 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLI-3 Vision Language Models: Smaller, Faster, Stronger
Oct 17, 2023



This paper presents PaLI-3, a smaller, faster, and stronger vision language model (VLM) that compares favorably to similar models that are 10x larger. As part of arriving at this strong performance, we compare Vision Transformer (ViT) models pretrained using classification objectives to contrastively (SigLIP) pretrained ones. We find that, while slightly underperforming on standard image classification benchmarks, SigLIP-based PaLI shows superior performance across various multimodal benchmarks, especially on localization and visually-situated text understanding. We scale the SigLIP image encoder up to 2 billion parameters, and achieves a new state-of-the-art on multilingual cross-modal retrieval. We hope that PaLI-3, at only 5B parameters, rekindles research on fundamental pieces of complex VLMs, and could fuel a new generation of scaled-up models.
CausalLM is not optimal for in-context learning
Sep 03, 2023



Recent empirical evidence indicates that transformer based in-context learning performs better when using a prefix language model (prefixLM), in which in-context samples can all attend to each other, compared to causal language models (causalLM), which use auto-regressive attention that prohibits in-context samples to attend to future samples. While this result is intuitive, it is not understood from a theoretical perspective. In this paper we take a theoretical approach and analyze the convergence behavior of prefixLM and causalLM under a certain parameter construction. Our analysis shows that both LM types converge to their stationary points at a linear rate, but that while prefixLM converges to the optimal solution of linear regression, causalLM convergence dynamics follows that of an online gradient descent algorithm, which is not guaranteed to be optimal even as the number of samples grows infinitely. We supplement our theoretical claims with empirical experiments over synthetic and real tasks and using various types of transformers. Our experiments verify that causalLM consistently underperforms prefixLM in all settings.
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Jul 28, 2023We study how vision-language models trained on Internet-scale data can be incorporated directly into end-to-end robotic control to boost generalization and enable emergent semantic reasoning. Our goal is to enable a single end-to-end trained model to both learn to map robot observations to actions and enjoy the benefits of large-scale pretraining on language and vision-language data from the web. To this end, we propose to co-fine-tune state-of-the-art vision-language models on both robotic trajectory data and Internet-scale vision-language tasks, such as visual question answering. In contrast to other approaches, we propose a simple, general recipe to achieve this goal: in order to fit both natural language responses and robotic actions into the same format, we express the actions as text tokens and incorporate them directly into the training set of the model in the same way as natural language tokens. We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).
PaLI-X: On Scaling up a Multilingual Vision and Language Model
May 29, 2023



We present the training recipe and results of scaling up PaLI-X, a multilingual vision and language model, both in terms of size of the components and the breadth of its training task mixture. Our model achieves new levels of performance on a wide-range of varied and complex tasks, including multiple image-based captioning and question-answering tasks, image-based document understanding and few-shot (in-context) learning, as well as object detection, video question answering, and video captioning. PaLI-X advances the state-of-the-art on most vision-and-language benchmarks considered (25+ of them). Finally, we observe emerging capabilities, such as complex counting and multilingual object detection, tasks that are not explicitly in the training mix.
Connecting Vision and Language with Video Localized Narratives
Mar 15, 2023



We propose Video Localized Narratives, a new form of multimodal video annotations connecting vision and language. In the original Localized Narratives, annotators speak and move their mouse simultaneously on an image, thus grounding each word with a mouse trace segment. However, this is challenging on a video. Our new protocol empowers annotators to tell the story of a video with Localized Narratives, capturing even complex events involving multiple actors interacting with each other and with several passive objects. We annotated 20k videos of the OVIS, UVO, and Oops datasets, totalling 1.7M words. Based on this data, we also construct new benchmarks for the video narrative grounding and video question answering tasks, and provide reference results from strong baseline models. Our annotations are available at https://google.github.io/video-localized-narratives/.
Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting
Dec 13, 2022



