 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement-driven Security Analysis of Imperceptible Impersonation Attacks
Aug 26, 2020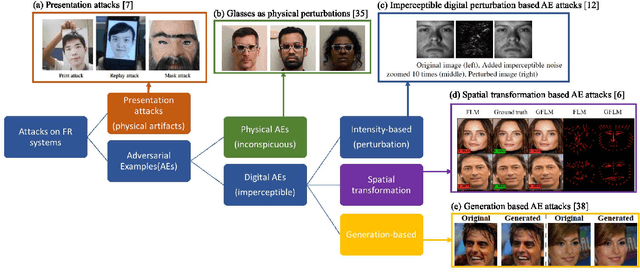

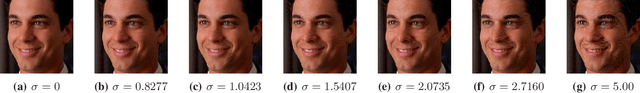

The emergence of Internet of Things (IoT) brings about new security challenges at the intersection of cyber and physical spaces. One prime example is the vulnerability of Face Recognition (FR) based access control in IoT systems. While previous research has shown that Deep Neural Network(DNN)-based FR systems (FRS) are potentially susceptible to imperceptible impersonation attacks, the potency of such attacks in a wide set of scenarios has not been thoroughly investigated. In this paper, we present the first systematic, wide-ranging measurement study of the exploitability of DNN-based FR systems using a large scale dataset. We find that arbitrary impersonation attacks, wherein an arbitrary attacker impersonates an arbitrary target, are hard if imperceptibility is an auxiliary goal. Specifically, we show that factors such as skin color, gender, and age, impact the ability to carry out an attack on a specific target victim, to different extents. We also study the feasibility of constructing universal attacks that are robust to different poses or views of the attacker's face. Our results show that finding a universal perturbation is a much harder problem from the attacker's perspective. Finally, we find that the perturbed images do not generalize well across different DNN models. This suggests security countermeasures that can dramatically reduce the exploitability of DNN-based FR systems.
Adversarial Knowledge Transfer from Unlabeled Data
Aug 13, 2020
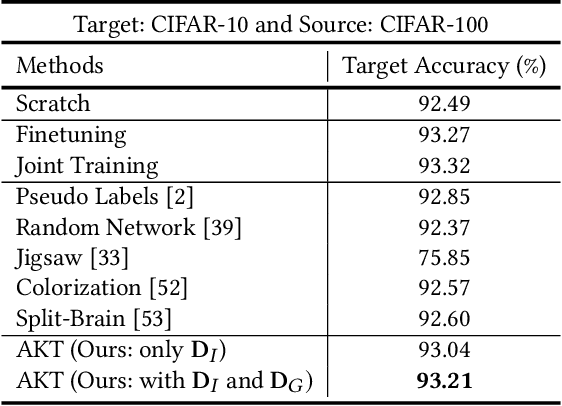
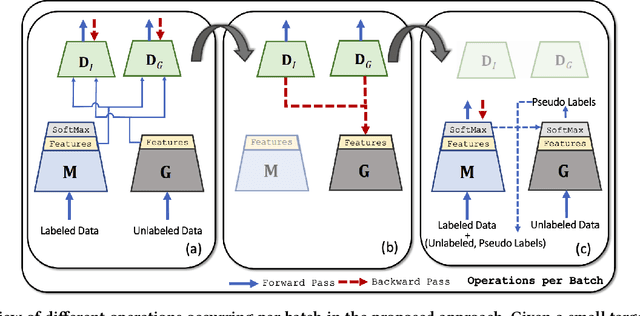
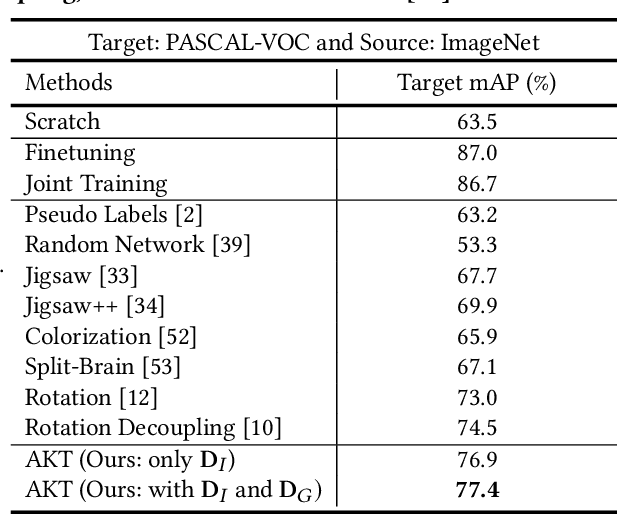
While machine learning approaches to visual recognition offer great promise, most of the existing methods rely heavily on the availability of large quantities of labeled training data. However, in the vast majority of real-world settings, manually collecting such large labeled datasets is infeasible due to the cost of labeling data or the paucity of data in a given domain. In this