 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Aware Modelling: A Survey
Feb 16, 2023

Personalized prediction of responses for individual entities caused by external drivers is vital across many disciplines. Recent machine learning (ML) advances have led to new state-of-the-art response prediction models. Models built at a population level often lead to sub-optimal performance in many personalized prediction settings due to heterogeneity in data across entities (tasks). In personalized prediction, the goal is to incorporate inherent characteristics of different entities to improve prediction performance. In this survey, we focus on the recent developments in the ML community for such entity-aware modeling approaches. ML algorithms often modulate the network using these entity characteristics when they are readily available. However, these entity characteristics are not readily available in many real-world scenarios, and different ML methods have been proposed to infer these characteristics from the data. In this survey, we have organized the current literature on entity-aware modeling based on the availability of these characteristics as well as the amount of training data. We highlight how recent innovations in other disciplines, such as uncertainty quantification, fairness, and knowledge-guided machine learning, can improve entity-aware modeling.
Mapping smallholder cashew plantations to inform sustainable tree crop expansion in Benin
Jan 01, 2023



Cashews are grown by over 3 million smallholders in more than 40 countries worldwide as a principal source of income. As the third largest cashew producer in Africa, Benin has nearly 200,000 smallholder cashew growers contributing 15% of the country's national export earnings. However, a lack of information on where and how cashew trees grow across the country hinders decision-making that could support increased cashew production and poverty alleviation. By leveraging 2.4-m Planet Basemaps and 0.5-m aerial imagery, newly developed deep learning algorithms, and large-scale ground truth datasets, we successfully produced the first national map of cashew in Benin and characterized the expansion of cashew plantations between 2015 and 2021. In particular, we developed a SpatioTemporal Classification with Attention (STCA) model to map the distribution of cashew plantations, which can fully capture texture information from discriminative time steps during a growing season. We further developed a Clustering Augmented Self-supervised Temporal Classification (CASTC) model to distinguish high-density versus low-density cashew plantations by automatic feature extraction and optimized clustering. Results show that the STCA model has an overall accuracy of 80% and the CASTC model achieved an overall accuracy of 77.9%. We found that the cashew area in Benin has doubled from 2015 to 2021 with 60% of new plantation development coming from cropland or fallow land, while encroachment of cashew plantations into protected areas has increased by 70%. Only half of cashew plantations were high-density in 2021, suggesting high potential for intensification. Our study illustrates the power of combining high-resolution remote sensing imagery and state-of-the-art deep learning algorithms to better understand tree crops in the heterogeneous smallholder landscape.
Mini-Batch Learning Strategies for modeling long term temporal dependencies: A study in environmental applications
Oct 15, 2022
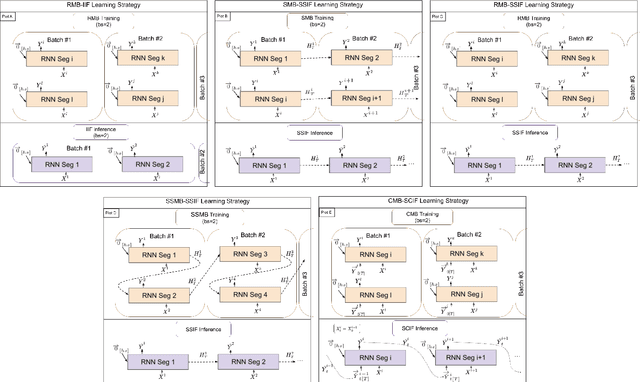