Text-guided image editing can have a transformative impact in supporting creative applications. A key challenge is to generate edits that are faithful to input text prompts, while consistent with input images. We present Imagen Editor, a cascaded diffusion model built, by fine-tuning Imagen on text-guided image inpainting. Imagen Editor's edits are faithful to the text prompts, which is accomplished by using object detectors to propose inpainting masks during training. In addition, Imagen Editor captures fine details in the input image by conditioning the cascaded pipeline on the original high resolution image. To improve qualitative and quantitative evaluation, we introduce EditBench, a systematic benchmark for text-guided image inpainting. EditBench evaluates inpainting edits on natural and generated images exploring objects, attributes, and scenes. Through extensive human evaluation on EditBench, we find that object-masking during training leads to across-the-board improvements in text-image alignment -- such that Imagen Editor is preferred over DALL-E 2 and Stable Diffusion -- and, as a cohort, these models are better at object-rendering than text-rendering, and handle material/color/size attributes better than count/shape attributes.
Improving Robust Generalization by Direct PAC-Bayesian Bound Minimization
Nov 22, 2022Recent research in robust optimization has shown an overfitting-like phenomenon in which models trained against adversarial attacks exhibit higher robustness on the training set compared to the test set. Although previous work provided theoretical explanations for this phenomenon using a robust PAC-Bayesian bound over the adversarial test error, related algorithmic derivations are at best only loosely connected to this bound, which implies that there is still a gap between their empirical success and our understanding of adversarial robustness theory. To close this gap, in this paper we consider a different form of the robust PAC-Bayesian bound and directly minimize it with respect to the model posterior. The derivation of the optimal solution connects PAC-Bayesian learning to the geometry of the robust loss surface through a Trace of Hessian (TrH) regularizer that measures the surface flatness. In practice, we restrict the TrH regularizer to the top layer only, which results in an analytical solution to the bound whose computational cost does not depend on the network depth. Finally, we evaluate our TrH regularization approach over CIFAR-10/100 and ImageNet using Vision Transformers (ViT) and compare against baseline adversarial robustness algorithms. Experimental results show that TrH regularization leads to improved ViT robustness that either matches or surpasses previous state-of-the-art approaches while at the same time requires less memory and computational cost.
PaLI: A Jointly-Scaled Multilingual Language-Image Model
Sep 16, 2022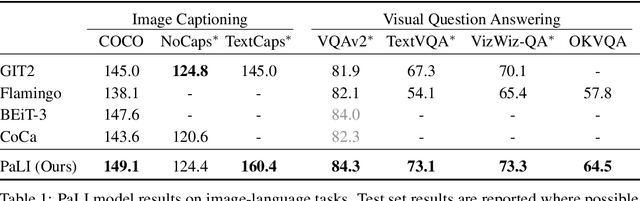

