 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Model Jitter: Stable Re-training of Semantic Parsers in Production Environments
Apr 10, 2022
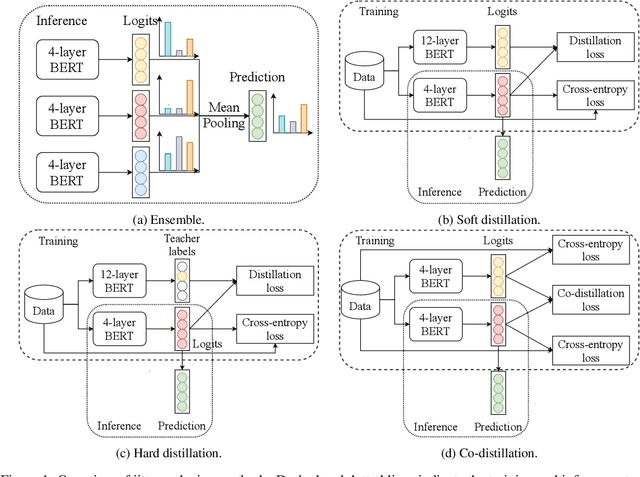
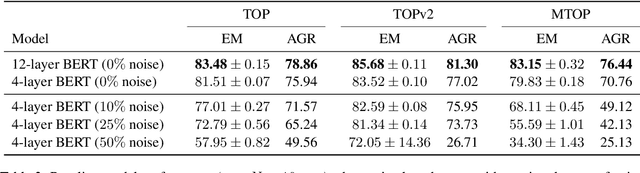
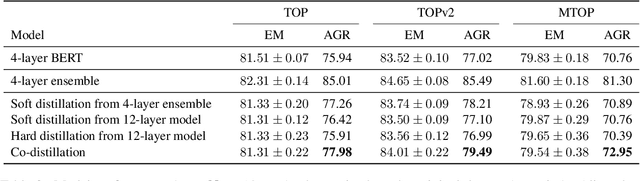
Retraining modern deep learning systems can lead to variations in model performance even when trained using the same data and hyper-parameters by simply using different random seeds. We call this phenomenon model jitter. This issue is often exacerbated in production settings, where models are retrained on noisy data. In this work we tackle the problem of stable retraining with a focus on conversational semantic parsers. We first quantify the model jitter problem by introducing the model agreement metric and showing the variation with dataset noise and model sizes. We then demonstrate the effectiveness of various jitter reduction techniques such as ensembling and distillation. Lastly, we discuss practical trade-offs between such techniques and show that co-distillation provides a sweet spot in terms of jitter reduction for semantic parsing systems with only a modest increase in resource usage.
TableFormer: Robust Transformer Modeling for Table-Text Encoding
Mar 01, 2022
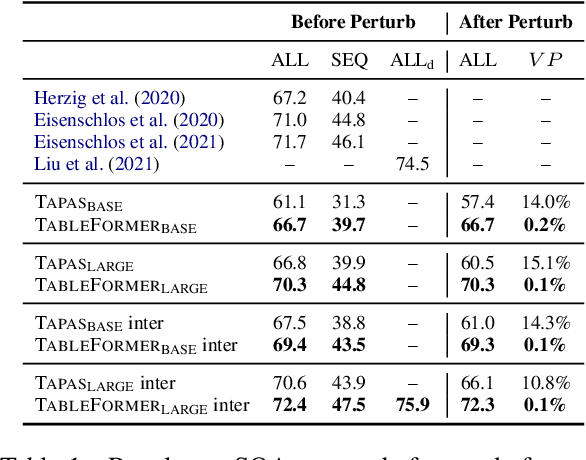
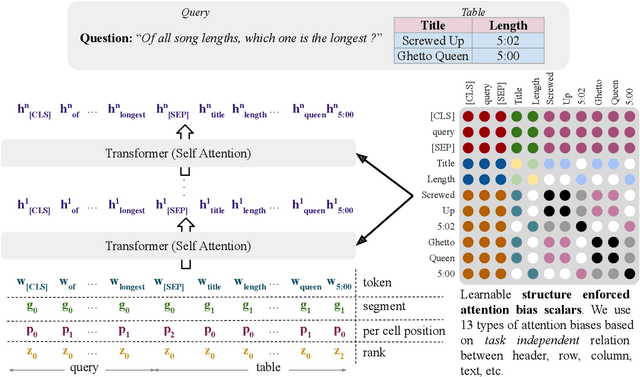
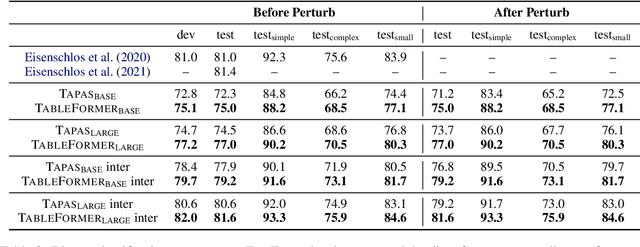
Understanding tables is an important aspect of natural language understanding. Existing models for table understanding require linearization of the table structure, where row or column order is encoded as an unwanted bias. Such spurious biases make the model vulnerable to row and column order perturbations. Additionally, prior work has not thoroughly modeled the table structures or table-text alignments, hindering the table-text understanding ability. In this work, we propose a robust and structurally aware table-text encoding architecture TableFormer, where tabular structural biases are incorporated completely through learnable attention biases. TableFormer is (1) strictly invariant to row and column orders, and, (2) could understand tables better due to its tabular inductive biases. Our evaluations showed that TableFormer outperforms strong baselines in all settings on SQA, WTQ and TabFact table reasoning datasets, and achieves state-of-the-art performance on SQA, especially when facing answer-invariant row and column order perturbations (6% improvement over the best baseline), because previous SOTA models' performance drops by 4% - 6% when facing such perturbations while TableFormer is not affected.