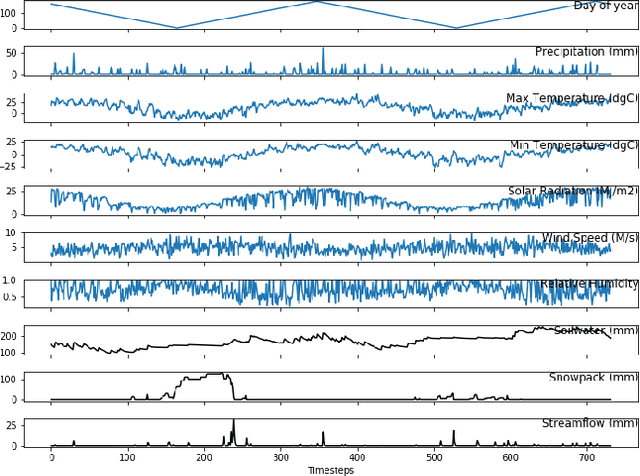
In many environmental applications, recurrent neural networks (RNNs) are often used to model physical variables with long temporal dependencies. However, due to mini-batch training, temporal relationships between training segments within the batch (intra-batch) as well as between batches (inter-batch) are not considered, which can lead to limited performance. Stateful RNNs aim to address this issue by passing hidden states between batches. Since Stateful RNNs ignore intra-batch temporal dependency, there exists a trade-off between training stability and capturing temporal dependency. In this paper, we provide a quantitative comparison of different Stateful RNN modeling strategies, and propose two strategies to enforce both intra- and inter-batch temporal dependency. First, we extend Stateful RNNs by defining a batch as a temporally ordered set of training segments, which enables intra-batch sharing of temporal information. While this approach significantly improves the performance, it leads to much larger training times due to highly sequential training. To address this issue, we further propose a new strategy which augments a training segment with an initial value of the target variable from the timestep right before the starting of the training segment. In other words, we provide an initial value of the target variable as additional input so that the network can focus on learning changes relative to that initial value. By using this strategy, samples can be passed in any order (mini-batch training) which significantly reduces the training time while maintaining the performance. In demonstrating our approach in hydrological modeling, we observe that the most significant gains in predictive accuracy occur when these methods are applied to state variables whose values change more slowly, such as soil water and snowpack, rather than continuously moving flux variables such as streamflow.
Spatiotemporal Classification with limited labels using Constrained Clustering for large datasets
Oct 14, 2022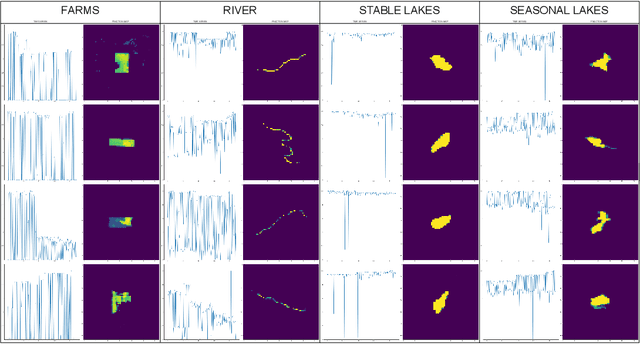
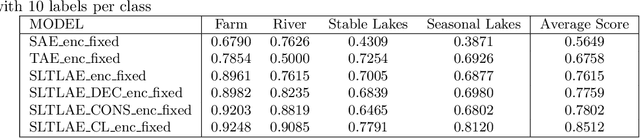
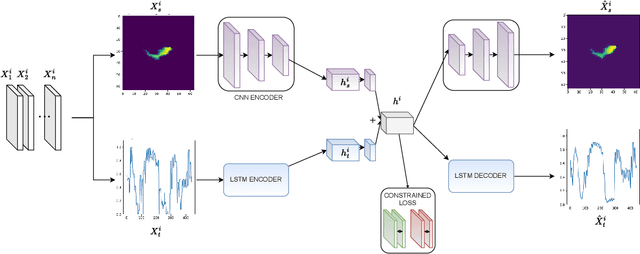
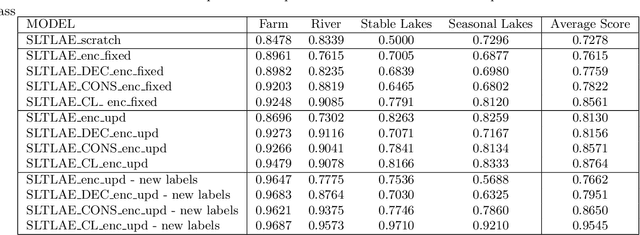
Creating separable representations via representation learning and clustering is critical in analyzing large unstructured datasets with only a few labels. Separable representations can lead to supervised models with better classification capabilities and additionally aid in generating new labeled samples. Most unsupervised and semisupervised methods to analyze large datasets do not leverage the existing small amounts of labels to get better representations. In this paper, we propose a spatiotemporal clustering paradigm that uses spatial and temporal features combined with a constrained loss to produce separable representations. We show the working of this method on the newly published dataset ReaLSAT, a dataset of surface water dynamics for over 680,000 lakes across the world, making it an essential dataset in terms of ecology and sustainability. Using this large unlabelled dataset, we first show how a spatiotemporal representation is better compared to just spatial or temporal representation. We then show how we can learn even better representation using a constrained loss with few labels. We conclude by showing how our method, using few labels, can pick out new labeled samples from the unlabeled data, which can be used to augment supervised methods leading to better classification.
