 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Scene Understanding: Grounded Situation Recognition Meets Segment Anything for Helping People with Visual Impairments
Jul 15, 2023



Grounded Situation Recognition (GSR) is capable of recognizing and interpreting visual scenes in a contextually intuitive way, yielding salient activities (verbs) and the involved entities (roles) depicted in images. In this work, we focus on the application of GSR in assisting people with visual impairments (PVI). However, precise localization information of detected objects is often required to navigate their surroundings confidently and make informed decisions. For the first time, we propose an Open Scene Understanding (OpenSU) system that aims to generate pixel-wise dense segmentation masks of involved entities instead of bounding boxes. Specifically, we build our OpenSU system on top of GSR by additionally adopting an efficient Segment Anything Model (SAM). Furthermore, to enhance the feature extraction and interaction between the encoder-decoder structure, we construct our OpenSU system using a solid pure transformer backbone to improve the performance of GSR. In order to accelerate the convergence, we replace all the activation functions within the GSR decoders with GELU, thereby reducing the training duration. In quantitative analysis, our model achieves state-of-the-art performance on the SWiG dataset. Moreover, through field testing on dedicated assistive technology datasets and application demonstrations, the proposed OpenSU system can be used to enhance scene understanding and facilitate the independent mobility of people with visual impairments. Our code will be available at https://github.com/RuipingL/OpenSU.
Tightly-Coupled LiDAR-Visual SLAM Based on Geometric Features for Mobile Agents
Jul 15, 2023The mobile robot relies on SLAM (Simultaneous Localization and Mapping) to provide autonomous navigation and task execution in complex and unknown environments. However, it is hard to develop a dedicated algorithm for mobile robots due to dynamic and challenging situations, such as poor lighting conditions and motion blur. To tackle this issue, we propose a tightly-coupled LiDAR-visual SLAM based on geometric features, which includes two sub-systems (LiDAR and monocular visual SLAM) and a fusion framework. The fusion framework associates the depth and semantics of the multi-modal geometric features to complement the visual line landmarks and to add direction optimization in Bundle Adjustment (BA). This further constrains visual odometry. On the other hand, the entire line segment detected by the visual subsystem overcomes the limitation of the LiDAR subsystem, which can only perform the local calculation for geometric features. It adjusts the direction of linear feature points and filters out outliers, leading to a higher accurate odometry system. Finally, we employ a module to detect the subsystem's operation, providing the LiDAR subsystem's output as a complementary trajectory to our system while visual subsystem tracking fails. The evaluation results on the public dataset M2DGR, gathered from ground robots across various indoor and outdoor scenarios, show that our system achieves more accurate and robust pose estimation compared to current state-of-the-art multi-modal methods.
Line Graphics Digitization: A Step Towards Full Automation
Jul 05, 2023The digitization of documents allows for wider accessibility and reproducibility. While automatic digitization of document layout and text content has been a long-standing focus of research, this problem in regard to graphical elements, such as statistical plots, has been under-explored. In this paper, we introduce the task of fine-grained visual understanding of mathematical graphics and present the Line Graphics (LG) dataset, which includes pixel-wise annotations of 5 coarse and 10 fine-grained categories. Our dataset covers 520 images of mathematical graphics collected from 450 documents from different disciplines. Our proposed dataset can support two different computer vision tasks, i.e., semantic segmentation and object detection. To benchmark our LG dataset, we explore 7 state-of-the-art models. To foster further research on the digitization of statistical graphs, we will make the dataset, code, and models publicly available to the community.
Accurate Fine-Grained Segmentation of Human Anatomy in Radiographs via Volumetric Pseudo-Labeling
Jun 06, 2023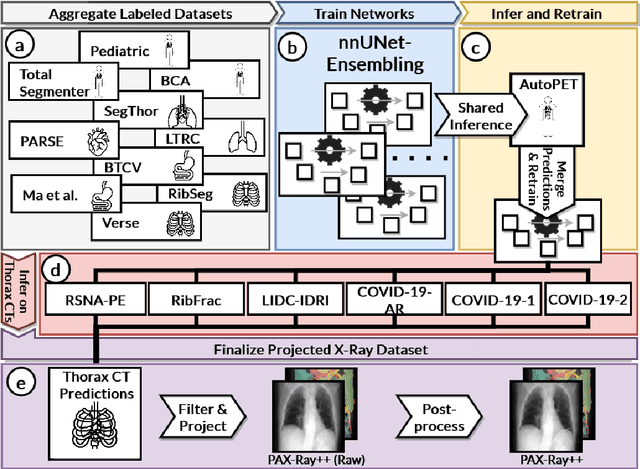