paper, we present a novel Adversarial Knowledge Transfer (AKT) framework for transferring knowledge from internet-scale unlabeled data to improve the performance of a classifier on a given visual recognition task. The proposed adversarial learning framework aligns the feature space of the unlabeled source data with the labeled target data such that the target classifier can be used to predict pseudo labels on the source data. An important novel aspect of our method is that the unlabeled source data can be of different classes from those of the labeled target data, and there is no need to define a separate pretext task, unlike some existing approaches. Extensive experiments well demonstrate that models learned using our approach hold a lot of promise across a variety of visual recognition tasks on multiple standard datasets.
Mitigating Dataset Imbalance via Joint Generation and Classification
Aug 12, 2020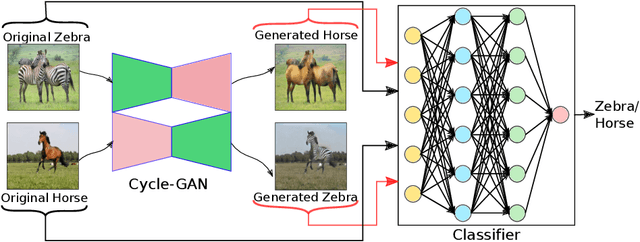
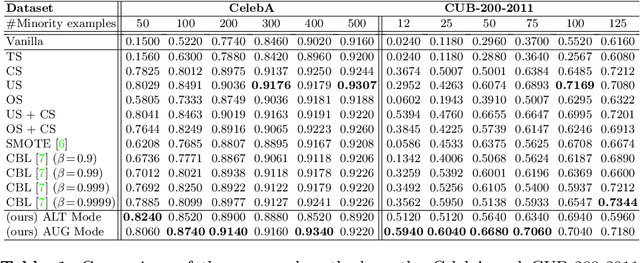
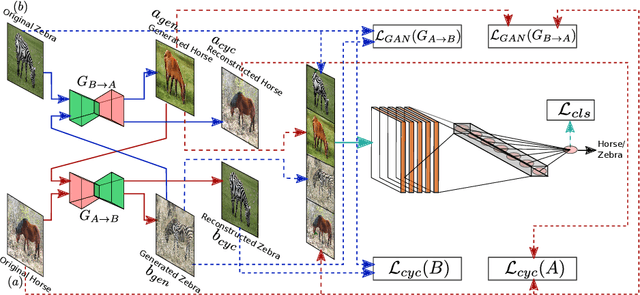
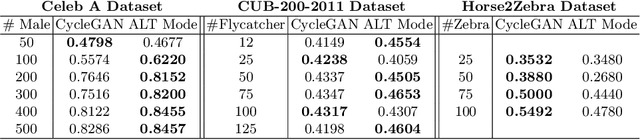
Supervised deep learning methods are enjoying enormous success in many practical applications of computer vision and have the potential to revolutionize robotics. However, the marked performance degradation to biases and imbalanced data questions the reliability of these methods. In this work we address these questions from the perspective of dataset imbalance resulting out of severe under-representation of annotated training data for certain classes and its effect on both deep classification and generation methods. We introduce a joint dataset repairment strategy by combining a neural network classifier with Generative Adversarial Networks (GAN) that makes up for the deficit of training examples from the under-representated class by producing additional training examples. We show that the combined training helps to improve the robustness of both the classifier and the GAN against severe class imbalance. We show the effectiveness of our proposed approach on three very different datasets with different degrees of imbalance in them. The code is available at https://github.com/AadSah/ImbalanceCycleGAN .
