 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm
Beyond Good Intentions: Reporting the Research Landscape of NLP for Social Good
May 14, 2023With the recent advances in natural language processing (NLP), a vast number of applications have emerged across various use cases. Among the plethora of NLP applications, many academic researchers are motivated to do work that has a positive social impact, in line with the recent initiatives of NLP for Social Good (NLP4SG). However, it is not always obvious to researchers how their research efforts are tackling today's big social problems. Thus, in this paper, we introduce NLP4SGPAPERS, a scientific dataset with three associated tasks that can help identify NLP4SG papers and characterize the NLP4SG landscape by: (1) identifying the papers that address a social problem, (2) mapping them to the corresponding UN Sustainable Development Goals (SDGs), and (3) identifying the task they are solving and the methods they are using. Using state-of-the-art NLP models, we address each of these tasks and use them on the entire ACL Anthology, resulting in a visualization workspace that gives researchers a comprehensive overview of the field of NLP4SG. Our website is available at https://nlp4sg.vercel.app . We released our data at https://huggingface.co/datasets/feradauto/NLP4SGPapers and code at https://github.com/feradauto/nlp4sg .
A Review of Deep Learning Techniques for Speech Processing
May 02, 2023The field of speech processing has undergone a transformative shift with the advent of deep learning. The use of multiple processing layers has enabled the creation of models capable of extracting intricate features from speech data. This development has paved the way for unparalleled advancements in speech recognition, text-to-speech synthesis, automatic speech recognition, and emotion recognition, propelling the performance of these tasks to unprecedented heights. The power of deep learning techniques has opened up new avenues for research and innovation in the field of speech processing, with far-reaching implications for a range of industries and applications. This review paper provides a comprehensive overview of the key deep learning models and their applications in speech-processing tasks. We begin by tracing the evolution of speech processing research, from early approaches, such as MFCC and HMM, to more recent advances in deep learning architectures, such as CNNs, RNNs, transformers, conformers, and diffusion models. We categorize the approaches and compare their strengths and weaknesses for solving speech-processing tasks. Furthermore, we extensively cover various speech-processing tasks, datasets, and benchmarks used in the literature and describe how different deep-learning networks have been utilized to tackle these tasks. Additionally, we discuss the challenges and future directions of deep learning in speech processing, including the need for more parameter-efficient, interpretable models and the potential of deep learning for multimodal speech processing. By examining the field's evolution, comparing and contrasting different approaches, and highlighting future directions and challenges, we hope to inspire further research in this exciting and rapidly advancing field.
Psychologically-Inspired Causal Prompts
May 02, 2023



NLP datasets are richer than just input-output pairs; rather, they carry causal relations between the input and output variables. In this work, we take sentiment classification as an example and look into the causal relations between the review (X) and sentiment (Y). As psychology studies show that language can affect emotion, different psychological processes are evoked when a person first makes a rating and then self-rationalizes their feeling in a review (where the sentiment causes the review, i.e., Y -> X), versus first describes their experience, and weighs the pros and cons to give a final rating (where the review causes the sentiment, i.e., X -> Y ). Furthermore, it is also a completely different psychological process if an annotator infers the original rating of the user by theory of mind (ToM) (where the review causes the rating, i.e., X -ToM-> Y ). In this paper, we verbalize these three causal mechanisms of human psychological processes of sentiment classification into three different causal prompts, and study (1) how differently they perform, and (2) what nature of sentiment classification data leads to agreement or diversity in the model responses elicited by the prompts. We suggest future work raise awareness of different causal structures in NLP tasks. Our code and data are at https://github.com/cogito233/psych-causal-prompt
Evaluating Parameter-Efficient Transfer Learning Approaches on SURE Benchmark for Speech Understanding
Mar 02, 2023Fine-tuning is widely used as the default algorithm for transfer learning from pre-trained models. Parameter inefficiency can however arise when, during transfer learning, all the parameters of a large pre-trained model need to be updated for individual downstream tasks. As the number of parameters grows, fine-tuning is prone to overfitting and catastrophic forgetting. In addition, full fine-tuning can become prohibitively expensive when the model is used for many tasks. To mitigate this issue, parameter-efficient transfer learning algorithms, such as adapters and prefix tuning, have been proposed as a way to introduce a few trainable parameters that can be plugged into large pre-trained language models such as BERT, and HuBERT. In this paper, we introduce the Speech UndeRstanding Evaluation (SURE) benchmark for parameter-efficient learning for various speech-processing tasks. Additionally, we introduce a new adapter, ConvAdapter, based on 1D convolution. We show that ConvAdapter outperforms the standard adapters while showing comparable performance against prefix tuning and LoRA with only 0.94% of trainable parameters on some of the task in SURE. We further explore the effectiveness of parameter efficient transfer learning for speech synthesis task such as Text-to-Speech (TTS).
