 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoPeek: Information leakage reduction to share activations in distributed deep learning
Aug 20, 2020
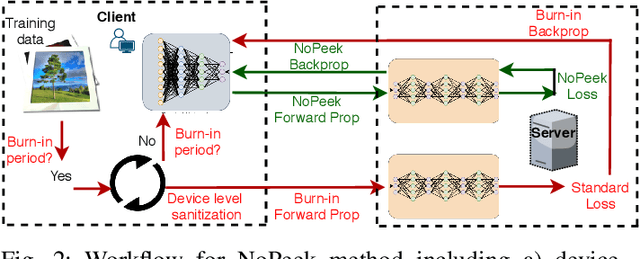
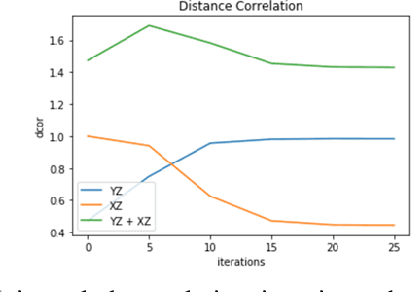
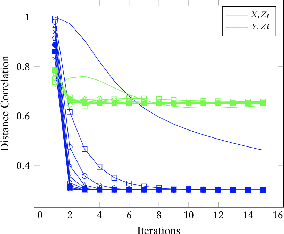
For distributed machine learning with sensitive data, we demonstrate how minimizing distance correlation between raw data and intermediary representations reduces leakage of sensitive raw data patterns across client communications while maintaining model accuracy. Leakage (measured using distance correlation between input and intermediate representations) is the risk associated with the invertibility of raw data from intermediary representations. This can prevent client entities that hold sensitive data from using distributed deep learning services. We demonstrate that our method is resilient to such reconstruction attacks and is based on reduction of distance correlation between raw data and learned representations during training and inference with image datasets. We prevent such reconstruction of raw data while maintaining information required to sustain good classification accuracies.
SplitNN-driven Vertical Partitioning
Aug 07, 2020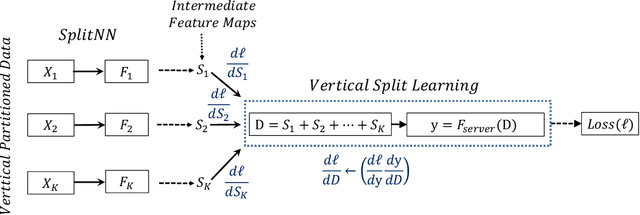
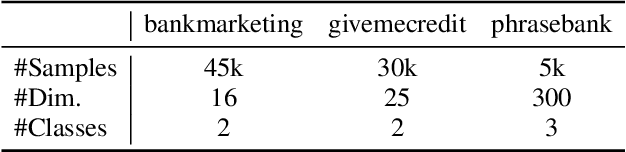
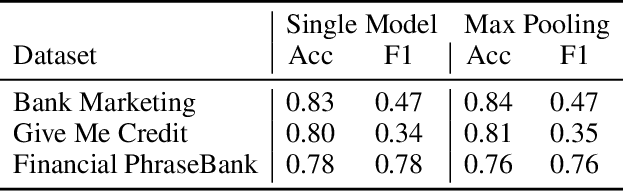
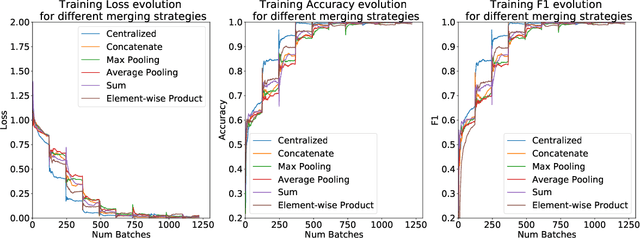
In this work, we introduce SplitNN-driven Vertical Partitioning, a configuration of a distributed deep learning method called SplitNN to facilitate learning from vertically distributed features. SplitNN does not share raw data or model details with collaborating institutions. The proposed configuration allows training among institutions holding diverse sources of data without the need of complex encryption algorithms or secure computation protocols. We evaluate several configurations to merge the outputs of the split models, and compare performance and resource efficiency. The method is flexible and allows many different configurations to tackle the specific challenges posed by vertically split datasets.
