 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing In-Context Learning: Understanding Prompts via Corruption
Apr 02, 2024



The ability of large language models (LLMs) to "learn in context" based on the provided prompt has led to an explosive growth in their use, culminating in the proliferation of AI assistants such as ChatGPT, Claude, and Bard. These AI assistants are known to be robust to minor prompt modifications, mostly due to alignment techniques that use human feedback. In contrast, the underlying pre-trained LLMs they use as a backbone are known to be brittle in this respect. Building high-quality backbone models remains a core challenge, and a common approach to assessing their quality is to conduct few-shot evaluation. Such evaluation is notorious for being highly sensitive to minor prompt modifications, as well as the choice of specific in-context examples. Prior work has examined how modifying different elements of the prompt can affect model performance. However, these earlier studies tended to concentrate on a limited number of specific prompt attributes and often produced contradictory results. Additionally, previous research either focused on models with fewer than 15 billion parameters or exclusively examined black-box models like GPT-3 or PaLM, making replication challenging. In the present study, we decompose the entire prompt into four components: task description, demonstration inputs, labels, and inline instructions provided for each demonstration. We investigate the effects of structural and semantic corruptions of these elements on model performance. We study models ranging from 1.5B to 70B in size, using ten datasets covering classification and generation tasks. We find that repeating text within the prompt boosts model performance, and bigger models ($\geq$30B) are more sensitive to the semantics of the prompt. Finally, we observe that adding task and inline instructions to the demonstrations enhances model performance even when the instructions are semantically corrupted.
Emergent Abilities in Reduced-Scale Generative Language Models
Apr 02, 2024



Large language models can solve new tasks without task-specific fine-tuning. This ability, also known as in-context learning (ICL), is considered an emergent ability and is primarily seen in large language models with billions of parameters. This study investigates if such emergent properties are strictly tied to model size or can be demonstrated by smaller models trained on reduced-scale data. To explore this, we simplify pre-training data and pre-train 36 causal language models with parameters varying from 1 million to 165 million parameters. We show that models trained on this simplified pre-training data demonstrate enhanced zero-shot capabilities across various tasks in simplified language, achieving performance comparable to that of pre-trained models six times larger on unrestricted language. This suggests that downscaling the language allows zero-shot learning capabilities to emerge in models with limited size. Additionally, we find that these smaller models pre-trained on simplified data demonstrate a power law relationship between the evaluation loss and the three scaling factors: compute, dataset size, and model size.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
Let's Reinforce Step by Step
Nov 10, 2023

While recent advances have boosted LM proficiency in linguistic benchmarks, LMs consistently struggle to reason correctly on complex tasks like mathematics. We turn to Reinforcement Learning from Human Feedback (RLHF) as a method with which to shape model reasoning processes. In particular, we explore two reward schemes, outcome-supervised reward models (ORMs) and process-supervised reward models (PRMs), to optimize for logical reasoning. Our results show that the fine-grained reward provided by PRM-based methods enhances accuracy on simple mathematical reasoning (GSM8K) while, unexpectedly, reducing performance in complex tasks (MATH). Furthermore, we show the critical role reward aggregation functions play in model performance. Providing promising avenues for future research, our study underscores the need for further exploration into fine-grained reward modeling for more reliable language models.
Stack More Layers Differently: High-Rank Training Through Low-Rank Updates
Jul 13, 2023



Despite the dominance and effectiveness of scaling, resulting in large networks with hundreds of billions of parameters, the necessity to train overparametrized models remains poorly understood, and alternative approaches do not necessarily make it cheaper to train high-performance models. In this paper, we explore low-rank training techniques as an alternative approach to training large neural networks. We introduce a novel method called ReLoRA, which utilizes low-rank updates to train high-rank networks. We apply ReLoRA to pre-training transformer language models with up to 350M parameters and demonstrate comparable performance to regular neural network training. Furthermore, we observe that the efficiency of ReLoRA increases with model size, making it a promising approach for training multi-billion-parameter networks efficiently. Our findings shed light on the potential of low-rank training techniques and their implications for scaling laws.
Honey, I Shrunk the Language: Language Model Behavior at Reduced Scale
May 30, 2023



In recent years, language models have drastically grown in size, and the abilities of these models have been shown to improve with scale. The majority of recent scaling laws studies focused on high-compute high-parameter count settings, leaving the question of when these abilities begin to emerge largely unanswered. In this paper, we investigate whether the effects of pre-training can be observed when the problem size is reduced, modeling a smaller, reduced-vocabulary language. We show the benefits of pre-training with masked language modeling (MLM) objective in models as small as 1.25M parameters, and establish a strong correlation between pre-training perplexity and downstream performance (GLUE benchmark). We examine downscaling effects, extending scaling laws to models as small as ~1M parameters. At this scale, we observe a break of the power law for compute-optimal models and show that the MLM loss does not scale smoothly with compute-cost (FLOPs) below $2.2 \times 10^{15}$ FLOPs. We also find that adding layers does not always benefit downstream performance.
Scalable and Accurate Self-supervised Multimodal Representation Learning without Aligned Video and Text Data
Apr 04, 2023