Natural Language Processing for Policymaking
Feb 07, 2023Language is the medium for many political activities, from campaigns to news reports. Natural language processing (NLP) uses computational tools to parse text into key information that is needed for policymaking. In this chapter, we introduce common methods of NLP, including text classification, topic modeling, event extraction, and text scaling. We then overview how these methods can be used for policymaking through four major applications including data collection for evidence-based policymaking, interpretation of political decisions, policy communication, and investigation of policy effects. Finally, we highlight some potential limitations and ethical concerns when using NLP for policymaking. This text is from Chapter 7 (pages 141-162) of the Handbook of Computational Social Science for Policy (2023). Open Access on Springer: https://doi.org/10.1007/978-3-031-16624-2
Understanding Stereotypes in Language Models: Towards Robust Measurement and Zero-Shot Debiasing
Dec 20, 2022Generated texts from large pretrained language models have been shown to exhibit a variety of harmful, human-like biases about various demographics. These findings prompted large efforts aiming to understand and measure such effects, with the goal of providing benchmarks that can guide the development of techniques mitigating these stereotypical associations. However, as recent research has pointed out, the current benchmarks lack a robust experimental setup, consequently hindering the inference of meaningful conclusions from their evaluation metrics. In this paper, we extend these arguments and demonstrate that existing techniques and benchmarks aiming to measure stereotypes tend to be inaccurate and consist of a high degree of experimental noise that severely limits the knowledge we can gain from benchmarking language models based on them. Accordingly, we propose a new framework for robustly measuring and quantifying biases exhibited by generative language models. Finally, we use this framework to investigate GPT-3's occupational gender bias and propose prompting techniques for mitigating these biases without the need for fine-tuning.
Two is Better than Many? Binary Classification as an Effective Approach to Multi-Choice Question Answering