Camera On-boarding for Person Re-identification using Hypothesis Transfer Learning
Aug 05, 2020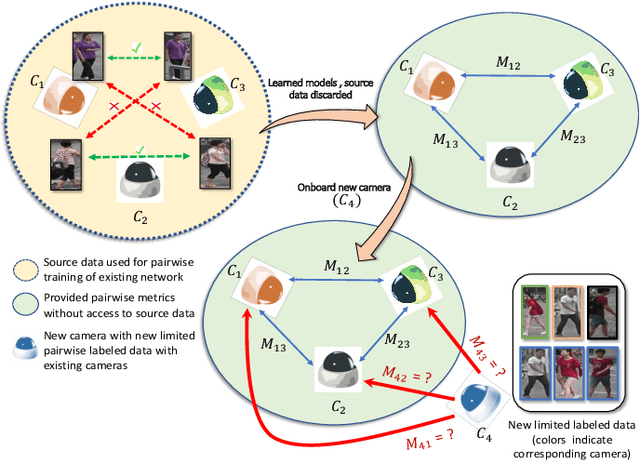
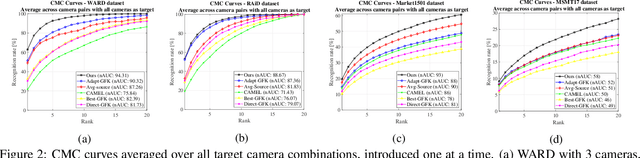
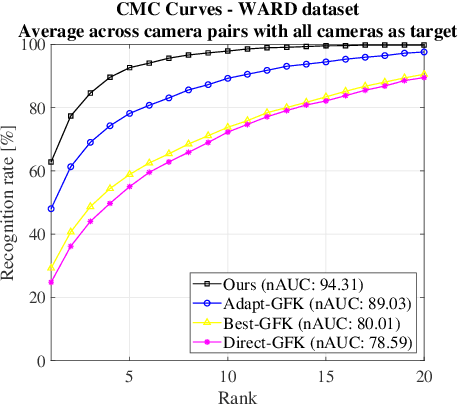
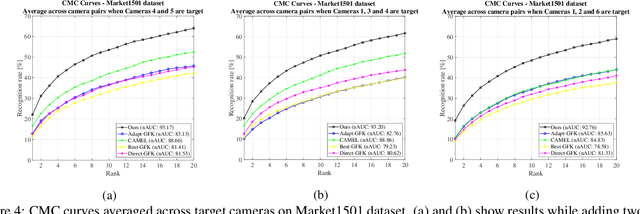
Most of the existing approaches for person re-identification consider a static setting where the number of cameras in the network is fixed. An interesting direction, which has received little attention, is to explore the dynamic nature of a camera network, where one tries to adapt the existing re-identification models after on-boarding new cameras, with little additional effort. There have been a few recent methods proposed in person re-identification that attempt to address this problem by assuming the labeled data in the existing network is still available while adding new cameras. This is a strong assumption since there may exist some privacy issues for which one may not have access to those data. Rather, based on the fact that it is easy to store the learned re-identifications models, which mitigates any data privacy concern, we develop an efficient model adaptation approach using hypothesis transfer learning that aims to transfer the knowledge using only source models and limited labeled data, but without using any source camera data from the existing network. Our approach minimizes the effect of negative transfer by finding an optimal weighted combination of multiple source models for transferring the knowledge. Extensive experiments on four challenging benchmark datasets with a variable number of cameras well demonstrate the efficacy of our proposed approach over state-of-the-art methods.