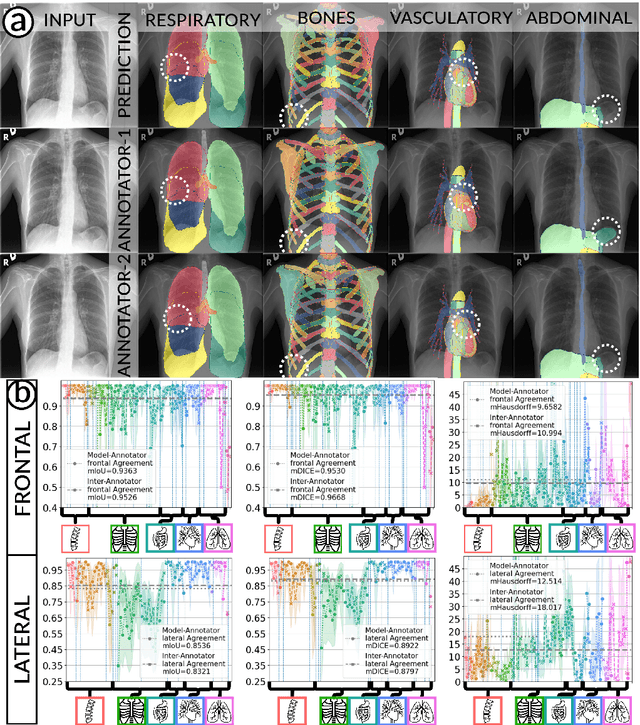
Purpose: Interpreting chest radiographs (CXR) remains challenging due to the ambiguity of overlapping structures such as the lungs, heart, and bones. To address this issue, we propose a novel method for extracting fine-grained anatomical structures in CXR using pseudo-labeling of three-dimensional computed tomography (CT) scans. Methods: We created a large-scale dataset of 10,021 thoracic CTs with 157 labels and applied an ensemble of 3D anatomy segmentation models to extract anatomical pseudo-labels. These labels were projected onto a two-dimensional plane, similar to the CXR, allowing the training of detailed semantic segmentation models for CXR without any manual annotation effort. Results: Our resulting segmentation models demonstrated remarkable performance on CXR, with a high average model-annotator agreement between two radiologists with mIoU scores of 0.93 and 0.85 for frontal and lateral anatomy, while inter-annotator agreement remained at 0.95 and 0.83 mIoU. Our anatomical segmentations allowed for the accurate extraction of relevant explainable medical features such as the cardio-thoracic-ratio. Conclusion: Our method of volumetric pseudo-labeling paired with CT projection offers a promising approach for detailed anatomical segmentation of CXR with a high agreement with human annotators. This technique may have important clinical implications, particularly in the analysis of various thoracic pathologies.
READMem: Robust Embedding Association for a Diverse Memory in Unconstrained Video Object Segmentation
May 22, 2023We present READMem (Robust Embedding Association for a Diverse Memory), a modular framework for semi-automatic video object segmentation (sVOS) methods designed to handle unconstrained videos. Contemporary sVOS works typically aggregate video frames in an ever-expanding memory, demanding high hardware resources for long-term applications. To mitigate memory requirements and prevent near object duplicates (caused by information of adjacent frames), previous methods introduce a hyper-parameter that controls the frequency of frames eligible to be stored. This parameter has to be adjusted according to concrete video properties (such as rapidity of appearance changes and video length) and does not generalize well. Instead, we integrate the embedding of a new frame into the memory only if it increases the diversity of the memory content. Furthermore, we propose a robust association of the embeddings stored in the memory with query embeddings during the update process. Our approach avoids the accumulation of redundant data, allowing us in return, to restrict the memory size and prevent extreme memory demands in long videos. We extend popular sVOS baselines with READMem, which previously showed limited performance on long videos. Our approach achieves competitive results on the Long-time Video dataset (LV1) while not hindering performance on short sequences. Our code is publicly available.
FeatFSDA: Towards Few-shot Domain Adaptation for Video-based Activity Recognition
May 15, 2023Domain adaptation is essential for activity recognition, as common spatiotemporal architectures risk overfitting due to increased parameters arising from the temporal dimension. Unsupervised domain adaptation methods have been extensively studied, yet, they require large-scale unlabeled data from the target domain. In this work, we address few-shot domain adaptation for video-based activity recognition (FSDA-AR), which leverages a very small amount of labeled target videos to achieve effective adaptation. This setting is attractive and promising for applications, as it requires recording and labeling only a few, or even a single example per class in the target domain, which often includes activities that are rare yet crucial to recognize. We construct FSDA-AR benchmarks using five established datasets: UCF101, HMDB51, EPIC-KITCHEN, Sims4Action, and Toyota Smart Home. Our results demonstrate that FSDA-AR performs comparably to unsupervised domain adaptation with significantly fewer (yet labeled) target examples. We further propose a novel approach, FeatFSDA, to better leverage the few labeled target domain samples as knowledge guidance. FeatFSDA incorporates a latent space semantic adjacency loss, a domain prototypical similarity loss, and a graph-attentive-network-based edge dropout technique. Our approach achieves state-of-the-art performance on all datasets within our FSDA-AR benchmark. To encourage future research of few-shot domain adaptation for video-based activity recognition, we will release our benchmarks and code at https://github.com/KPeng9510/FeatFSDA.
FishDreamer: Towards Fisheye Semantic Completion via Unified Image Outpainting and Segmentation
Mar 24, 2023