FedML: A Research Library and Benchmark for Federated Machine Learning
Jul 27, 2020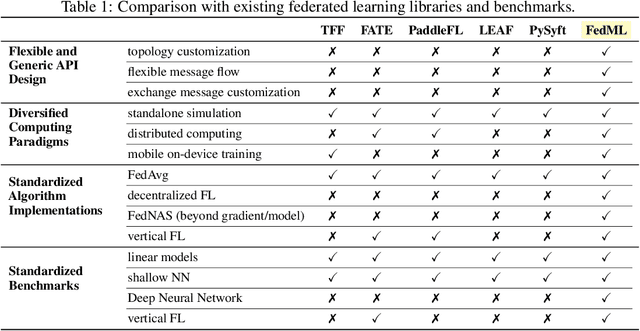
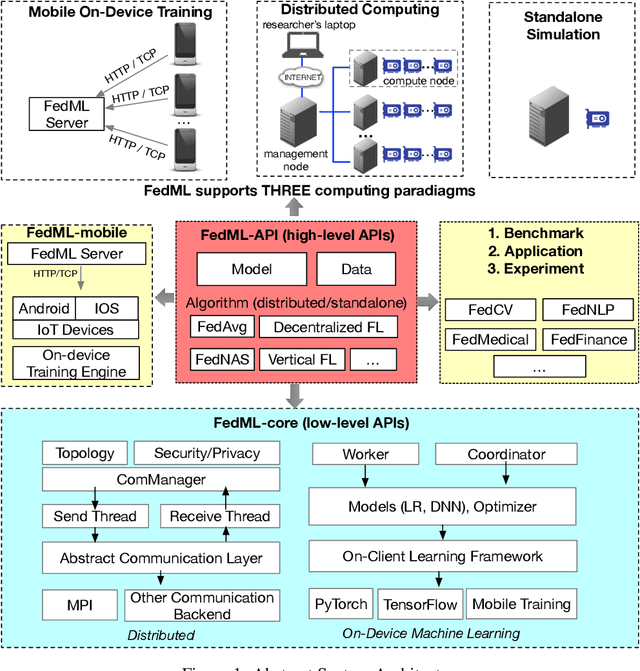


Federated learning is a rapidly growing research field in the machine learning domain. Although considerable research efforts have been made, existing libraries cannot adequately support diverse algorithmic development (e.g., diverse topology and flexible message exchange), and inconsistent dataset and model usage in experiments make fair comparisons difficult. In this work, we introduce FedML, an open research library and benchmark that facilitates the development of new federated learning algorithms and fair performance comparisons. FedML supports three computing paradigms (distributed training, mobile on-device training, and standalone simulation) for users to conduct experiments in different system environments. FedML also promotes diverse algorithmic research with flexible and generic API design and reference baseline implementations. A curated and comprehensive benchmark dataset for the non-I.I.D setting aims at making a fair comparison. We believe FedML can provide an efficient and reproducible means of developing and evaluating algorithms for the federated learning research community. We maintain the source code, documents, and user community at https://FedML.ai.
Splintering with distributions: A stochastic decoy scheme for private computation
Jul 07, 2020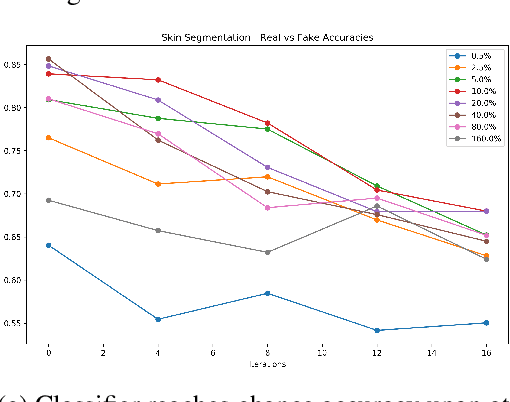

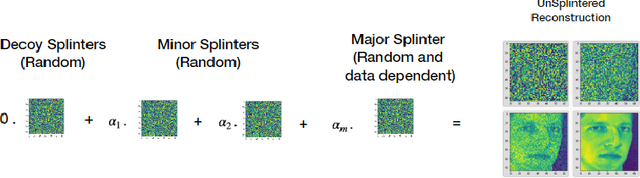
Performing computations while maintaining privacy is an important problem in todays distributed machine learning solutions. Consider the following two set ups between a client and a server, where in setup i) the client has a public data vector $\mathbf{x}$, the server has a large private database of data vectors $\mathcal{B}$ and the client wants to find the inner products $\langle \mathbf{x,y_k} \rangle, \forall \mathbf{y_k} \in \mathcal{B}$. The client does not want the server to learn $\mathbf{x}$ while the server does not want the client to learn the records in its database. This is in contrast to another setup ii) where the client would like to perform an operation solely on its data, such as computation of a matrix inverse on its data matrix $\mathbf{M}$, but would like to use the superior computing ability of the server to do so without having to leak $\mathbf{M}$ to the server. \par We present a stochastic scheme for splitting the client data into privatized shares that are transmitted to the server in such settings. The server performs the requested operations on these shares instead of on the raw client data at the server. The obtained intermediate results are sent back to the client where they are assembled by the client to obtain the final result.