* Accepted to CVPR 2020
AR-Net: Adaptive Frame Resolution for Efficient Action Recognition
Jul 31, 2020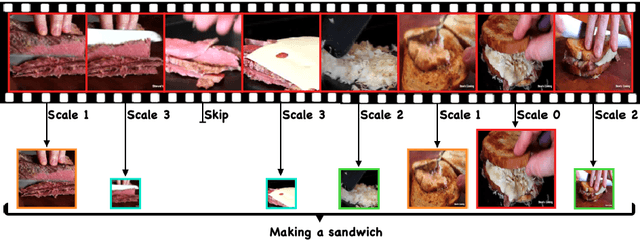
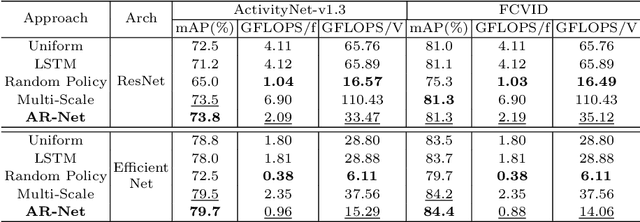

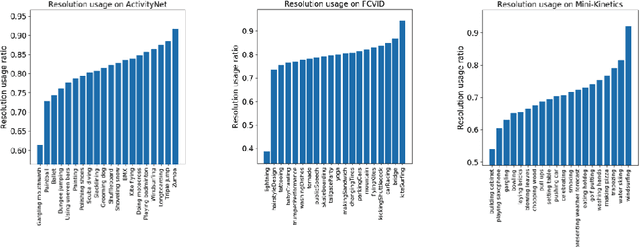
Action recognition is an open and challenging problem in computer vision. While current state-of-the-art models offer excellent recognition results, their computational expense limits their impact for many real-world applications. In this paper, we propose a novel approach, called AR-Net (Adaptive Resolution Network), that selects on-the-fly the optimal resolution for each frame conditioned on the input for efficient action recognition in long untrimmed videos. Specifically, given a video frame, a policy network is used to decide what input resolution should be used for processing by the action recognition model, with the goal of improving both accuracy and efficiency. We efficiently train the policy network jointly with the recognition model using standard back-propagation. Extensive experiments on several challenging action recognition benchmark datasets well demonstrate the efficacy of our proposed approach over state-of-the-art methods. The project page can be found at https://mengyuest.github.io/AR-Net
NASTransfer: Analyzing Architecture Transferability in Large Scale Neural Architecture Search
Jun 23, 2020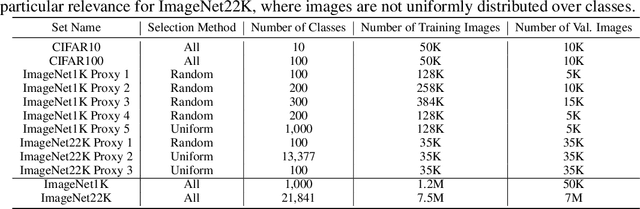
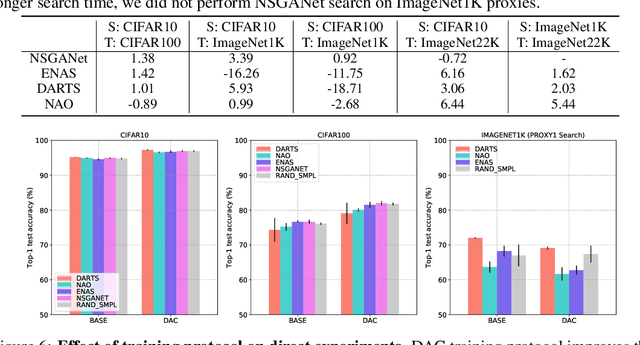
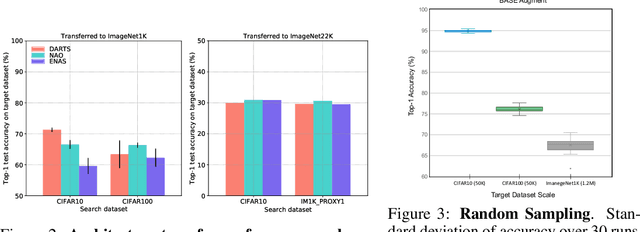
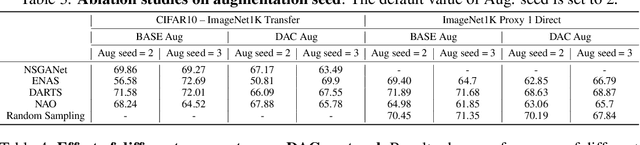
Neural Architecture Search (NAS) is an open and challenging problem in machine learning. While NAS offers great promise, the prohibitive computational demand of most of the existing NAS methods makes it difficult to directly search the architectures on large-scale tasks. The typical way of conducting large scale NAS is to search for an architectural building block on a small dataset (either using a proxy set from the large dataset or a completely different small scale dataset) and then transfer the block to a larger dataset. Despite a number of recent results that show the promise of transfer from proxy datasets, a comprehensive evaluation of different NAS methods studying the impact of different source datasets and training protocols has not yet been addressed. In this work, we propose to