 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactored Agents: Decoupling In-Context Learning and Memorization for Robust Tool Use
Apr 02, 2025In this paper, we propose a novel factored agent architecture designed to overcome the limitations of traditional single-agent systems in agentic AI. Our approach decomposes the agent into two specialized components: (1) a large language model (LLM) that serves as a high level planner and in-context learner, which may use dynamically available information in user prompts, (2) a smaller language model which acts as a memorizer of tool format and output. This decoupling addresses prevalent issues in monolithic designs, including malformed, missing, and hallucinated API fields, as well as suboptimal planning in dynamic environments. Empirical evaluations demonstrate that our factored architecture significantly improves planning accuracy and error resilience, while elucidating the inherent trade-off between in-context learning and static memorization. These findings suggest that a factored approach is a promising pathway for developing more robust and adaptable agentic AI systems.
DAMP: Doubly Aligned Multilingual Parser for Task-Oriented Dialogue
Dec 15, 2022Modern virtual assistants use internal semantic parsing engines to convert user utterances to actionable commands. However, prior work has demonstrated that semantic parsing is a difficult multilingual transfer task with low transfer efficiency compared to other tasks. In global markets such as India and Latin America, this is a critical issue as switching between languages is prevalent for bilingual users. In this work we dramatically improve the zero-shot performance of a multilingual and codeswitched semantic parsing system using two stages of multilingual alignment. First, we show that constrastive alignment pretraining improves both English performance and transfer efficiency. We then introduce a constrained optimization approach for hyperparameter-free adversarial alignment during finetuning. Our Doubly Aligned Multilingual Parser (DAMP) improves mBERT transfer performance by 3x, 6x, and 81x on the Spanglish, Hinglish and Multilingual Task Oriented Parsing benchmarks respectively and outperforms XLM-R and mT5-Large using 3.2x fewer parameters.
Reducing Model Jitter: Stable Re-training of Semantic Parsers in Production Environments
Apr 10, 2022
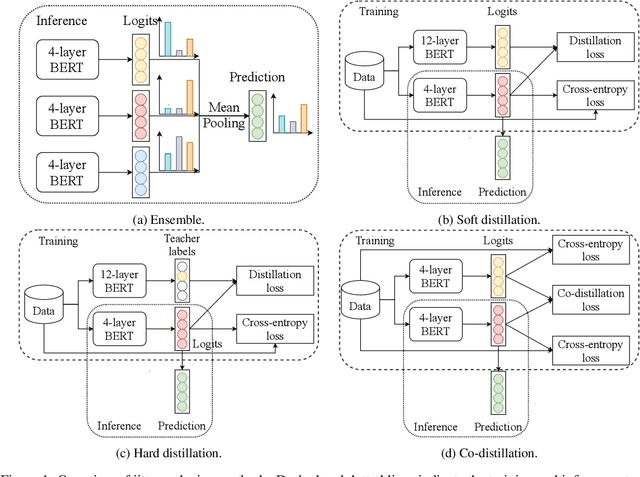
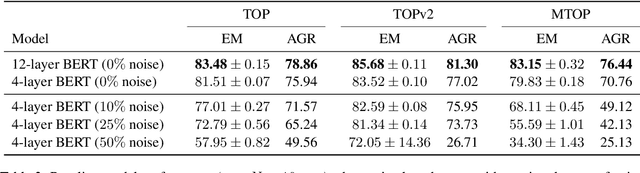
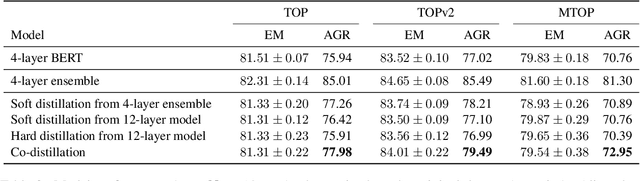
Retraining modern deep learning systems can lead to variations in model performance even when trained using the same data and hyper-parameters by simply using different random seeds. We call this phenomenon model jitter. This issue is often exacerbated in production settings, where models are retrained on noisy data. In this work we tackle the problem of stable retraining with a focus on conversational semantic parsers. We first quantify the model jitter problem by introducing the model agreement metric and showing the variation with dataset noise and model sizes. We then demonstrate the effectiveness of various jitter reduction techniques such as ensembling and distillation. Lastly, we discuss practical trade-offs between such techniques and show that co-distillation provides a sweet spot in terms of jitter reduction for semantic parsing systems with only a modest increase in resource usage.