Pre-Trained Language Transformers are Universal Image Classifiers
Jan 25, 2022Facial images disclose many hidden personal traits such as age, gender, race, health, emotion, and psychology. Understanding these traits will help to classify the people in different attributes. In this paper, we have presented a novel method for classifying images using a pretrained transformer model. We apply the pretrained transformer for the binary classification of facial images in criminal and non-criminal classes. The pretrained transformer of GPT-2 is trained to generate text and then fine-tuned to classify facial images. During the finetuning process with images, most of the layers of GT-2 are frozen during backpropagation and the model is frozen pretrained transformer (FPT). The FPT acts as a universal image classifier, and this paper shows the application of FPT on facial images. We also use our FPT on encrypted images for classification. Our FPT shows high accuracy on both raw facial images and encrypted images. We hypothesize the meta-learning capacity FPT gained because of its large size and trained on a large size with theory and experiments. The GPT-2 trained to generate a single word token at a time, through the autoregressive process, forced to heavy-tail distribution. Then the FPT uses the heavy-tail property as its meta-learning capacity for classifying images. Our work shows one way to avoid bias during the machine classification of images.The FPT encodes worldly knowledge because of the pretraining of one text, which it uses during the classification. The statistical error of classification is reduced because of the added context gained from the text.Our paper shows the ethical dimension of using encrypted data for classification.Criminal images are sensitive to share across the boundary but encrypted largely evades ethical concern.FPT showing good classification accuracy on encrypted images shows promise for further research on privacy-preserving machine learning.