analyze the architecture transferability of different NAS methods by performing a series of experiments on large scale benchmarks such as ImageNet1K and ImageNet22K. We find that: (i) On average, transfer performance of architectures searched using completely different small datasets perform similarly to the architectures searched directly on proxy target datasets. However, design of proxy sets has considerable impact on rankings of different NAS methods. (ii) While the different NAS methods show similar performance on a source dataset (e.g., CIFAR10), they significantly differ on the transfer performance to a large dataset (e.g., ImageNet1K). (iii) Even on large datasets, the randomly sampled architecture baseline is very competitive and significantly outperforms many representative NAS methods. (iv) The training protocol has a larger impact on small datasets, but it fails to provide consistent improvements on large datasets. We believe that our NASTransfer benchmark will be key to designing future NAS strategies that consistently show superior transfer performance on large scale datasets.
Non-Adversarial Video Synthesis with Learned Priors
Apr 17, 2020
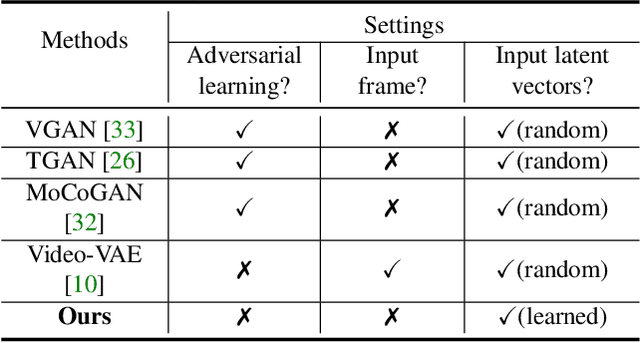
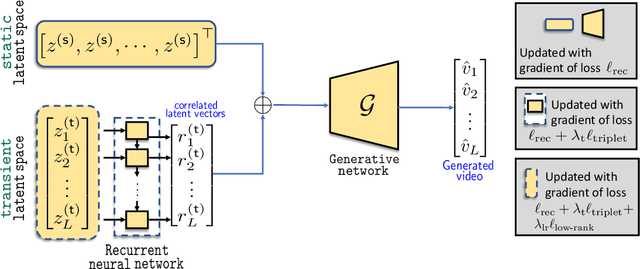

Most of the existing works in video synthesis focus on generating videos using adversarial learning. Despite their success, these methods often require input reference frame or fail to generate diverse videos from the given data distribution, with little to no uniformity in the quality of videos that can be generated. Different from these methods, we focus on the problem of generating videos from latent noise vectors, without any reference input frames. To this end, we develop a novel approach that jointly optimizes the input latent space, the weights of a recurrent neural network and a generator through non-adversarial learning. Optimizing for the input latent space along with the network weights allows us to generate videos in a controlled environment, i.e., we can faithfully generate all videos the model has seen during the learning process as well as new unseen videos. Extensive experiments on three challenging and diverse datasets well demonstrate that our approach generates superior quality videos compared to the existing state-of-the-art methods.
AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning
Nov 27, 2019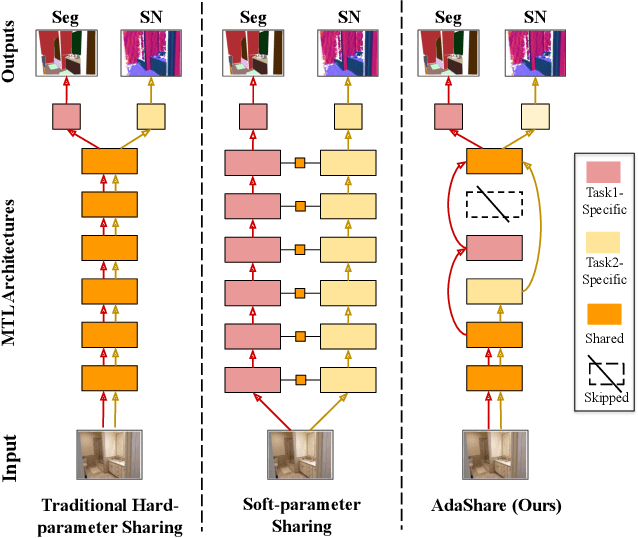
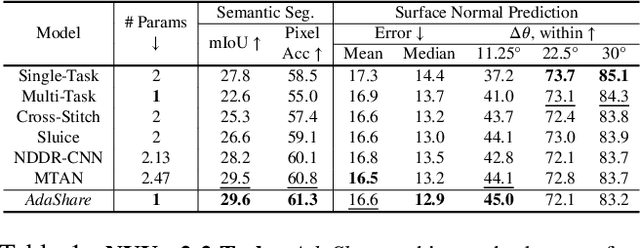
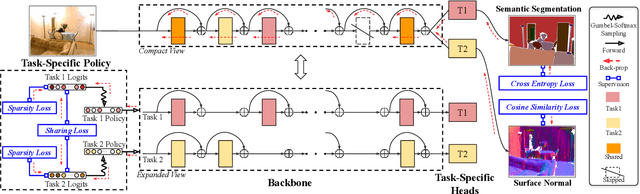
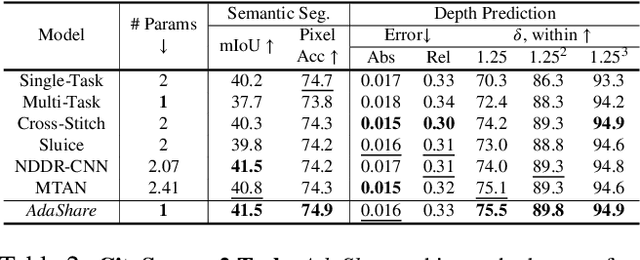
Multi-task learning is an open and challenging problem in computer vision. The typical way of conducting multi-task learning with deep neural networks is either through handcrafting schemes that share all initial layers and branch out at an adhoc point or through using separate task-specific networks with an additional feature sharing/fusion mechanism. Unlike existing methods, we propose an adaptive sharing approach, called AdaShare, that decides what to share across which tasks for achieving the best recognition accuracy, while taking resource efficiency into account. Specifically, our main idea is to learn the sharing pattern through a task-specific policy that selectively chooses which layers to execute for a given task in the multi-task network. We efficiently optimize the task-specific policy jointly with the network weights using standard back-propagation. Experiments on three challenging and diverse benchmark datasets with a variable number of tasks well demonstrate the efficacy of our approach over state-of-the-art methods.