Automatic Differentiation for All Photons Imaging to See Inside Volumetric Scattering Media
Jun 02, 2020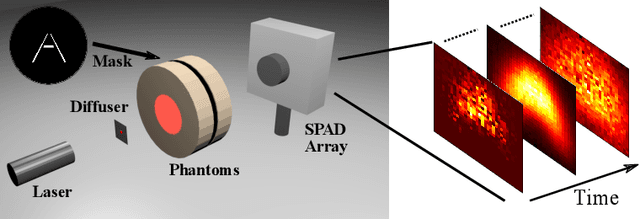
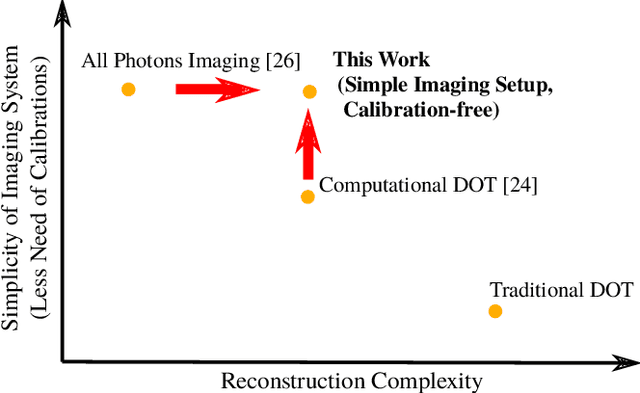
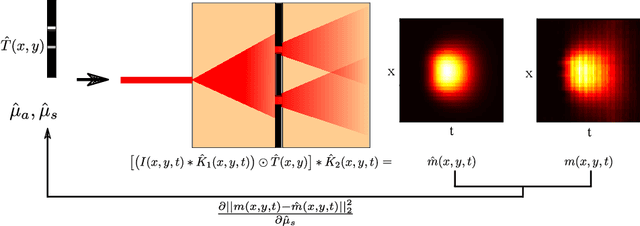
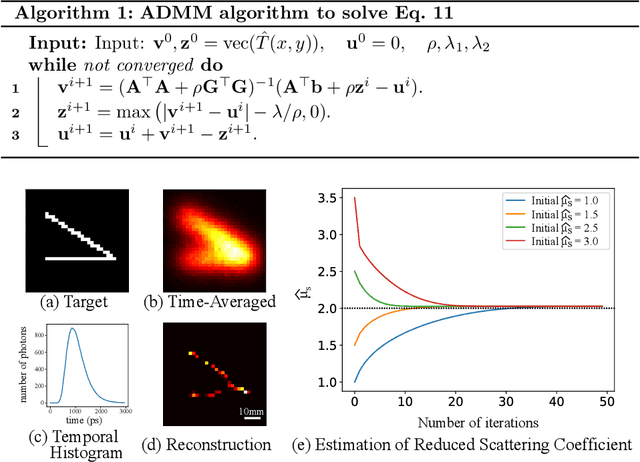
Imaging through dense scattering media - such as biological tissue, fog, and smoke - has applications in the medical and robotics fields. We propose a new framework using automatic differentiation for All Photons Imaging through homogeneous scattering media with unknown optical properties for non-invasive sensing and diagnostics. We overcome the need for the imaging target to be visible to the illumination source in All Photons Imaging, enabling practical and non-invasive imaging through turbid media with a simple optical setup. Our method does not require calibration to acquire the sensor position or optical properties of the media.