Probabilistic Inverse Modeling: An Application in Hydrology
Oct 12, 2022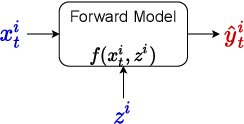
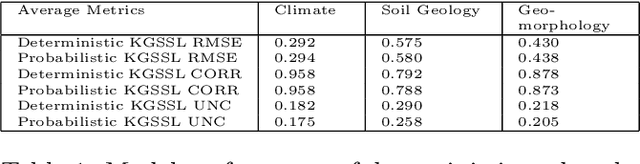
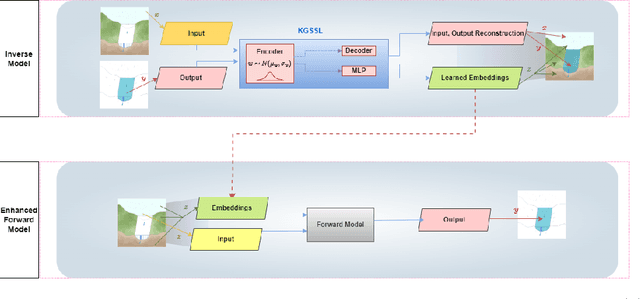
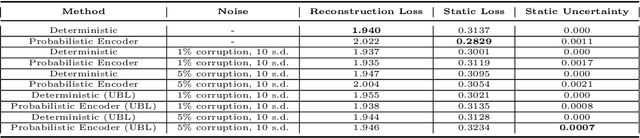
The astounding success of these methods has made it imperative to obtain more explainable and trustworthy estimates from these models. In hydrology, basin characteristics can be noisy or missing, impacting streamflow prediction. For solving inverse problems in such applications, ensuring explainability is pivotal for tackling issues relating to data bias and large search space. We propose a probabilistic inverse model framework that can reconstruct robust hydrology basin characteristics from dynamic input weather driver and streamflow response data. We address two aspects of building more explainable inverse models, uncertainty estimation and robustness. This can help improve the trust of water managers, handling of noisy data and reduce costs. We propose uncertainty based learning method that offers 6\% improvement in $R^2$ for streamflow prediction (forward modeling) from inverse model inferred basin characteristic estimates, 17\% reduction in uncertainty (40\% in presence of noise) and 4\% higher coverage rate for basin characteristics.