Misinformation Detection on YouTube Using Video Captions
Jul 02, 2021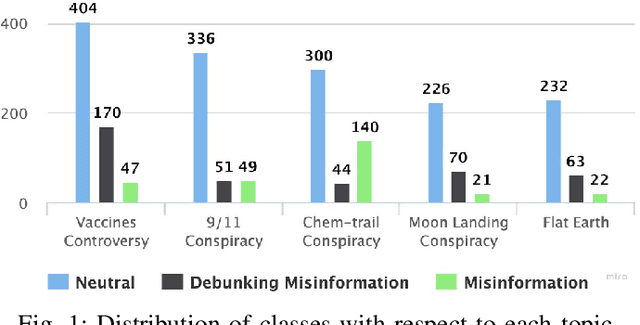
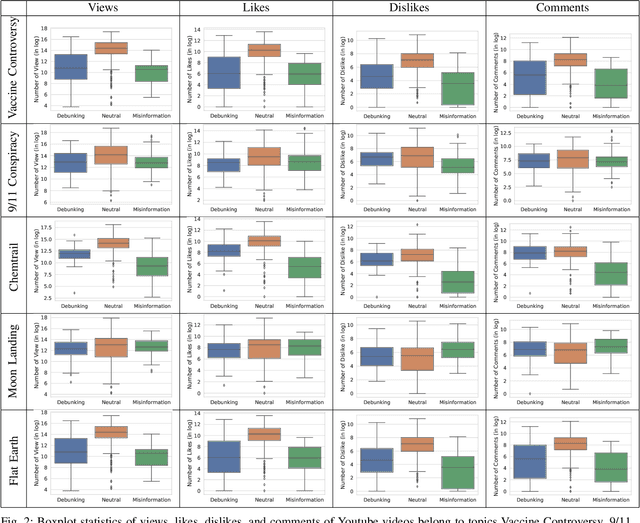
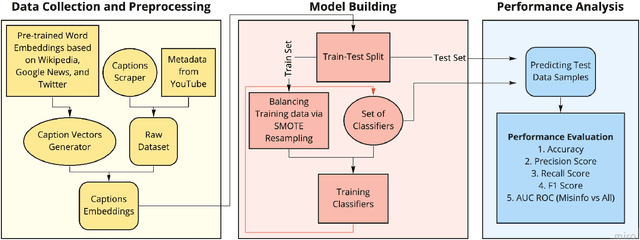
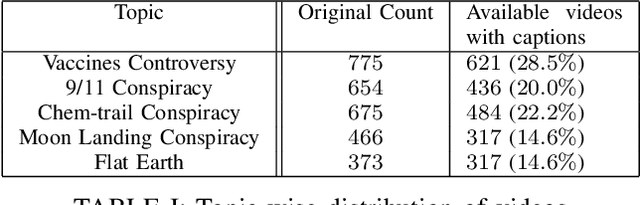
Millions of people use platforms such as YouTube, Facebook, Twitter, and other mass media. Due to the accessibility of these platforms, they are often used to establish a narrative, conduct propaganda, and disseminate misinformation. This work proposes an approach that uses state-of-the-art NLP techniques to extract features from video captions (subtitles). To evaluate our approach, we utilize a publicly accessible and labeled dataset for classifying videos as misinformation or not. The motivation behind exploring video captions stems from our analysis of videos metadata. Attributes such as the number of views, likes, dislikes, and comments are ineffective as videos are hard to differentiate using this information. Using caption dataset, the proposed models can classify videos among three classes (Misinformation, Debunking Misinformation, and Neutral) with 0.85 to 0.90 F1-score. To emphasize the relevance of the misinformation class, we re-formulate our classification problem as a two-class classification - Misinformation vs. others (Debunking Misinformation and Neutral). In our experiments, the proposed models can classify videos with 0.92 to 0.95 F1-score and 0.78 to 0.90 AUC ROC.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