Privacy in Deep Learning: A Survey
May 09, 2020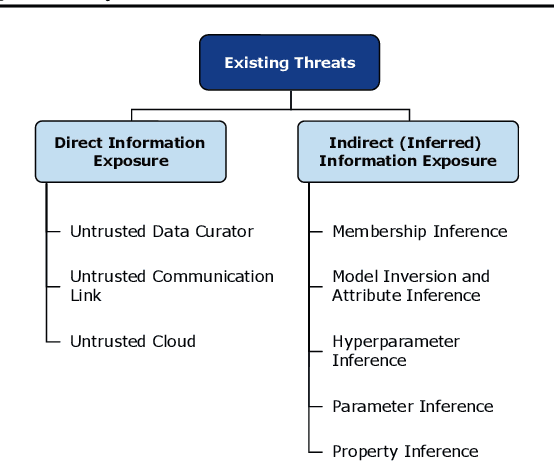


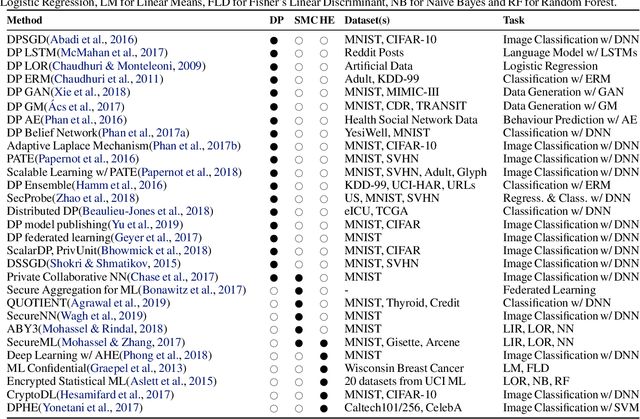
The ever-growing advances of deep learning in many areas including vision, recommendation systems, natural language processing, etc., have led to the adoption of Deep Neural Networks (DNNs) in production systems. The availability of large datasets and high computational power are the main contributors to these advances. The datasets are usually crowdsourced and may contain sensitive information. This poses serious privacy concerns as this data can be misused or leaked through various vulnerabilities. Even if the cloud provider and the communication link is trusted, there are still threats of inference attacks where an attacker could speculate properties of the data used for training, or find the underlying model architecture and parameters. In this survey, we review the privacy concerns brought by deep learning, and the mitigating techniques introduced to tackle these issues. We also show that there is a gap in the literature regarding test-time inference privacy, and propose possible future research directions.
Privacy Guidelines for Contact Tracing Applications
Apr 28, 2020Contact tracing is a very powerful method to implement and enforce social distancing to avoid spreading of infectious diseases. The traditional approach of contact tracing is time consuming, manpower intensive, dangerous and prone to error due to fatigue or lack of skill. Due to this there is an emergence of mobile based applications for contact tracing. These applications primarily utilize a combination of GPS based absolute location and Bluetooth based relative location remitted from user's smartphone to infer various insights. These applications have eased the task of contact tracing; however, they also have severe implication on user's privacy, for example, mass surveillance, personal information leakage and additionally revealing the behavioral patterns of the user. This impact on user's privacy leads to trust deficit in these applications, and hence defeats their purpose. In this work we discuss the various scenarios which a contact tracing application should be able to handle. We highlight the privacy handling of some of the prominent contact tracing applications. Additionally, we describe the various threat actors who can disrupt its working, or misuse end user's data, or hamper its mass adoption. Finally, we present privacy guidelines for contact tracing applications from different stakeholder's perspective. To best of our knowledge, this is the first generic work which provides privacy guidelines for contact tracing applications.