This paper raises the new task of Fisheye Semantic Completion (FSC), where dense texture, structure, and semantics of a fisheye image are inferred even beyond the sensor field-of-view (FoV). Fisheye cameras have larger FoV than ordinary pinhole cameras, yet its unique special imaging model naturally leads to a blind area at the edge of the image plane. This is suboptimal for safety-critical applications since important perception tasks, such as semantic segmentation, become very challenging within the blind zone. Previous works considered the out-FoV outpainting and in-FoV segmentation separately. However, we observe that these two tasks are actually closely coupled. To jointly estimate the tightly intertwined complete fisheye image and scene semantics, we introduce the new FishDreamer which relies on successful ViTs enhanced with a novel Polar-aware Cross Attention module (PCA) to leverage dense context and guide semantically-consistent content generation while considering different polar distributions. In addition to the contribution of the novel task and architecture, we also derive Cityscapes-BF and KITTI360-BF datasets to facilitate training and evaluation of this new track. Our experiments demonstrate that the proposed FishDreamer outperforms methods solving each task in isolation and surpasses alternative approaches on the Fisheye Semantic Completion. Code and datasets will be available at https://github.com/MasterHow/FishDreamer.
360BEV: Panoramic Semantic Mapping for Indoor Bird's-Eye View
Mar 22, 2023



Seeing only a tiny part of the whole is not knowing the full circumstance. Bird's-eye-view (BEV) perception, a process of obtaining allocentric maps from egocentric views, is restricted when using a narrow Field of View (FoV) alone. In this work, mapping from 360{\deg} panoramas to BEV semantics, the 360BEV task, is established for the first time to achieve holistic representations of indoor scenes in a top-down view. Instead of relying on narrow-FoV image sequences, a panoramic image with depth information is sufficient to generate a holistic BEV semantic map. To benchmark 360BEV, we present two indoor datasets, 360BEV-Matterport and 360BEV-Stanford, both of which include egocentric panoramic images and semantic segmentation labels, as well as allocentric semantic maps. Besides delving deep into different mapping paradigms, we propose a dedicated solution for panoramic semantic mapping, namely 360Mapper. Through extensive experiments, our methods achieve 44.32% and 45.78% in mIoU on both datasets respectively, surpassing previous counterparts with gains of +7.60% and +9.70% in mIoU. Code and datasets will be available at: https://jamycheung.github.io/360BEV.html.
MuscleMap: Towards Video-based Activated Muscle Group Estimation
Mar 17, 2023



In this paper, we tackle the new task of video-based Activated Muscle Group Estimation (AMGE) aiming at identifying active muscle regions during physical activity. To this intent, we provide the MuscleMap136 dataset featuring >15K video clips with 136 different activities and 20 labeled muscle groups. This dataset opens the vistas to multiple video-based applications in sports and rehabilitation medicine. We further complement the main MuscleMap136 dataset, which specifically targets physical exercise, with Muscle-UCF90 and Muscle-HMDB41, which are new variants of the well-known activity recognition benchmarks extended with AMGE annotations. To make the AMGE model applicable in real-life situations, it is crucial to ensure that the model can generalize well to types of physical activities not present during training and involving new combinations of activated muscles. To achieve this, our benchmark also covers an evaluation setting where the model is exposed to activity types excluded from the training set. Our experiments reveal that generalizability of existing architectures adapted for the AMGE task remains a challenge. Therefore, we also propose a new approach, TransM3E, which employs a transformer-based model with cross-modal multi-label knowledge distillation and surpasses all popular video classification models when dealing with both, previously seen and new types of physical activities. The datasets and code will be publicly available at https://github.com/KPeng9510/MuscleMap.
Mirror U-Net: Marrying Multimodal Fission with Multi-task Learning for Semantic Segmentation in Medical Imaging
Mar 13, 2023



Positron Emission Tomography (PET) and Computer Tomography (CT) are routinely used together to detect tumors. PET/CT segmentation models can automate tumor delineation, however, current multimodal models do not fully exploit the complementary information in each modality, as they either concatenate PET and CT data or fuse them at the decision level. To combat this, we propose Mirror U-Net, which replaces traditional fusion methods with multimodal fission by factorizing the multimodal representation into modality-specific branches and an auxiliary multimodal decoder. At these branches, Mirror U-Net assigns a task tailored to each modality to reinforce unimodal features while preserving multimodal features in the shared representation. In contrast to previous methods that use either fission or multi-task learning, Mirror U-Net combines both paradigms in a unified framework. We explore various task combinations and examine which parameters to share in the model. We evaluate Mirror U-Net on the AutoPET PET/CT and on the multimodal MSD BrainTumor datasets, demonstrating its effectiveness in multimodal segmentation and achieving state-of-the-art performance on both datasets. Our code will be made publicly available.