ENTRUST: Argument Reframing with Language Models and Entailment
Apr 11, 2021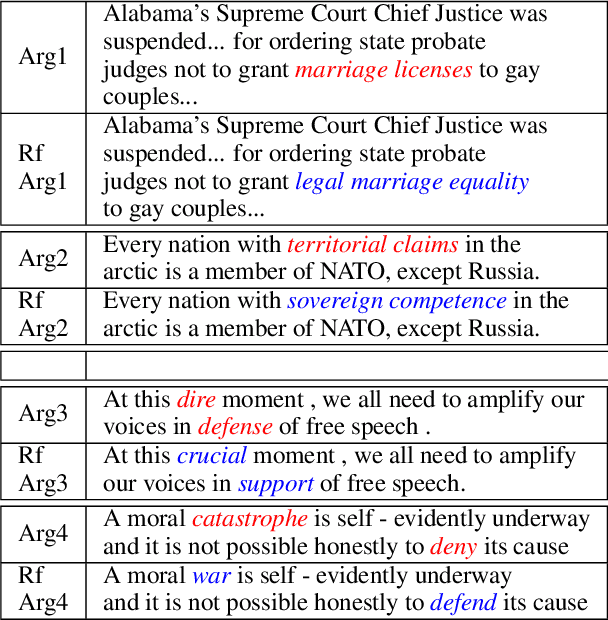
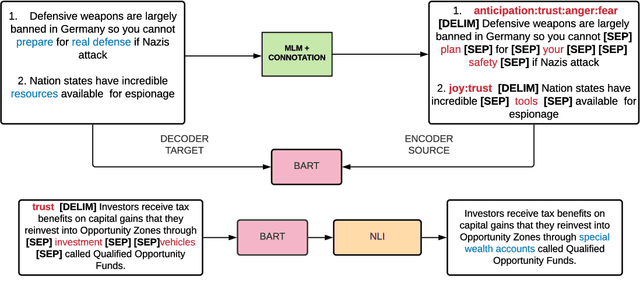


Framing involves the positive or negative presentation of an argument or issue depending on the audience and goal of the speaker (Entman 1983). Differences in lexical framing, the focus of our work, can have large effects on peoples' opinions and beliefs. To make progress towards reframing arguments for positive effects, we create a dataset and method for this task. We use a lexical resource for "connotations" to create a parallel corpus and propose a method for argument reframing that combines controllable text generation (positive connotation) with a post-decoding entailment component (same denotation). Our results show that our method is effective compared to strong baselines along the dimensions of fluency, meaning, and trustworthiness/reduction of fear.