Split Learning for collaborative deep learning in healthcare
Dec 27, 2019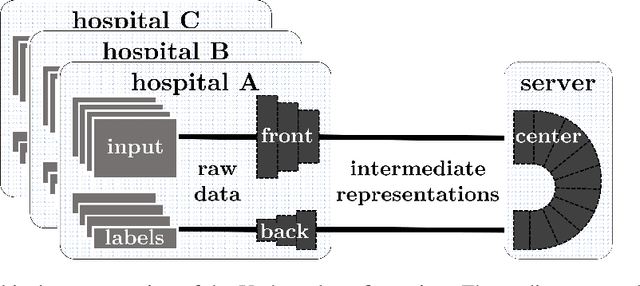
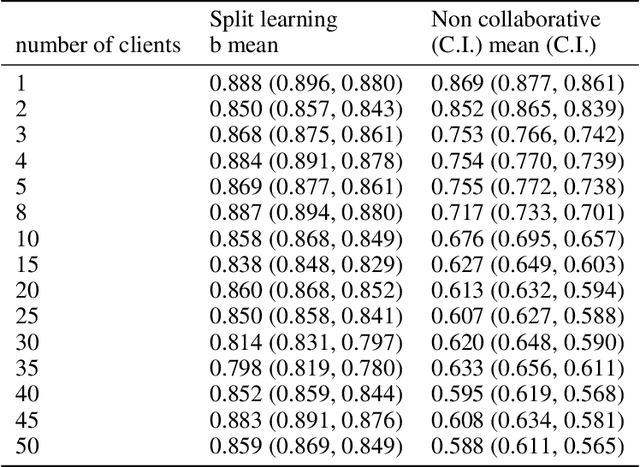
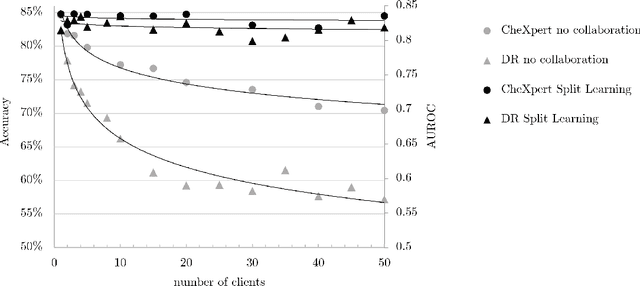
Shortage of labeled data has been holding the surge of deep learning in healthcare back, as sample sizes are often small, patient information cannot be shared openly, and multi-center collaborative studies are a burden to set up. Distributed machine learning methods promise to mitigate these problems. We argue for a split learning based approach and apply this distributed learning method for the first time in the medical field to compare performance against (1) centrally hosted and (2) non collaborative configurations for a range of participants. Two medical deep learning tasks are used to compare split learning to conventional single and multi center approaches: a binary classification problem of a data set of 9000 fundus photos, and multi-label classification problem of a data set of 156,535 chest X-rays. The several distributed learning setups are compared for a range of 1-50 distributed participants. Performance of the split learning configuration remained constant for any number of clients compared to a single center study, showing a marked difference compared to the non collaborative configuration after 