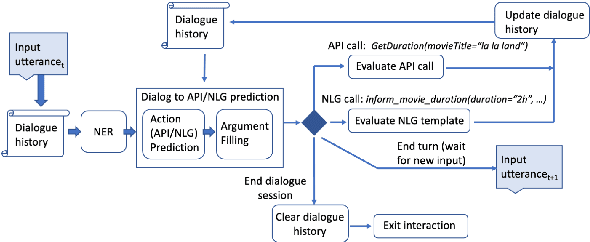

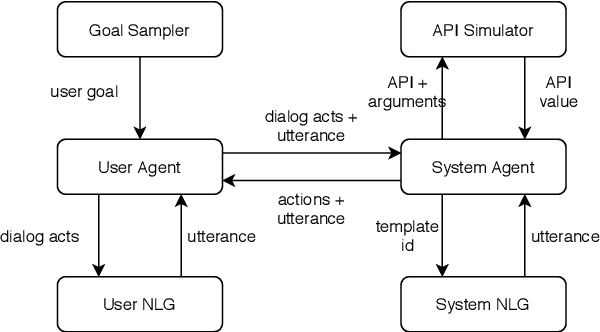
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
Continual Learning for Neural Semantic Parsing
Oct 15, 2020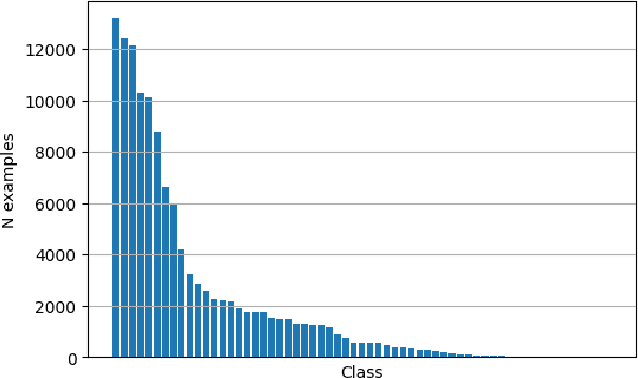
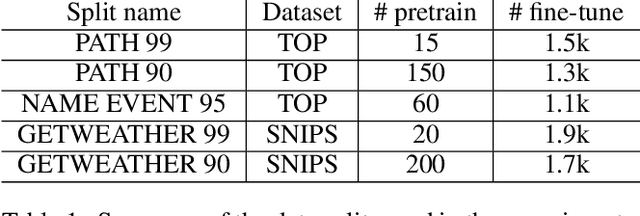
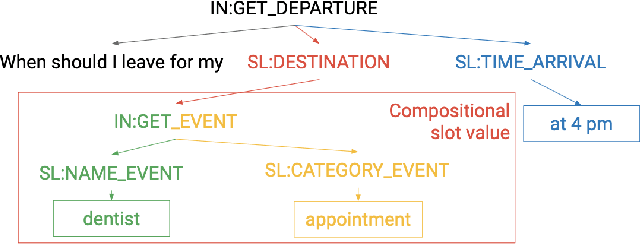
A semantic parsing model is crucial to natural language processing applications such as goal-oriented dialogue systems. Such models can have hundreds of classes with a highly non-uniform distribution. In this work, we show how to efficiently (in terms of computational budget) improve model performance given a new portion of labeled data for a specific low-resource class or a set of classes. We demonstrate that a simple approach with a specific fine-tuning procedure for the old model can reduce the computational costs by ~90% compared to the training of a new model. The resulting performance is on-par with a model trained from scratch on a full dataset. We showcase the efficacy of our approach on two popular semantic parsing datasets, Facebook TOP, and SNIPS.
Towards Universal Dialogue Act Tagging for Task-Oriented Dialogues
Jul 05, 2019
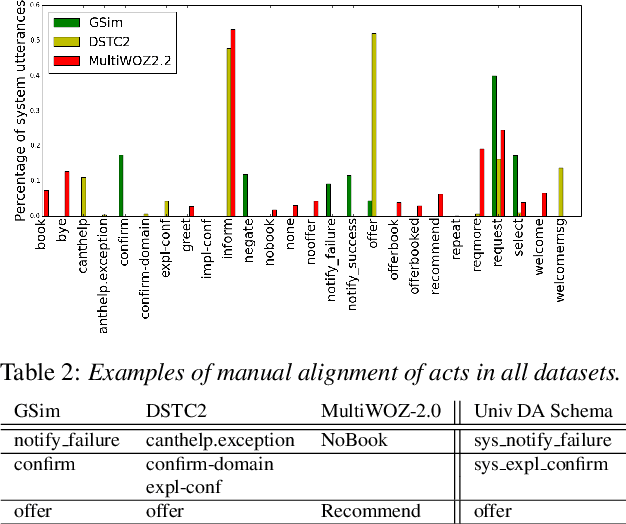
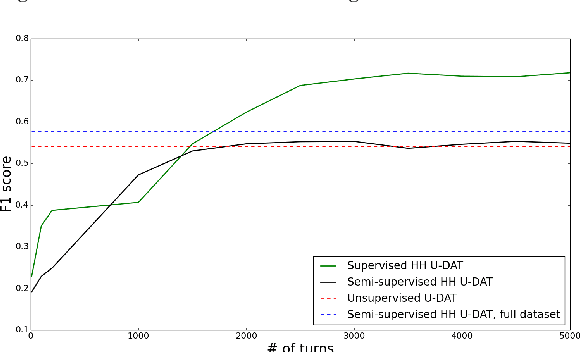
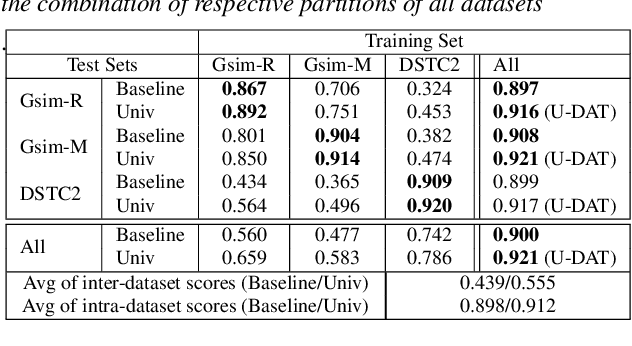
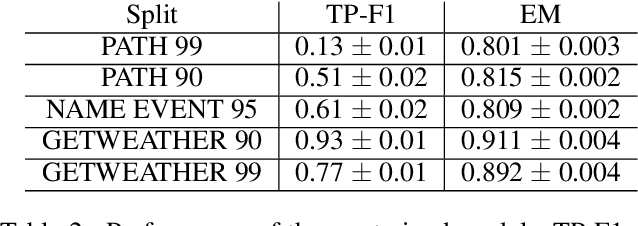
Machine learning approaches for building task-oriented dialogue systems require large conversational datasets with labels to train on. We are interested in building task-oriented dialogue systems from human-human conversations, which may be available in ample amounts in existing customer care center logs or can be collected from crowd workers. Annotating these datasets can be prohibitively expensive. Recently multiple annotated task-oriented human-machine dialogue datasets have been released, however their annotation schema varies across different collections, even for well-defined categories such as dialogue acts (DAs). We propose a Universal DA schema for task-oriented dialogues and align existing annotated datasets with our schema. Our aim is to train a Universal DA tagger (U-DAT) for task-oriented dialogues and use it for tagging human-human conversations. We investigate multiple datasets, propose manual and automated approaches for aligning the different schema, and present results on a target corpus of human-human dialogues. In unsupervised learning experiments we achieve an F1 score of 54.1% on system turns in human-human dialogues. In a semi-supervised setup, the F1 score increases to 57.7% which would otherwise require at least 1.7K manually annotated turns. For new domains, we show further improvements when unlabeled or labeled target domain data is available.