Estimating Skin Tone and Effects on Classification Performance in Dermatology Datasets
Oct 29, 2019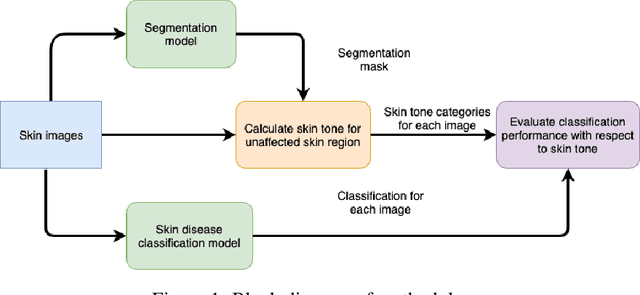
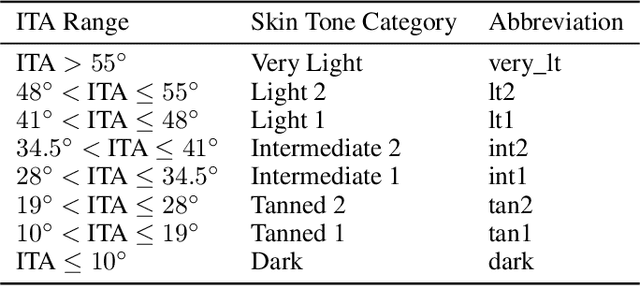
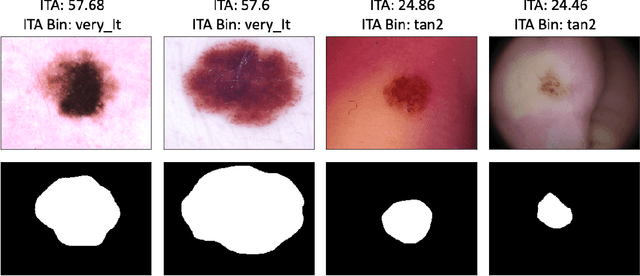

Recent advances in computer vision and deep learning have led to breakthroughs in the development of automated skin image analysis. In particular, skin cancer classification models have achieved performance higher than trained expert dermatologists. However, no attempt has been made to evaluate the consistency in performance of machine learning models across populations with varying skin tones. In this paper, we present an approach to estimate skin tone in benchmark skin disease datasets, and investigate whether model performance is dependent on this measure. Specifically, we use individual typology angle (ITA) to approximate skin tone in dermatology datasets. We look at the distribution of ITA values to better understand skin color representation in two benchmark datasets: 1) the ISIC 2018 Challenge dataset, a collection of dermoscopic images of skin lesions for the detection of skin cancer, and 2) the SD-198 dataset, a collection of clinical images capturing a wide variety of skin diseases. To estimate ITA, we first develop segmentation models to isolate non-diseased areas of skin. We find that the majority of the data in the the two datasets have ITA values between 34.5{\deg} and 48{\deg}, which are associated with lighter skin, and is consistent with under-representation of darker skinned populations in these datasets. We also find no measurable correlation between performance of machine learning model and ITA values, though more comprehensive data is needed for further validation.