AMPERSAND: Argument Mining for PERSuAsive oNline Discussions
Apr 30, 2020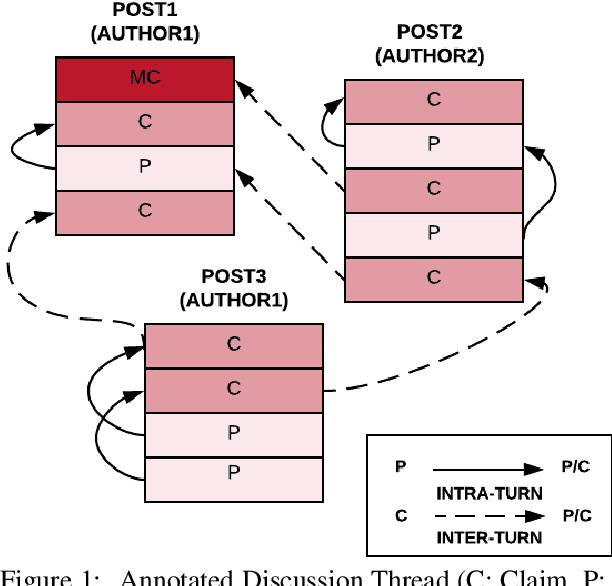

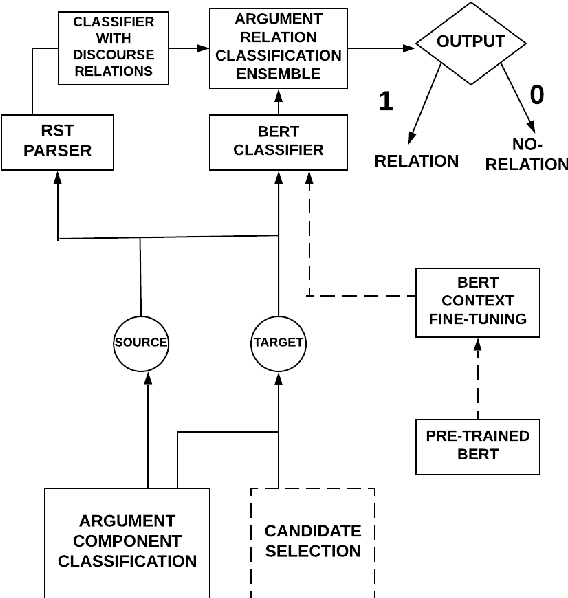
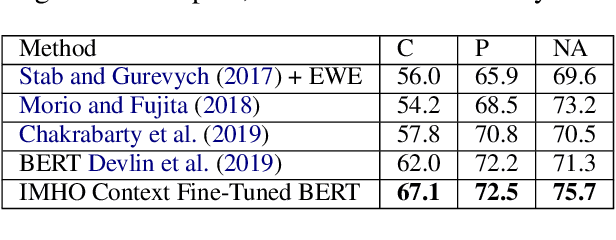
Argumentation is a type of discourse where speakers try to persuade their audience about the reasonableness of a claim by presenting supportive arguments. Most work in argument mining has focused on modeling arguments in monologues. We propose a computational model for argument mining in online persuasive discussion forums that brings together the micro-level (argument as product) and macro-level (argument as process) models of argumentation. Fundamentally, this approach relies on identifying relations between components of arguments in a discussion thread. Our approach for relation prediction uses contextual information in terms of fine-tuning a pre-trained language model and leveraging discourse relations based on Rhetorical Structure Theory. We additionally propose a candidate selection method to automatically predict what parts of one's argument will be targeted by other participants in the discussion. Our models obtain significant improvements compared to recent state-of-the-art approaches using pointer networks and a pre-trained language model.