2 clients (p < 0.001) for both sets. Our results affirm the benefits of collaborative training of deep neural networks in health care. Our work proves the significant benefit of distributed learning in healthcare, and paves the way for future real-world implementations.
Advances and Open Problems in Federated Learning
Dec 10, 2019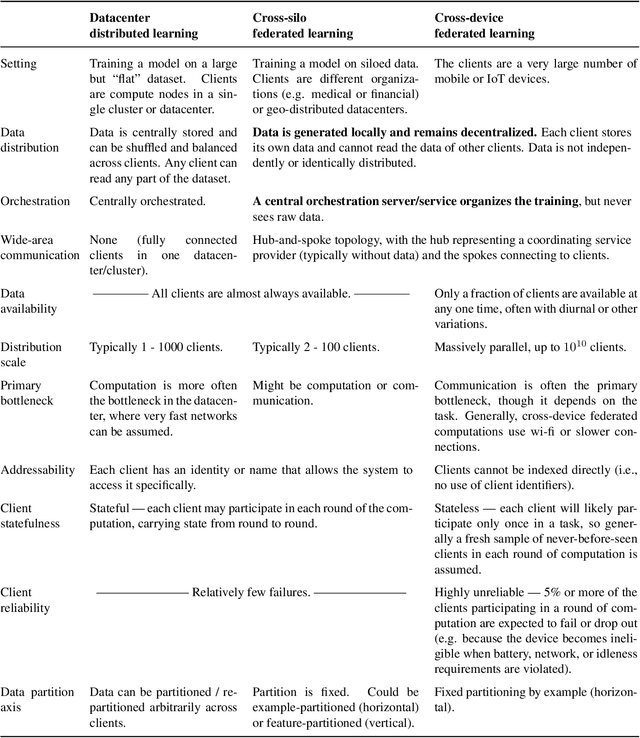
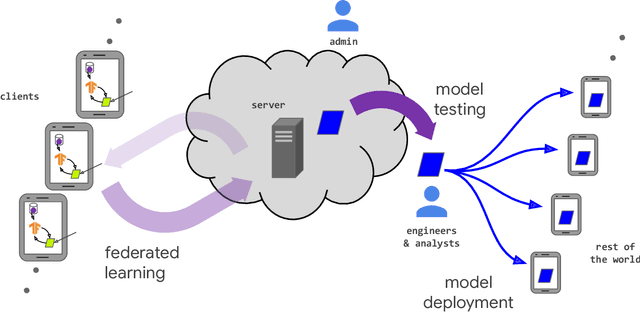
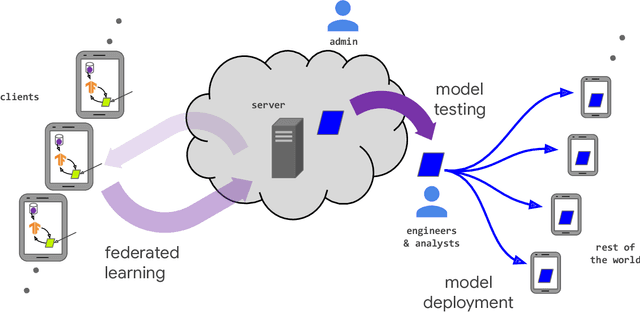

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Recent Advances in Imaging Around Corners
Oct 12, 2019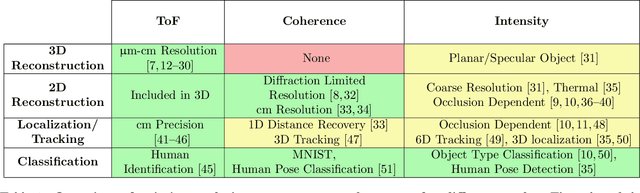
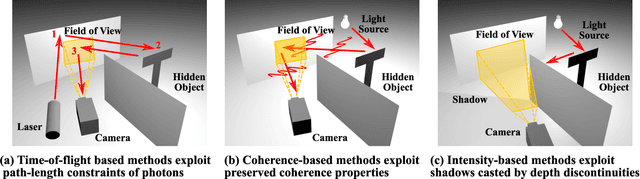
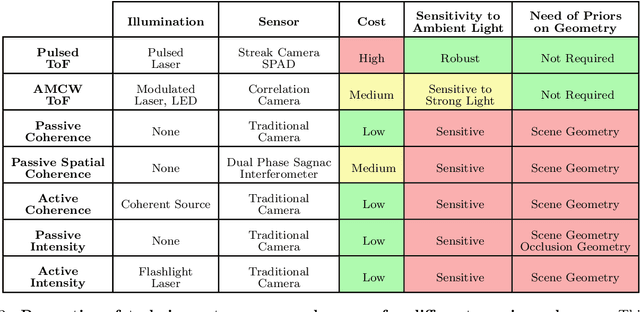
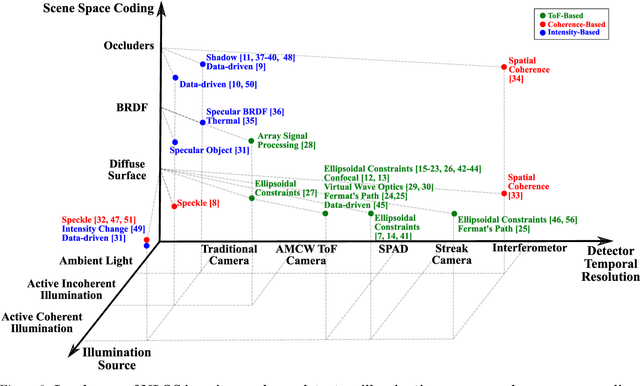
Seeing around corners, also known as non-line-of-sight (NLOS) imaging is a computational method to resolve or recover objects hidden around corners. Recent advances in imaging around corners have gained significant interest. This paper reviews different types of existing NLOS imaging techniques and discusses the challenges that need to be addressed, especially for their applications outside of a constrained laboratory environment. Our goal is to introduce this topic to broader research communities as well as provide insights that would lead to further developments in this research area.