MultiWOZ 2.1: Multi-Domain Dialogue State Corrections and State Tracking Baselines
Jul 02, 2019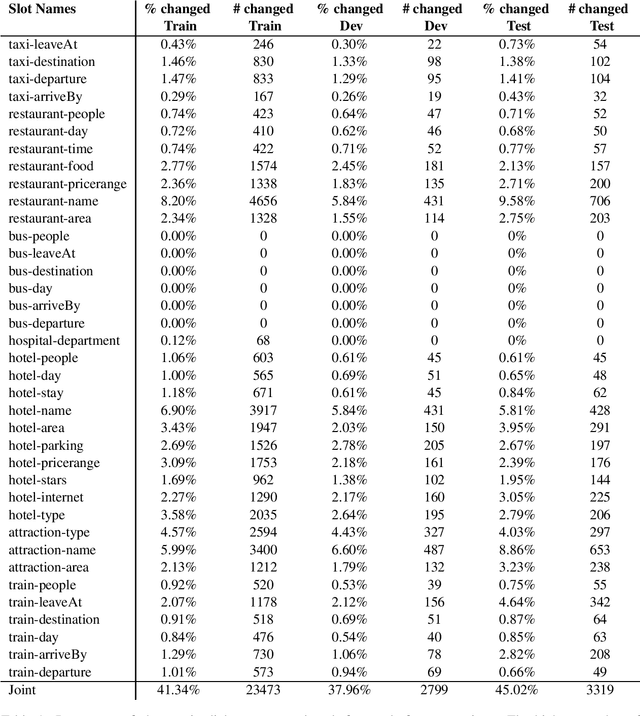

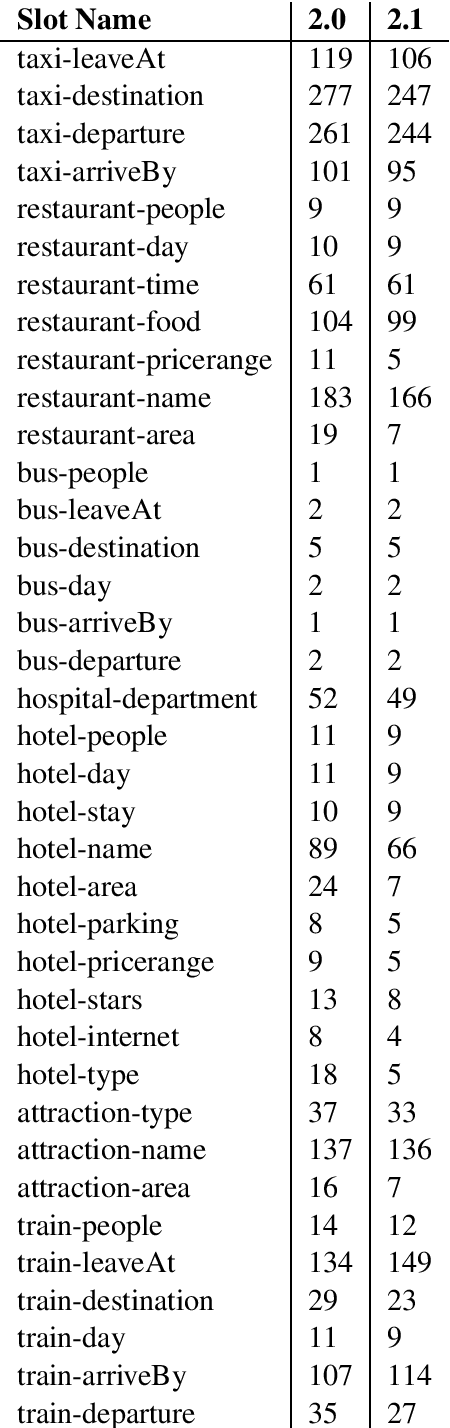
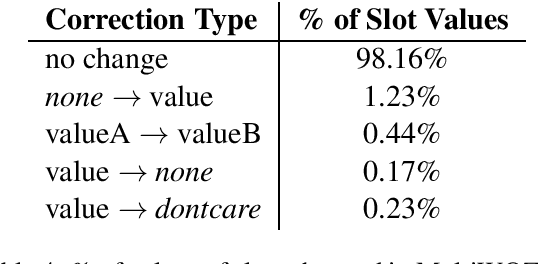
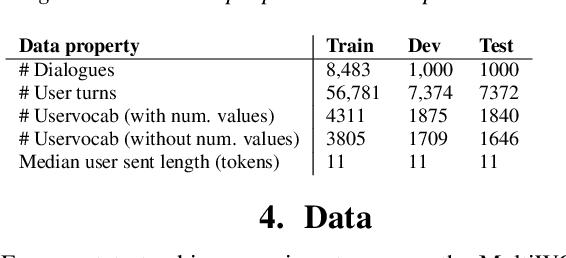
MultiWOZ is a recently-released multidomain dialogue dataset spanning 7 distinct domains and containing over 10000 dialogues, one of the largest resources of its kind to-date. Though an immensely useful resource, while building different classes of dialogue state tracking models using MultiWOZ, we detected substantial errors in the state annotations and dialogue utterances which negatively impacted the performance of our models. In order to alleviate this problem, we use crowdsourced workers to fix the state annotations and utterances in the original version of the data. Our correction process results in changes to over 32% of state annotations across 40% of the dialogue turns. In addition, we fix 146 dialogue utterances throughout the dataset focusing in particular on addressing slot value errors represented within the conversations. We then benchmark a number of state-of-the-art dialogue state tracking models on this new MultiWOZ 2.1 dataset and show joint state tracking performance on the corrected state annotations. We are publicly releasing MultiWOZ 2.1 to the community, hoping that this dataset resource will allow for more effective dialogue state tracking models to be built in the future.