DeSePtion: Dual Sequence Prediction and Adversarial Examples for Improved Fact-Checking
Apr 27, 2020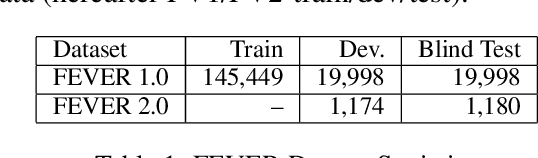
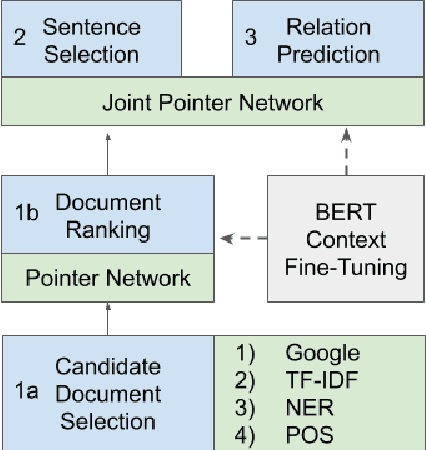
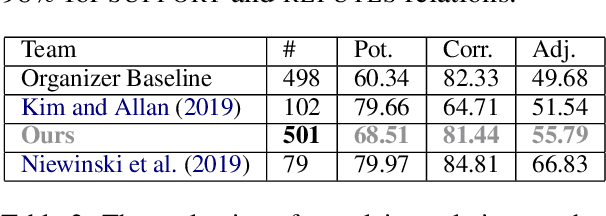
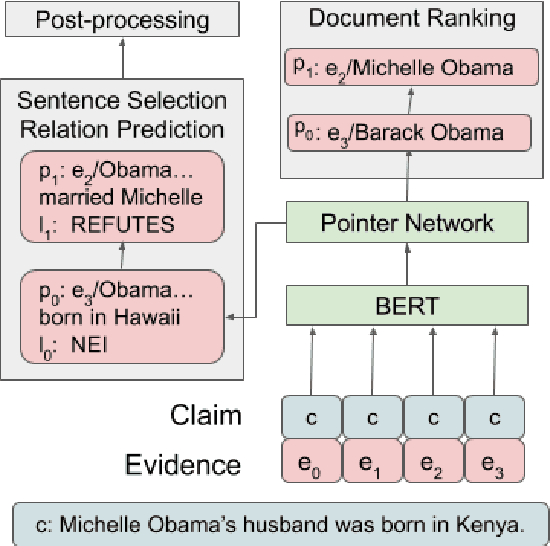
The increased focus on misinformation has spurred development of data and systems for detecting the veracity of a claim as well as retrieving authoritative evidence. The Fact Extraction and VERification (FEVER) dataset provides such a resource for evaluating end-to-end fact-checking, requiring retrieval of evidence from Wikipedia to validate a veracity prediction. We show that current systems for FEVER are vulnerable to three categories of realistic challenges for fact-checking -- multiple propositions, temporal reasoning, and ambiguity and lexical variation -- and introduce a resource with these types of claims. Then we present a system designed to be resilient to these "attacks" using multiple pointer networks for document selection and jointly modeling a sequence of evidence sentences and veracity relation predictions. We find that in handling these attacks we obtain state-of-the-art results on FEVER, largely due to improved evidence retrieval.
IMHO Fine-Tuning Improves Claim Detection
May 16, 2019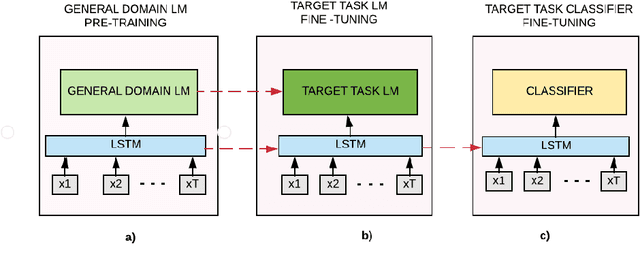
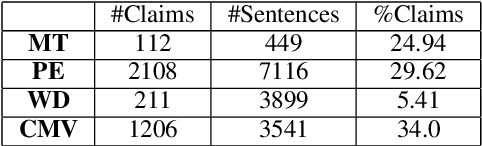
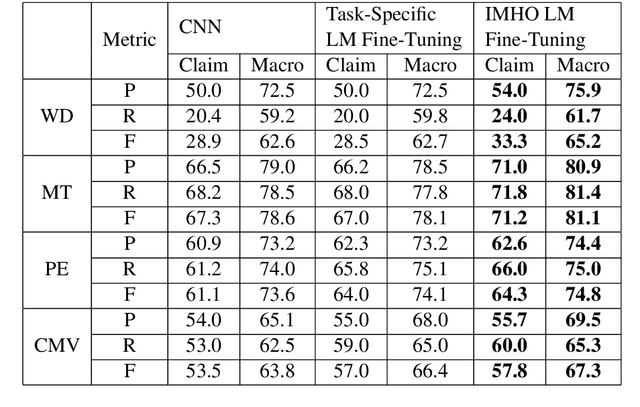
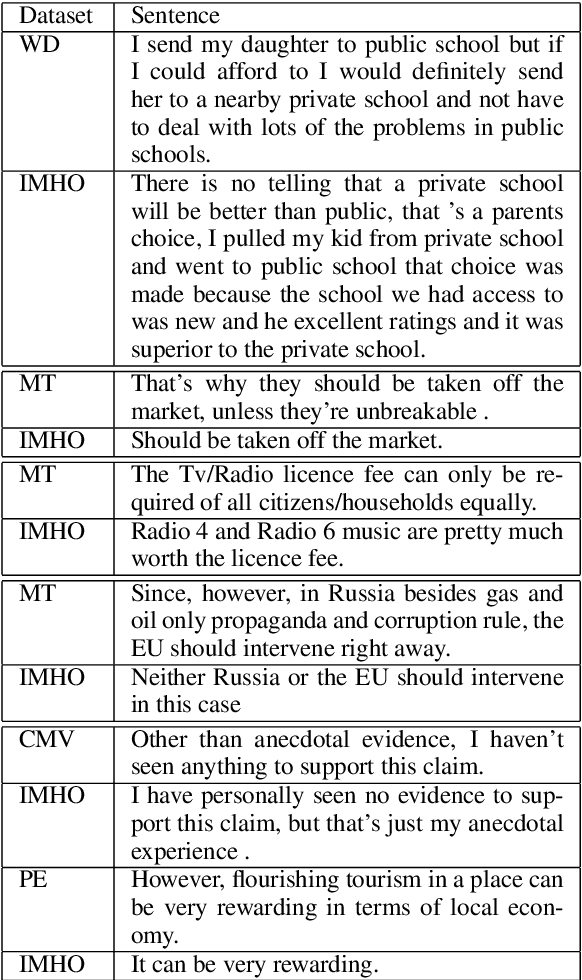
