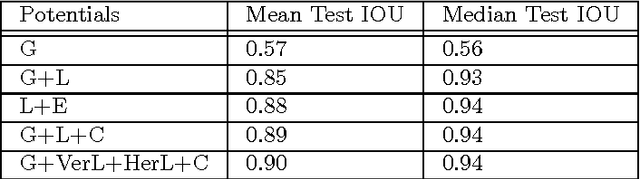
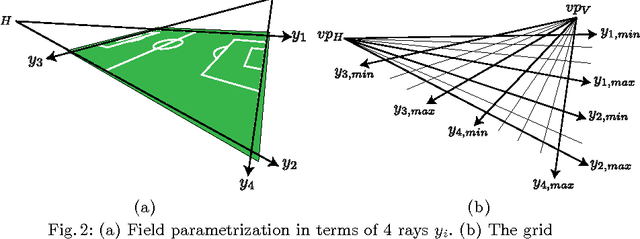
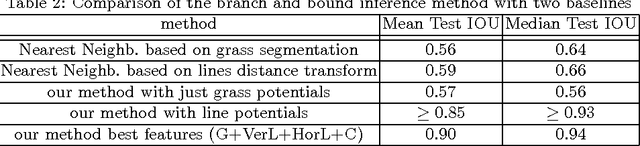
In this work, we propose a novel way of efficiently localizing a soccer field from a single broadcast image of the game. Related work in this area relies on manually annotating a few key frames and extending the localization to similar images, or installing fixed specialized cameras in the stadium from which the layout of the field can be obtained. In contrast, we formulate this problem as a branch and bound inference in a Markov random field where an energy function is defined in terms of field cues such as grass, lines and circles. Moreover, our approach is fully automatic and depends only on single images from the broadcast video of the game. We demonstrate the effectiveness of our method by applying it to various games and obtain promising results. Finally, we posit that our approach can be applied easily to other sports such as hockey and basketball.
Order-Embeddings of Images and Language
Mar 01, 2016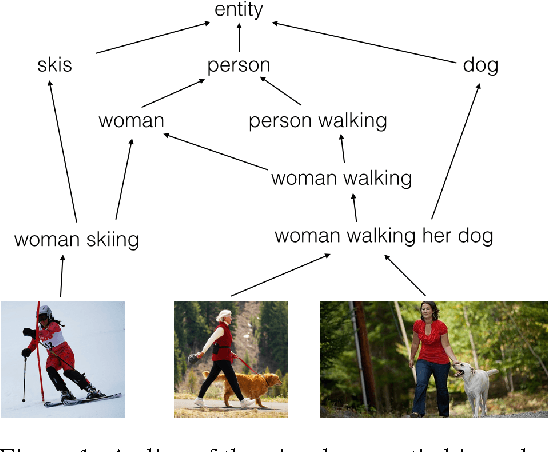

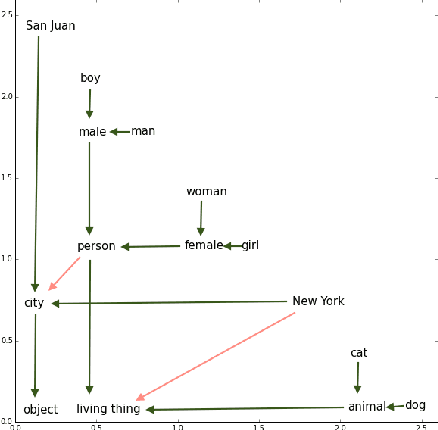
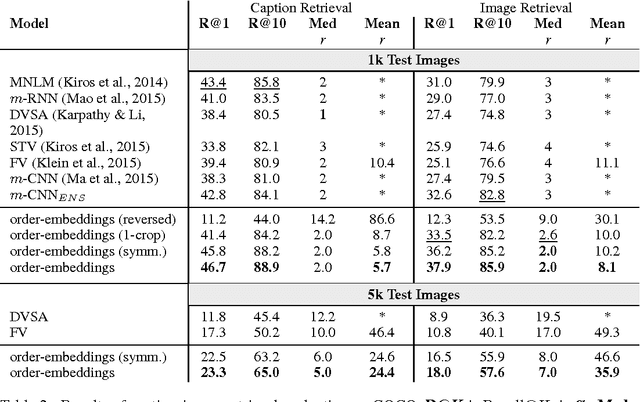
Hypernymy, textual entailment, and image captioning can be seen as special cases of a single visual-semantic hierarchy over words, sentences, and images. In this paper we advocate for explicitly modeling the partial order structure of this hierarchy. Towards this goal, we introduce a general method for learning ordered representations, and show how it can be applied to a variety of tasks involving images and language. We show that the resulting representations improve performance over current approaches for hypernym prediction and image-caption retrieval.
