 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteer2Adapt: Dynamically Composing Steering Vectors Elicits Efficient Adaptation of LLMs
Feb 07, 2026Activation steering has emerged as a promising approach for efficiently adapting large language models (LLMs) to downstream behaviors. However, most existing steering methods rely on a single static direction per task or concept, making them inflexible under task variation and inadequate for complex tasks that require multiple coordinated capabilities. To address this limitation, we propose STEER2ADAPT, a lightweight framework that adapts LLMs by composing steering vectors rather than learning new ones from scratch. In many domains (e.g., reasoning or safety), tasks share a small set of underlying concept dimensions. STEER2ADAPT captures these dimensions as a reusable, low-dimensional semantic prior subspace, and adapts to new tasks by dynamically discovering a linear combination of basis vectors from only a handful of examples. Experiments across 9 tasks and 3 models in both reasoning and safety domains demonstrate the effectiveness of STEER2ADAPT, achieving an average improvement of 8.2%. Extensive analyses further show that STEER2ADAPT is a data-efficient, stable, and transparent inference-time adaptation method for LLMs.
SocialVeil: Probing Social Intelligence of Language Agents under Communication Barriers
Feb 04, 2026Large language models (LLMs) are increasingly evaluated in interactive environments to test their social intelligence. However, existing benchmarks often assume idealized communication between agents, limiting our ability to diagnose whether LLMs can maintain and repair interactions in more realistic, imperfect settings. To close this gap, we present \textsc{SocialVeil}, a social learning environment that can simulate social interaction under cognitive-difference-induced communication barriers. Grounded in a systematic literature review of communication challenges in human interaction, \textsc{SocialVeil} introduces three representative types of such disruption, \emph{semantic vagueness}, \emph{sociocultural mismatch}, and \emph{emotional interference}. We also introduce two barrier-aware evaluation metrics, \emph{unresolved confusion} and \emph{mutual understanding}, to evaluate interaction quality under impaired communication. Experiments across 720 scenarios and four frontier LLMs show that barriers consistently impair performance, with mutual understanding reduced by over 45\% on average, and confusion elevated by nearly 50\%. Human evaluations validate the fidelity of these simulated barriers (ICC$\approx$0.78, Pearson r$\approx$0.80). We further demonstrate that adaptation strategies (Repair Instruction and Interactive learning) only have a modest effect far from barrier-free performance. This work takes a step toward bringing social interaction environments closer to real-world communication, opening opportunities for exploring the social intelligence of LLM agents.
Sotopia-RL: Reward Design for Social Intelligence
Aug 05, 2025



Social intelligence has become a critical capability for large language models (LLMs), enabling them to engage effectively in real-world social tasks such as accommodation, persuasion, collaboration, and negotiation. Reinforcement learning (RL) is a natural fit for training socially intelligent agents because it allows models to learn sophisticated strategies directly through social interactions. However, social interactions have two key characteristics that set barriers for RL training: (1) partial observability, where utterances have indirect and delayed effects that complicate credit assignment, and (2) multi-dimensionality, where behaviors such as rapport-building or knowledge-seeking contribute indirectly to goal achievement. These characteristics make Markov decision process (MDP)-based RL with single-dimensional episode-level rewards inefficient and unstable. To address these challenges, we propose Sotopia-RL, a novel framework that refines coarse episode-level feedback into utterance-level, multi-dimensional rewards. Utterance-level credit assignment mitigates partial observability by attributing outcomes to individual utterances, while multi-dimensional rewards capture the full richness of social interactions and reduce reward hacking. Experiments in Sotopia, an open-ended social learning environment, demonstrate that Sotopia-RL achieves state-of-the-art social goal completion scores (7.17 on Sotopia-hard and 8.31 on Sotopia-full), significantly outperforming existing approaches. Ablation studies confirm the necessity of both utterance-level credit assignment and multi-dimensional reward design for RL training. Our implementation is publicly available at: https://github.com/sotopia-lab/sotopia-rl.
TAMP: Token-Adaptive Layerwise Pruning in Multimodal Large Language Models
Apr 15, 2025Multimodal Large Language Models (MLLMs) have shown remarkable versatility in understanding diverse multimodal data and tasks. However, these capabilities come with an increased model scale. While post-training pruning reduces model size in unimodal models, its application to MLLMs often yields limited success. Our analysis discovers that conventional methods fail to account for the unique token attributes across layers and modalities inherent to MLLMs. Inspired by this observation, we propose TAMP, a simple yet effective pruning framework tailored for MLLMs, featuring two key components: (1) Diversity-Aware Sparsity, which adjusts sparsity ratio per layer based on diversities among multimodal output tokens, preserving more parameters in high-diversity layers; and (2) Adaptive Multimodal Input Activation, which identifies representative multimodal input tokens using attention scores to guide unstructured weight pruning. We validate our method on two state-of-the-art MLLMs: LLaVA-NeXT, designed for vision-language tasks, and VideoLLaMA2, capable of processing audio, visual, and language modalities. Empirical experiments across various multimodal evaluation benchmarks demonstrate that each component of our approach substantially outperforms existing pruning techniques.