Knowledge-guided Self-supervised Learning for estimating River-Basin Characteristics
Sep 14, 2021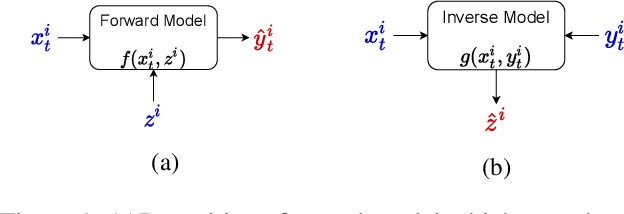

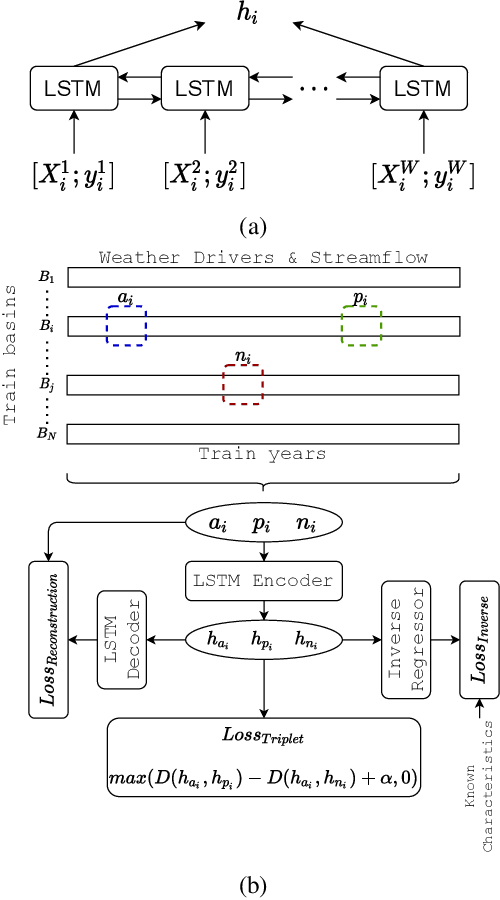
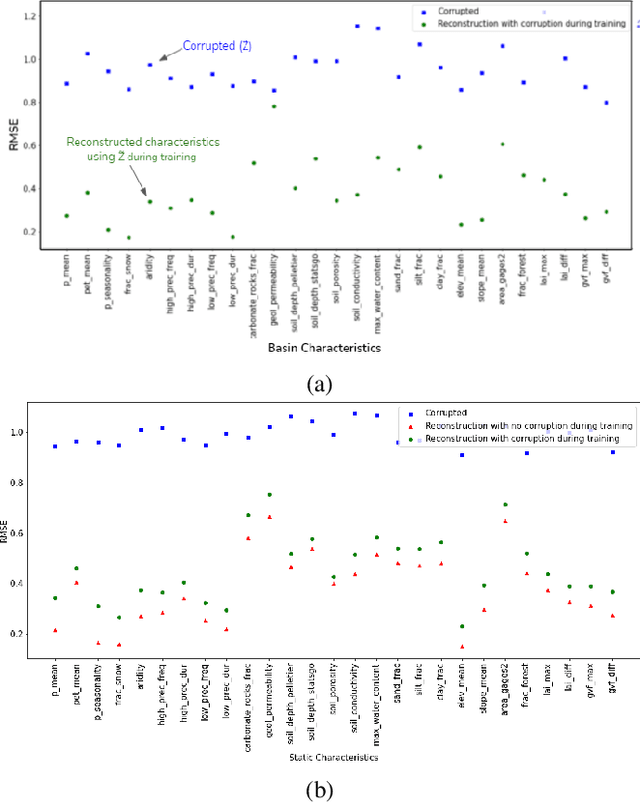
Machine Learning is being extensively used in hydrology, especially streamflow prediction of basins/watersheds. Basin characteristics are essential for modeling the rainfall-runoff response of these watersheds and therefore data-driven methods must take into account this ancillary characteristics data. However there are several limitations, namely uncertainty in the measured characteristics, partially missing characteristics for some of the basins or unknown characteristics that may not be present in the known measured set. In this paper we present an inverse model that uses a knowledge-guided self-supervised learning algorithm to infer basin characteristics using the meteorological drivers and streamflow response data. We evaluate our model on the the CAMELS dataset and the results validate its ability to reduce measurement uncertainty, impute missing characteristics, and identify unknown characteristics.