Reduced-Precision Strategies for Bounded Memory in Deep Neural Nets
Jan 08, 2016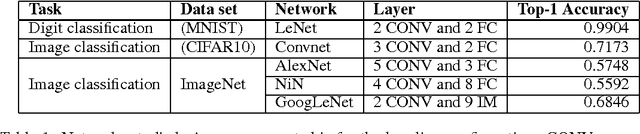
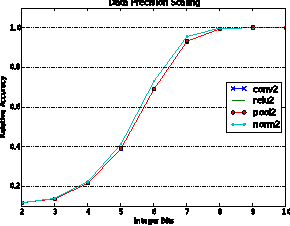
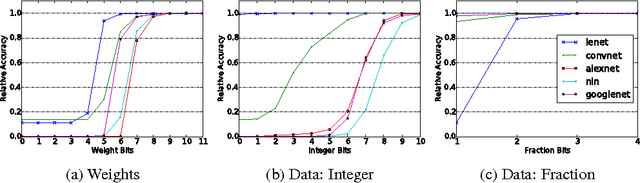
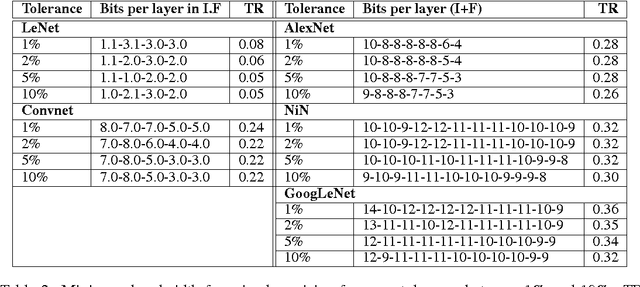
This work investigates how using reduced precision data in Convolutional Neural Networks (CNNs) affects network accuracy during classification. More specifically, this study considers networks where each layer may use different precision data. Our key result is the observation that the tolerance of CNNs to reduced precision data not only varies across networks, a well established observation, but also within networks. Tuning precision per layer is appealing as it could enable energy and performance improvements. In this paper we study how error tolerance across layers varies and propose a method for finding a low precision configuration for a network while maintaining high accuracy. A diverse set of CNNs is analyzed showing that compared to a conventional implementation using a 32-bit floating-point representation for all layers, and with less than 1% loss in relative accuracy, the data footprint required by these networks can be reduced by an average of 74% and up to 92%.
Monocular Object Instance Segmentation and Depth Ordering with CNNs
Dec 18, 2015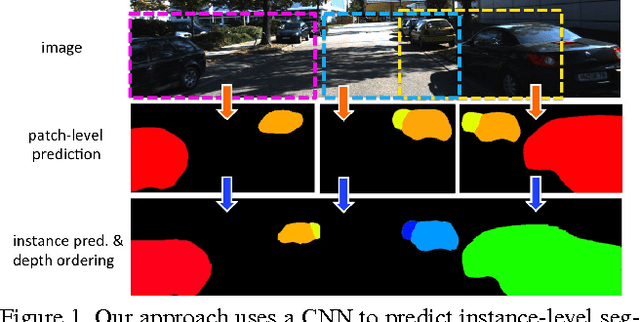
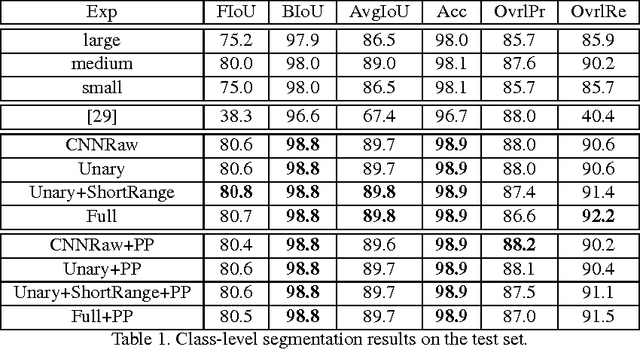

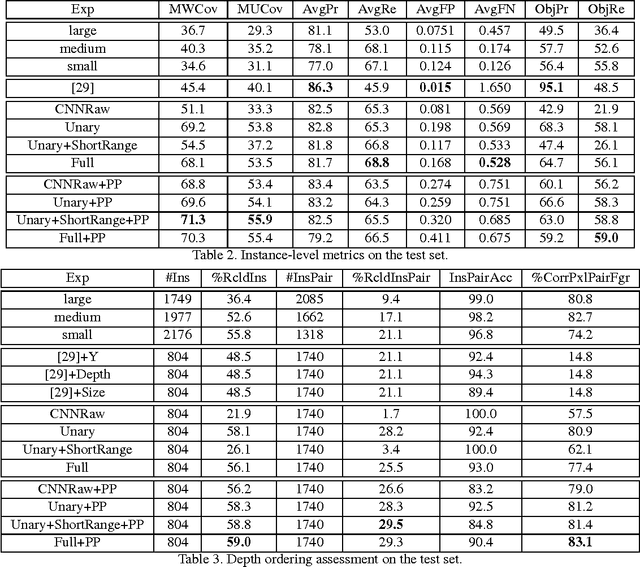
In this paper we tackle the problem of instance-level segmentation and depth ordering from a single monocular image. Towards this goal, we take advantage of convolutional neural nets and train them to directly predict instance-level segmentations where the instance ID encodes the depth ordering within image patches. To provide a coherent single explanation of an image we develop a Markov random field which takes as input the predictions of convolutional neural nets applied at overlapping patches of different resolutions, as well as the output of a connected component algorithm. It aims to predict accurate instance-level segmentation and depth ordering. We demonstrate the effectiveness of our approach on the challenging KITTI benchmark and show good performance on both tasks.