Consistent Cross-view Matching for Unsupervised Person Re-identification
Aug 27, 2019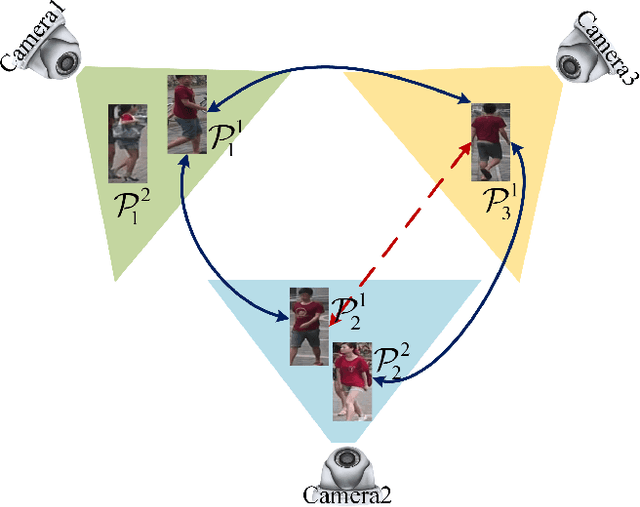
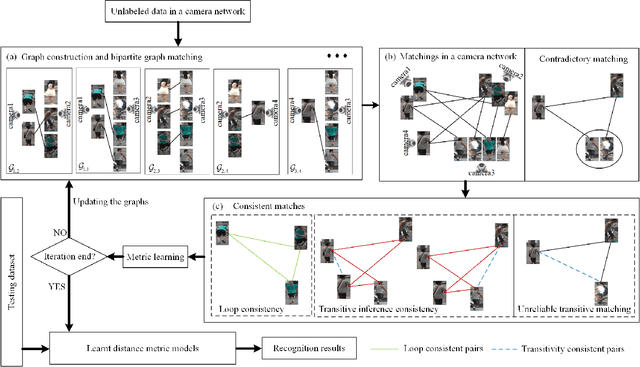
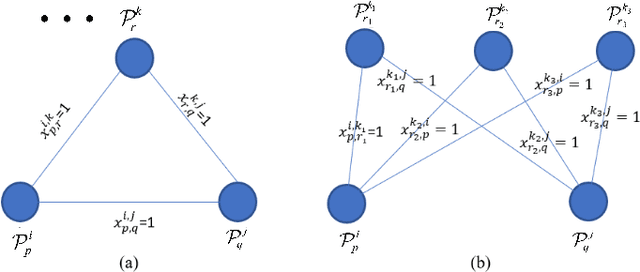
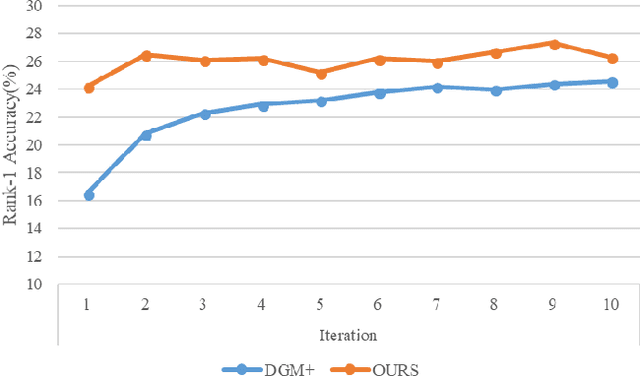
Most existing unsupervised person re-identificationmethods focus on learning an identity discriminative feature em-bedding for efficiently representing images of different persons.However, higher-order relationships across the entire cameranetwork are often ignored leading to contradictory outputs whenthe results of different camera pairs are combined. In this paper,we address this problem by proposing a consistent cross-viewmatching framework for unsupervised person re-identificationby exploiting more reliable positive image pairs in a cameranetwork. Specifically, we first construct a bipartite graph foreach pair of cameras, in which each node denotes a person, andthen graph matching is used to obtain optimal global matchesacross camera pairs. Thereafter, loop consistent and transitiveinference consistent constraints are introduced into the cross-view matches, which consider similarity relationshipsacross theentire camera networkto increase confidence in the matched/non-matched pairs. We then train distance metric models for eachcamera pair using the reliably matched image pairs. Finally,we embed the cross-view matching method into an iterativeupdating framework that iterates between the consistent cross-view matching and the cross-view distance metric learning. Wedemonstrate the superiority of the proposed method over thestate-of-the-art unsupervised person re-identification methodson three benchmark datasets such as Market1501, MARS andDukeMTMC-VideoReID datasets