Claims are the central component of an argument. Detecting claims across different domains or data sets can often be challenging due to their varying conceptualization. We propose to alleviate this problem by fine tuning a language model using a Reddit corpus of 5.5 million opinionated claims. These claims are self-labeled by their authors using the internet acronyms IMO/IMHO (in my (humble) opinion). Empirical results show that using this approach improves the state of art performance across four benchmark argumentation data sets by an average of 4 absolute F1 points in claim detection. As these data sets include diverse domains such as social media and student essays this improvement demonstrates the robustness of fine-tuning on this novel corpus.
Leveraging Sparse and Dense Feature Combinations for Sentiment Classification
Aug 13, 2017
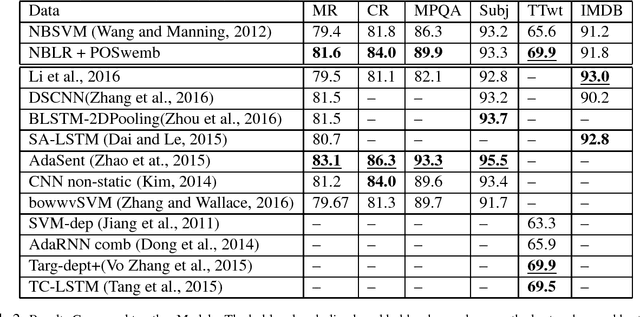
Neural networks are one of the most popular approaches for many natural language processing tasks such as sentiment analysis. They often outperform traditional machine learning models and achieve the state-of-art results on most tasks. However, many existing deep learning models are complex, difficult to train and provide a limited improvement over simpler methods. We propose a simple, robust and powerful model for sentiment classification. This model outperforms many deep learning models and achieves comparable results to other deep learning models with complex architectures on sentiment analysis datasets. We publish the code online.