ResearchTown: Simulator of Human Research Community
Dec 23, 2024Large Language Models (LLMs) have demonstrated remarkable potential in scientific domains, yet a fundamental question remains unanswered: Can we simulate human research communities with LLMs? Addressing this question can deepen our understanding of the processes behind idea brainstorming and inspire the automatic discovery of novel scientific insights. In this work, we propose ResearchTown, a multi-agent framework for research community simulation. Within this framework, the human research community is simplified and modeled as an agent-data graph, where researchers and papers are represented as agent-type and data-type nodes, respectively, and connected based on their collaboration relationships. We also introduce TextGNN, a text-based inference framework that models various research activities (e.g., paper reading, paper writing, and review writing) as special forms of a unified message-passing process on the agent-data graph. To evaluate the quality of the research simulation, we present ResearchBench, a benchmark that uses a node-masking prediction task for scalable and objective assessment based on similarity. Our experiments reveal three key findings: (1) ResearchTown can provide a realistic simulation of collaborative research activities, including paper writing and review writing; (2) ResearchTown can maintain robust simulation with multiple researchers and diverse papers; (3) ResearchTown can generate interdisciplinary research ideas that potentially inspire novel research directions.
LEMMA: Towards LVLM-Enhanced Multimodal Misinformation Detection with External Knowledge Augmentation
Feb 19, 2024



The rise of multimodal misinformation on social platforms poses significant challenges for individuals and societies. Its increased credibility and broader impact compared to textual misinformation make detection complex, requiring robust reasoning across diverse media types and profound knowledge for accurate verification. The emergence of Large Vision Language Model (LVLM) offers a potential solution to this problem. Leveraging their proficiency in processing visual and textual information, LVLM demonstrates promising capabilities in recognizing complex information and exhibiting strong reasoning skills. In this paper, we first investigate the potential of LVLM on multimodal misinformation detection. We find that even though LVLM has a superior performance compared to LLMs, its profound reasoning may present limited power with a lack of evidence. Based on these observations, we propose LEMMA: LVLM-Enhanced Multimodal Misinformation Detection with External Knowledge Augmentation. LEMMA leverages LVLM intuition and reasoning capabilities while augmenting them with external knowledge to enhance the accuracy of misinformation detection. Our method improves the accuracy over the top baseline LVLM by 7% and 13% on Twitter and Fakeddit datasets respectively.
Spatiotemporal Classification with limited labels using Constrained Clustering for large datasets
Oct 14, 2022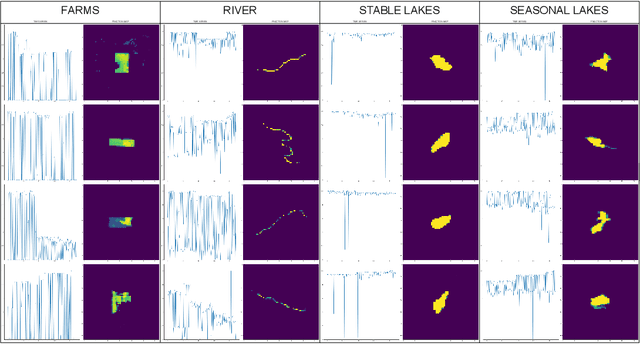
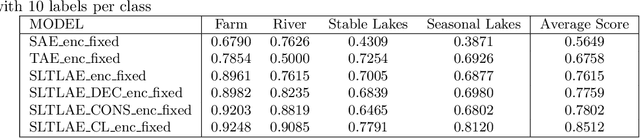
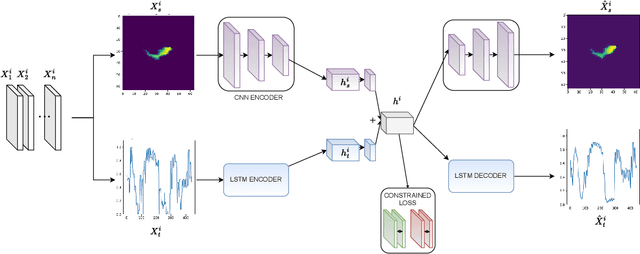
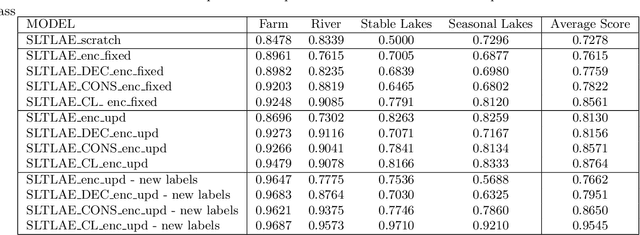
Creating separable representations via representation learning and clustering is critical in analyzing large unstructured datasets with only a few labels. Separable representations can lead to supervised models with better classification capabilities and additionally aid in generating new labeled samples. Most unsupervised and semisupervised methods to analyze large datasets do not leverage the existing small amounts of labels to get better representations. In this paper, we propose a spatiotemporal clustering paradigm that uses spatial and temporal features combined with a constrained loss to produce separable representations. We show the working of this method on the newly published dataset ReaLSAT, a dataset of surface water dynamics for over 680,000 lakes across the world, making it an essential dataset in terms of ecology and sustainability. Using this large unlabelled dataset, we first show how a spatiotemporal representation is better compared to just spatial or temporal representation. We then show how we can learn even better representation using a constrained loss with few labels. We conclude by showing how our method, using few labels, can pick out new labeled samples from the unlabeled data, which can be used to augment supervised methods leading to better classification.