Weakly Supervised Classification Using Group-Level Labels
Aug 16, 2021
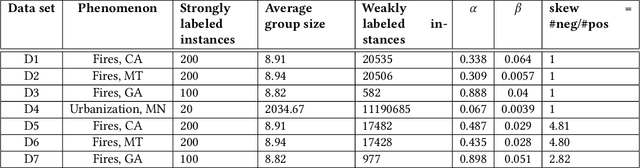
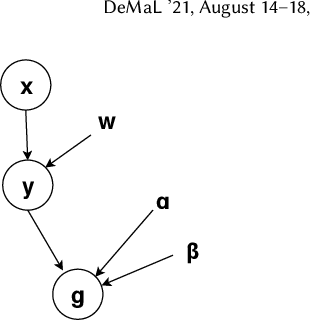
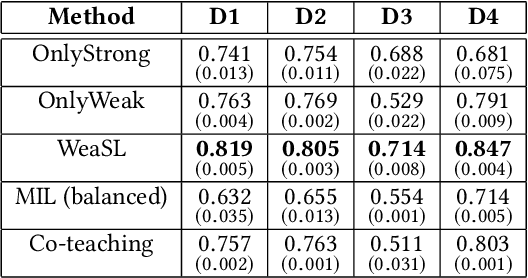
In many applications, finding adequate labeled data to train predictive models is a major challenge. In this work, we propose methods to use group-level binary labels as weak supervision to train instance-level binary classification models. Aggregate labels are common in several domains where annotating on a group-level might be cheaper or might be the only way to provide annotated data without infringing on privacy. We model group-level labels as Class Conditional Noisy (CCN) labels for individual instances and use the noisy labels to regularize predictions of the model trained on the strongly-labeled instances. Our experiments on real-world application of land cover mapping shows the utility of the proposed method in leveraging group-level labels, both in the presence and absence of class imbalance.
Clustering augmented Self-Supervised Learning: Anapplication to Land Cover Mapping
Aug 16, 2021
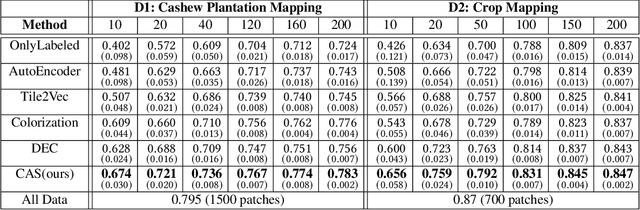
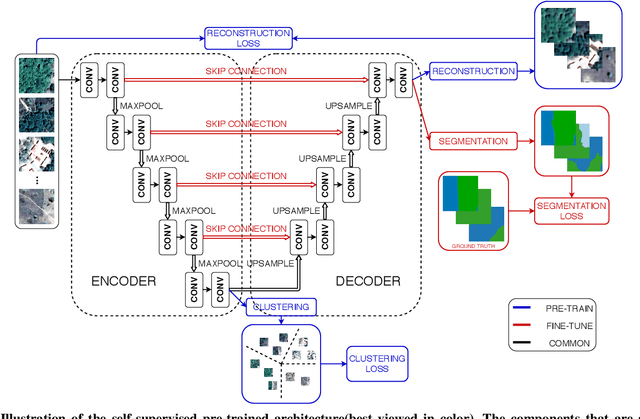

Collecting large annotated datasets in Remote Sensing is often expensive and thus can become a major obstacle for training advanced machine learning models. Common techniques of addressing this issue, based on the underlying idea of pre-training the Deep Neural Networks (DNN) on freely available large datasets, cannot be used for Remote Sensing due to the unavailability of such large-scale labeled datasets and the heterogeneity of data sources caused by the varying spatial and spectral resolution of different sensors. Self-supervised learning is an alternative approach that learns feature representation from unlabeled images without using any human annotations. In this paper, we introduce a new method for land cover mapping by using a clustering based pretext task for self-supervised learning. We demonstrate the effectiveness of the method on two societally relevant applications from the aspect of segmentation performance, discriminative feature representation learning and the underlying cluster structure. We also show the effectiveness of the active sampling using the clusters obtained from our method in improving the mapping accuracy given a limited budget of annotating.