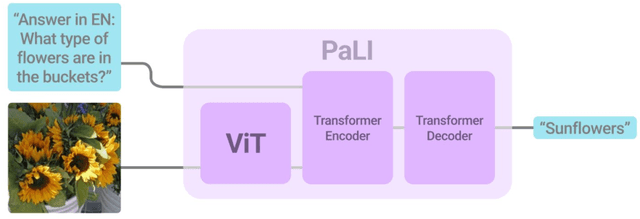

Effective scaling and a flexible task interface enable large language models to excel at many tasks. PaLI (Pathways Language and Image model) extends this approach to the joint modeling of language and vision. PaLI generates text based on visual and textual inputs, and with this interface performs many vision, language, and multimodal tasks, in many languages. To train PaLI, we make use of large pretrained encoder-decoder language models and Vision Transformers (ViTs). This allows us to capitalize on their existing capabilities and leverage the substantial cost of training them. We find that joint scaling of the vision and language components is important. Since existing Transformers for language are much larger than their vision counterparts, we train the largest ViT to date (ViT-e) to quantify the benefits from even larger-capacity vision models. To train PaLI, we create a large multilingual mix of pretraining tasks, based on a new image-text training set containing 10B images and texts in over 100 languages. PaLI achieves state-of-the-art in multiple vision and language tasks (such as captioning, visual question-answering, scene-text understanding), while retaining a simple, modular, and scalable design.
PreSTU: Pre-Training for Scene-Text Understanding
Sep 12, 2022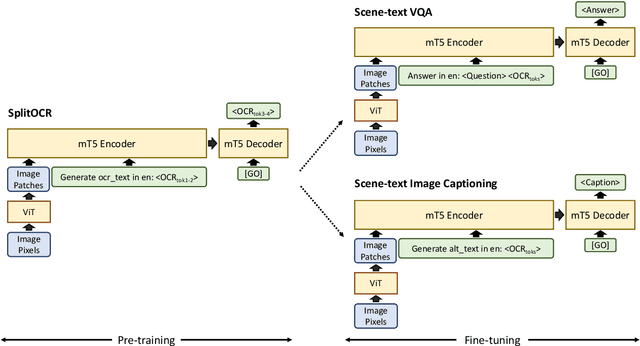
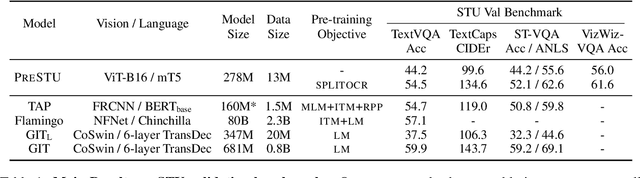
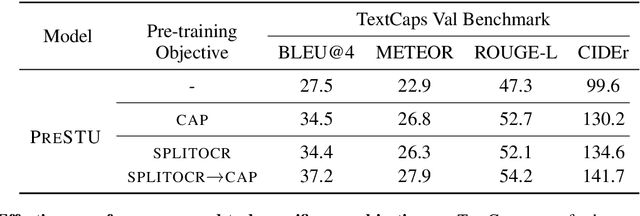
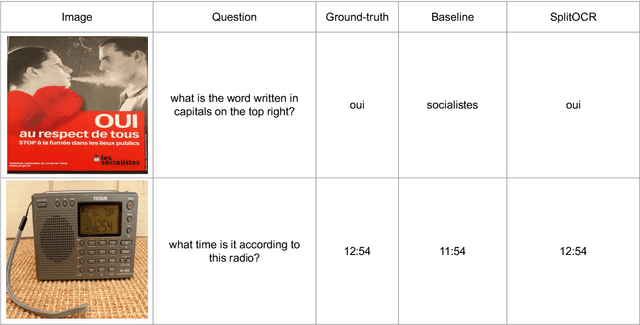
The ability to read and reason about texts in an image is often lacking in vision-and-language (V&L) models. How can we learn V&L models that exhibit strong scene-text understanding (STU)? In this paper, we propose PreSTU, a simple pre-training recipe specifically designed for scene-text understanding. PreSTU combines a simple OCR-aware pre-training objective with a large-scale image-text dataset with off-the-shelf OCR signals. We empirically demonstrate the superiority of this pre-training objective on TextVQA, TextCaps, ST-VQA, and VizWiz-VQA. We also study which factors affect STU performance, where we highlight the importance of image resolution and dataset scale during pre-training.
Towards Multi-Lingual Visual Question Answering
Sep 12, 2022

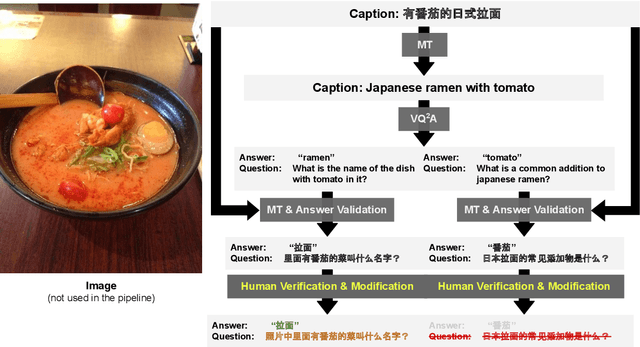
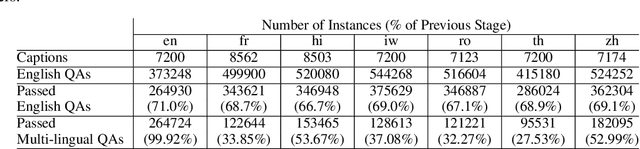
Visual Question Answering (VQA) has been primarily studied through the lens of the English language. Yet, tackling VQA in other languages in the same manner would require considerable amount of resources. In this paper, we propose scalable solutions to multi-lingual visual question answering (mVQA), on both data and modeling fronts. We first propose a translation-based framework to mVQA data generation that requires much less human annotation efforts than the conventional approach of directly collection questions and answers. Then, we apply our framework to the multi-lingual captions in the Crossmodal-3600 dataset and develop an efficient annotation protocol to create MAVERICS-XM3600 (MaXM), a test-only VQA benchmark in 7 diverse languages. Finally, we propose an approach to unified, extensible, open-ended, and end-to-end mVQA modeling and demonstrate strong performance in 13 languages.