HyST: A Hybrid Approach for Flexible and Accurate Dialogue State Tracking
Jul 01, 2019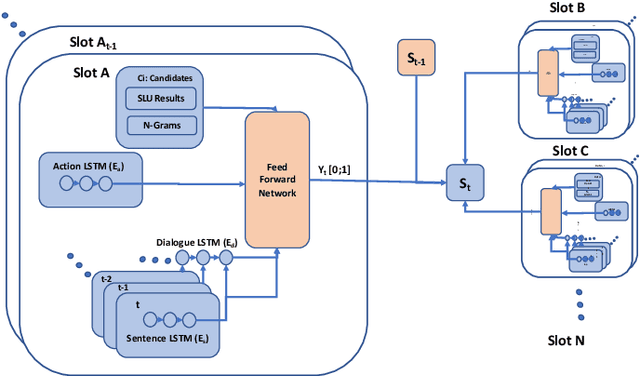
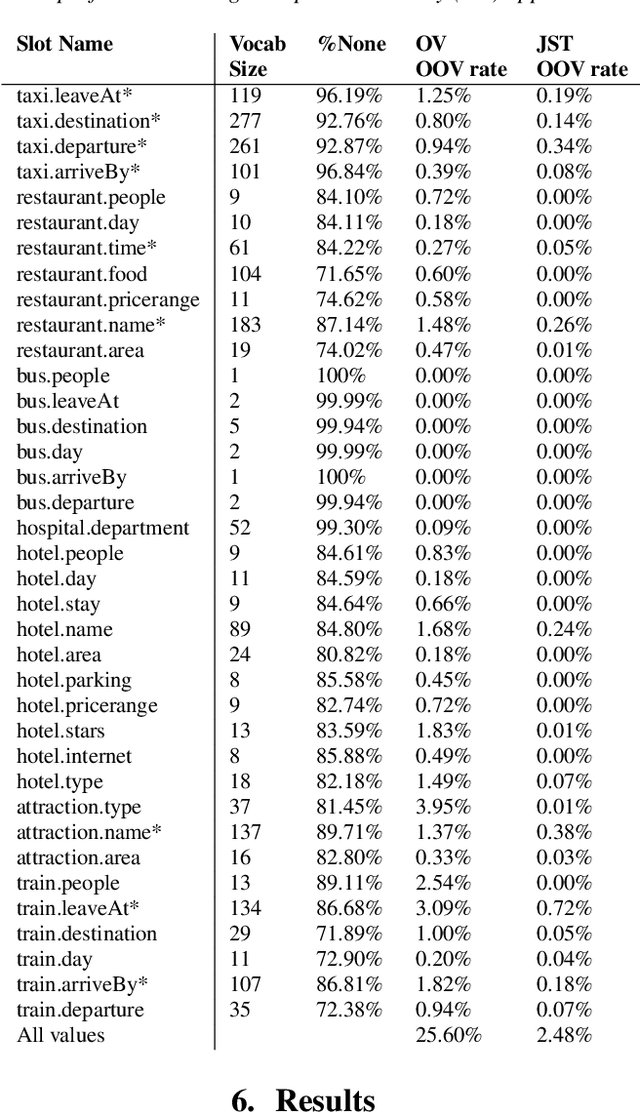
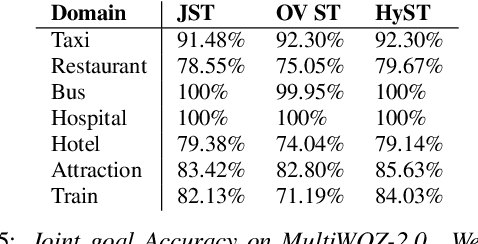
Recent works on end-to-end trainable neural network based approaches have demonstrated state-of-the-art results on dialogue state tracking. The best performing approaches estimate a probability distribution over all possible slot values. However, these approaches do not scale for large value sets commonly present in real-life applications and are not ideal for tracking slot values that were not observed in the training set. To tackle these issues, candidate-generation-based approaches have been proposed. These approaches estimate a set of values that are possible at each turn based on the conversation history and/or language understanding outputs, and hence enable state tracking over unseen values and large value sets however, they fall short in terms of performance in comparison to the first group. In this work, we analyze the performance of these two alternative dialogue state tracking methods, and present a hybrid approach (HyST) which learns the appropriate method for each slot type. To demonstrate the effectiveness of HyST on a rich-set of slot types, we experiment with the recently released MultiWOZ-2.0 multi-domain, task-oriented dialogue-dataset. Our experiments show that HyST scales to multi-domain applications. Our best performing model results in a relative improvement of 24% and 10% over the previous SOTA and our best baseline respectively.
Towards Coherent and Engaging Spoken Dialog Response Generation Using Automatic Conversation Evaluators