CalCROP21: A Georeferenced multi-spectral dataset of Satellite Imagery and Crop Labels
Jul 26, 2021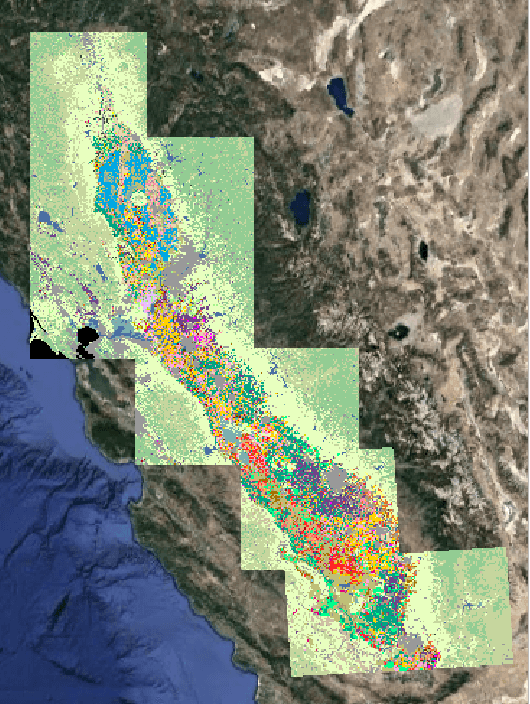
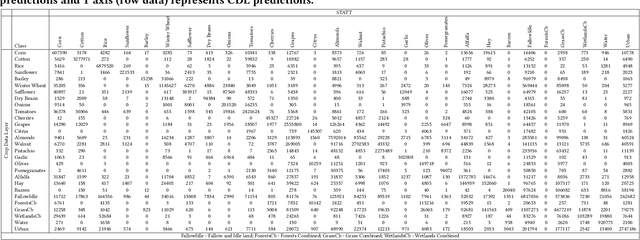
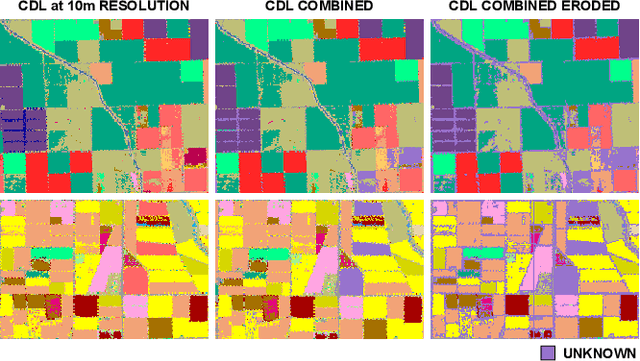
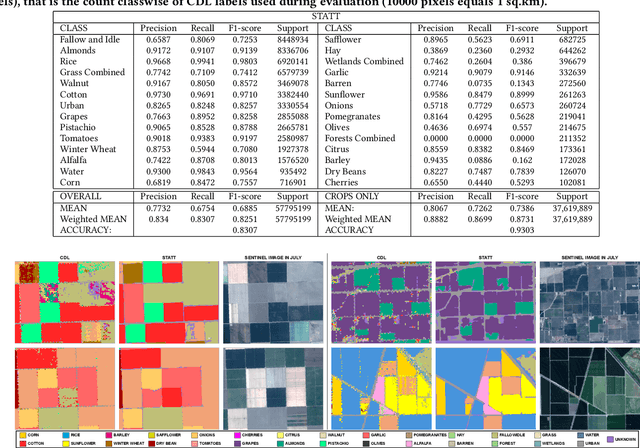
Mapping and monitoring crops is a key step towards sustainable intensification of agriculture and addressing global food security. A dataset like ImageNet that revolutionized computer vision applications can accelerate development of novel crop mapping techniques. Currently, the United States Department of Agriculture (USDA) annually releases the Cropland Data Layer (CDL) which contains crop labels at 30m resolution for the entire United States of America. While CDL is state of the art and is widely used for a number of agricultural applications, it has a number of limitations (e.g., pixelated errors, labels carried over from previous errors and absence of input imagery along with class labels). In this work, we create a new semantic segmentation benchmark dataset, which we call CalCROP21, for the diverse crops in the Central Valley region of California at 10m spatial resolution using a Google Earth Engine based robust image processing pipeline and a novel attention based spatio-temporal semantic segmentation algorithm STATT. STATT uses re-sampled (interpolated) CDL labels for training, but is able to generate a better prediction than CDL by leveraging spatial and temporal patterns in Sentinel2 multi-spectral image series to effectively capture phenologic differences amongst crops and uses attention to reduce the impact of clouds and other atmospheric disturbances. We also present a comprehensive evaluation to show that STATT has significantly better results when compared to the resampled CDL labels. We have released the dataset and the processing pipeline code for generating the benchmark dataset.