Scaling up weakly-supervised datasets has shown to be highly effective in the image-text domain and has contributed to most of the recent state-of-the-art computer vision and multimodal neural networks. However, existing large-scale video-text datasets and mining techniques suffer from several limitations, such as the scarcity of aligned data, the lack of diversity in the data, and the difficulty of collecting aligned data. Currently popular video-text data mining approach via automatic speech recognition (ASR) used in HowTo100M provides low-quality captions that often do not refer to the video content. Other mining approaches do not provide proper language descriptions (video tags) and are biased toward short clips (alt text). In this work, we show how recent advances in image captioning allow us to pre-train high-quality video models without any parallel video-text data. We pre-train several video captioning models that are based on an OPT language model and a TimeSformer visual backbone. We fine-tune these networks on several video captioning datasets. First, we demonstrate that image captioning pseudolabels work better for pre-training than the existing HowTo100M ASR captions. Second, we show that pre-training on both images and videos produces a significantly better network (+4 CIDER on MSR-VTT) than pre-training on a single modality. Our methods are complementary to the existing pre-training or data mining approaches and can be used in a variety of settings. Given the efficacy of the pseudolabeling method, we are planning to publicly release the generated captions.
Larger Probes Tell a Different Story: Extending Psycholinguistic Datasets Via In-Context Learning
Mar 29, 2023



Language model probing is often used to test specific capabilities of these models. However, conclusions from such studies may be limited when the probing benchmarks are small and lack statistical power. In this work, we introduce new, larger datasets for negation (NEG-1500-SIMP) and role reversal (ROLE-1500) inspired by psycholinguistic studies. We dramatically extend existing NEG-136 and ROLE-88 benchmarks using GPT3, increasing their size from 18 and 44 sentence pairs to 750 each. We also create another version of extended negation dataset (NEG-1500-SIMP-TEMP), created using template-based generation. It consists of 770 sentence pairs. We evaluate 22 models on the extended datasets, seeing model performance dip 20-57% compared to the original smaller benchmarks. We observe high levels of negation sensitivity in models like BERT and ALBERT demonstrating that previous findings might have been skewed due to smaller test sets. Finally, we observe that while GPT3 has generated all the examples in ROLE-1500 is only able to solve 24.6% of them during probing.
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
Mar 28, 2023



This paper presents a systematic overview and comparison of parameter-efficient fine-tuning methods covering over 40 papers published between February 2019 and February 2023. These methods aim to resolve the infeasibility and impracticality of fine-tuning large language models by only training a small set of parameters. We provide a taxonomy that covers a broad range of methods and present a detailed method comparison with a specific focus on real-life efficiency and fine-tuning multibillion-scale language models.
Learning to Ask Like a Physician
Jun 06, 2022
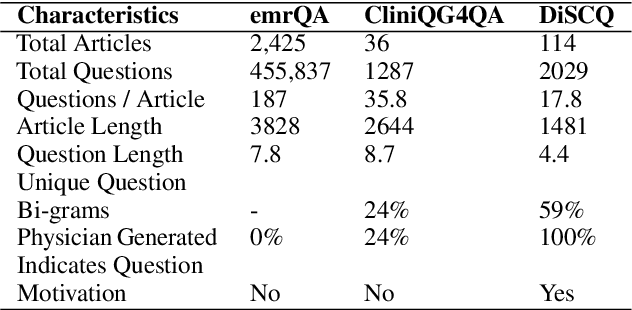

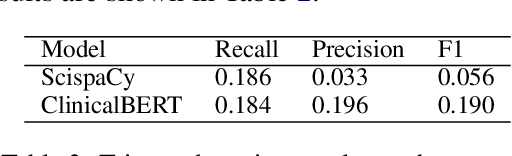
Existing question answering (QA) datasets derived from electronic health records (EHR) are artificially generated and consequently fail to capture realistic physician information needs. We present Discharge Summary Clinical Questions (DiSCQ), a newly curated question dataset composed of 2,000+ questions paired with the snippets of text (triggers) that prompted each question. The questions are generated by medical experts from 100+ MIMIC-III discharge summaries. We analyze this dataset to characterize the types of information sought by medical experts. We also train baseline models for trigger detection and question generation (QG), paired with unsupervised answer retrieval over EHRs. Our baseline model is able to generate high quality questions in over 62% of cases when prompted with human selected triggers. We release this dataset (and all code to reproduce baseline model results) to facilitate further research into realistic clinical QA and QG: https://github.com/elehman16/discq.