Skip-Thought Vectors
Jun 22, 2015
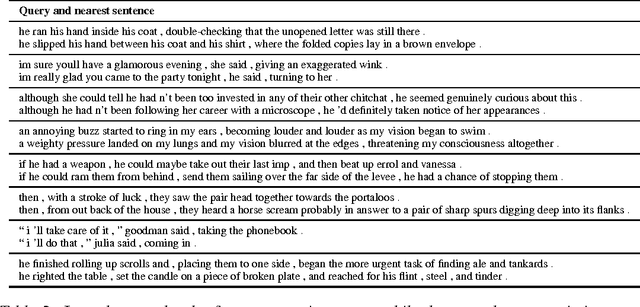
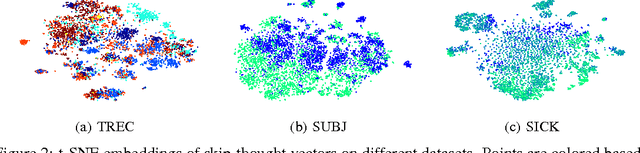

We describe an approach for unsupervised learning of a generic, distributed sentence encoder. Using the continuity of text from books, we train an encoder-decoder model that tries to reconstruct the surrounding sentences of an encoded passage. Sentences that share semantic and syntactic properties are thus mapped to similar vector representations. We next introduce a simple vocabulary expansion method to encode words that were not seen as part of training, allowing us to expand our vocabulary to a million words. After training our model, we extract and evaluate our vectors with linear models on 8 tasks: semantic relatedness, paraphrase detection, image-sentence ranking, question-type classification and 4 benchmark sentiment and subjectivity datasets. The end result is an off-the-shelf encoder that can produce highly generic sentence representations that are robust and perform well in practice. We will make our encoder publicly available.
Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books
Jun 22, 2015
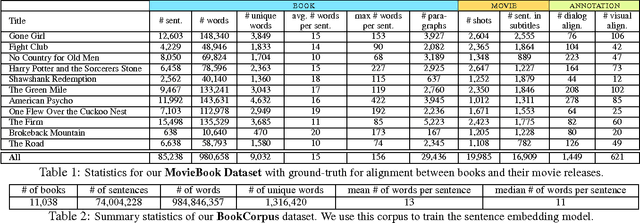


Books are a rich source of both fine-grained information, how a character, an object or a scene looks like, as well as high-level semantics, what someone is thinking, feeling and how these states evolve through a story. This paper aims to align books to their movie releases in order to provide rich descriptive explanations for visual content that go semantically far beyond the captions available in current datasets. To align movies and books we exploit a neural sentence embedding that is trained in an unsupervised way from a large corpus of books, as well as a video-text neural embedding for computing similarities between movie clips and sentences in the book. We propose a context-aware CNN to combine information from multiple sources. We demonstrate good quantitative performance for movie/book alignment and show several qualitative examples that showcase the diversity of tasks our model can be used for.