Attention-augmented Spatio-Temporal Segmentation for Land Cover Mapping
May 02, 2021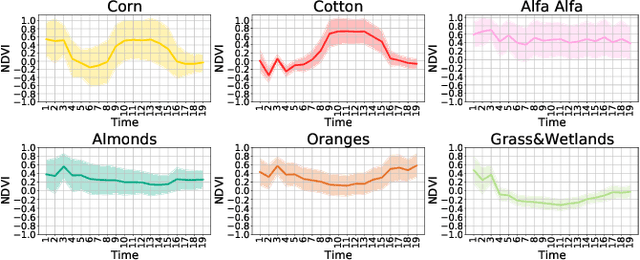
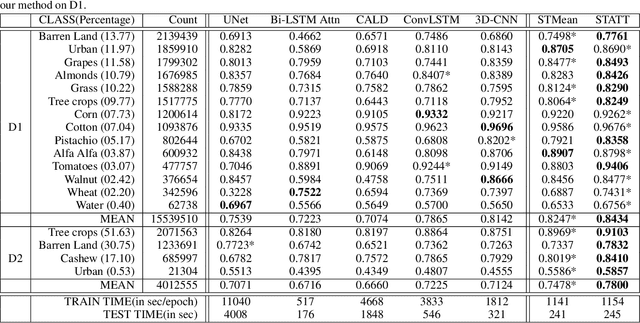
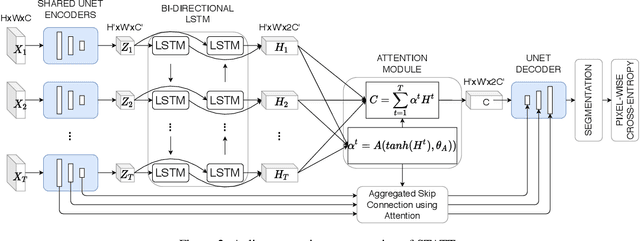
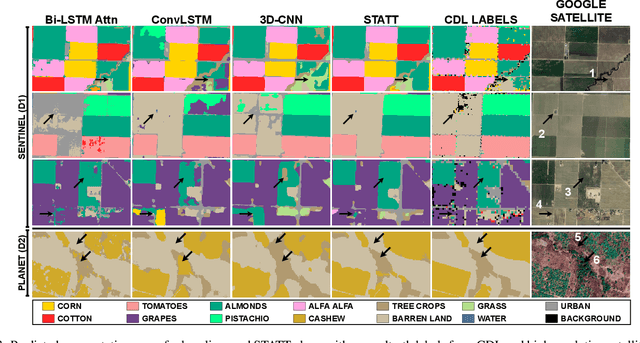
The availability of massive earth observing satellite data provide huge opportunities for land use and land cover mapping. However, such mapping effort is challenging due to the existence of various land cover classes, noisy data, and the lack of proper labels. Also, each land cover class typically has its own unique temporal pattern and can be identified only during certain periods. In this article, we introduce a novel architecture that incorporates the UNet structure with Bidirectional LSTM and Attention mechanism to jointly exploit the spatial and temporal nature of satellite data and to better identify the unique temporal patterns of each land cover. We evaluate this method for mapping crops in multiple regions over the world. We compare our method with other state-of-the-art methods both quantitatively and qualitatively on two real-world datasets which involve multiple land cover classes. We also visualise the attention weights to study its effectiveness in mitigating noise and identifying discriminative time period.