May 02, 2019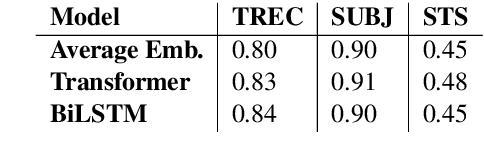
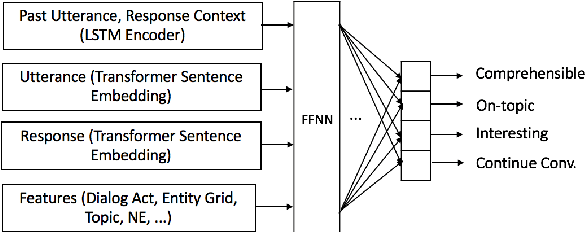
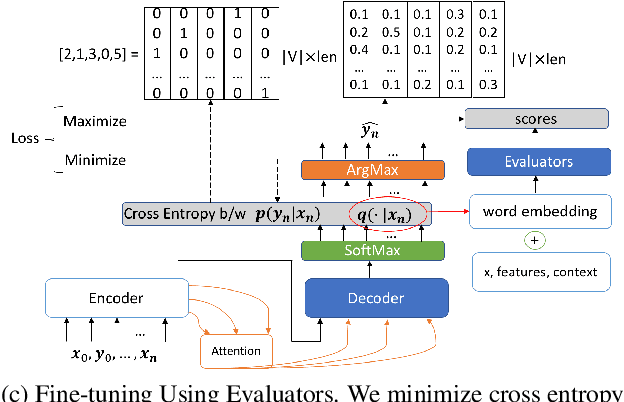

Encoder-decoder based neural architectures serve as the basis of state-of-the-art approaches in end-to-end open domain dialog systems. Since most of such systems are trained with a maximum likelihood(MLE) objective they suffer from issues such as lack of generalizability and the generic response problem, i.e., a system response that can be an answer to a large number of user utterances, e.g., "Maybe, I don't know." Having explicit feedback on the relevance and interestingness of a system response at each turn can be a useful signal for mitigating such issues and improving system quality by selecting responses from different approaches. Towards this goal, we present a system that evaluates chatbot responses at each dialog turn for coherence and engagement. Our system provides explicit turn-level dialog quality feedback, which we show to be highly correlated with human evaluation. To show that incorporating this feedback in the neural response generation models improves dialog quality, we present two different and complementary mechanisms to incorporate explicit feedback into a neural response generation model: reranking and direct modification of the loss function during training. Our studies show that a response generation model that incorporates these combined feedback mechanisms produce more engaging and coherent responses in an open-domain spoken dialog setting, significantly improving the response quality using both automatic and human evaluation.