Oct 29, 2022We propose a simple refactoring of multi-choice question answering (MCQA) tasks as a series of binary classifications. The MCQA task is generally performed by scoring each (question, answer) pair normalized over all the pairs, and then selecting the answer from the pair that yield the highest score. For n answer choices, this is equivalent to an n-class classification setup where only one class (true answer) is correct. We instead show that classifying (question, true answer) as positive instances and (question, false answer) as negative instances is significantly more effective across various models and datasets. We show the efficacy of our proposed approach in different tasks -- abductive reasoning, commonsense question answering, science question answering, and sentence completion. Our DeBERTa binary classification model reaches the top or close to the top performance on public leaderboards for these tasks. The source code of the proposed approach is available at https://github.com/declare-lab/TEAM.
Adaptable Claim Rewriting with Offline Reinforcement Learning for Effective Misinformation Discovery
Oct 14, 2022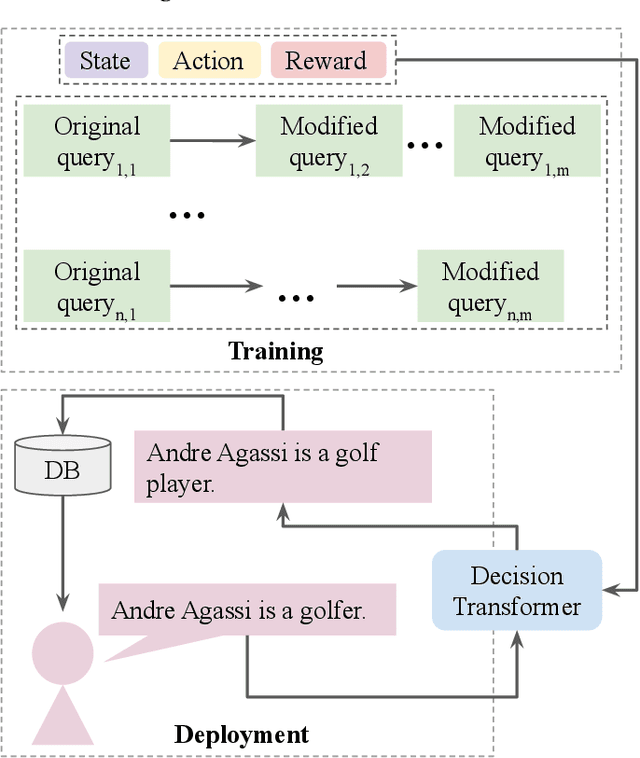
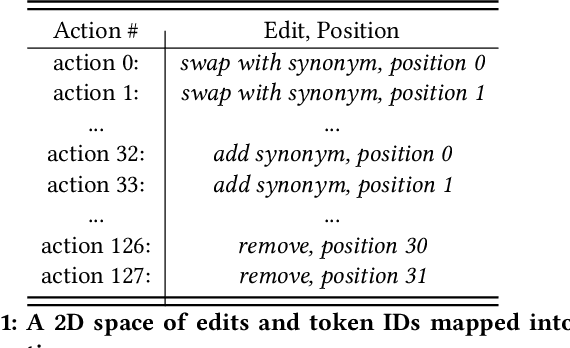
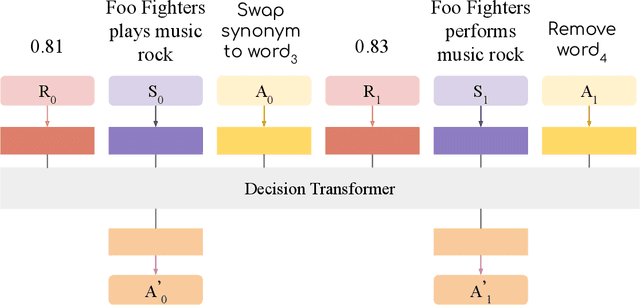

We propose a novel system to help fact-checkers formulate search queries for known misinformation claims and effectively search across multiple social media platforms. We introduce an adaptable rewriting strategy, where editing actions (e.g., swap a word with its synonym; change verb tense into present simple) for queries containing claims are automatically learned through offline reinforcement learning. Specifically, we use a decision transformer to learn a sequence of editing actions that maximize query retrieval metrics such as mean average precision. Through several experiments, we show that our approach can increase the effectiveness of the queries by up to 42\% relatively, while producing editing action sequences that are human readable, thus making the system easy to use and explain.
Multiview Contextual Commonsense Inference: A New Dataset and Task
Oct 06, 2022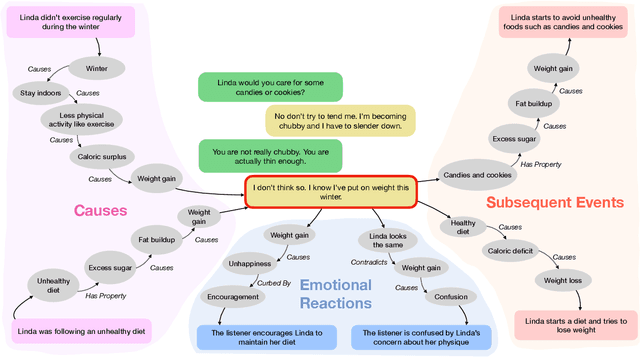
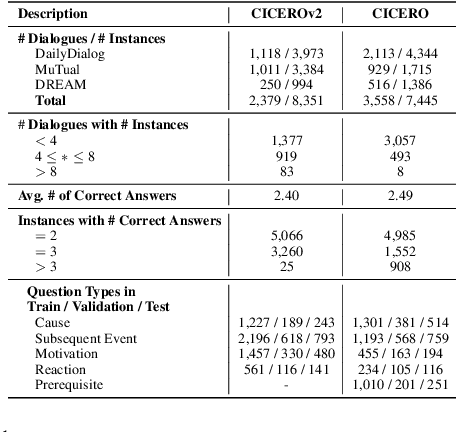

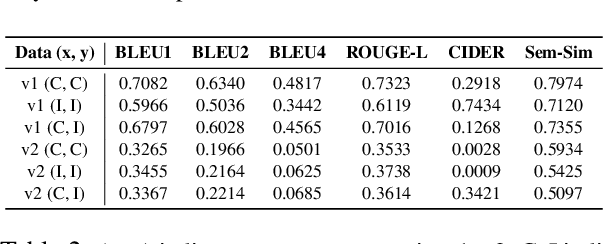
Contextual commonsense inference is the task of generating various types of explanations around the events in a dyadic dialogue, including cause, motivation, emotional reaction, and others. Producing a coherent and non-trivial explanation requires awareness of the dialogue's structure and of how an event is grounded in the context. In this work, we create CICEROv2, a dataset consisting of 8,351 instances from 2,379 dialogues, containing multiple human-written answers for each contextual commonsense inference question, representing a type of explanation on cause, subsequent event, motivation, and emotional reaction. We show that the inferences in CICEROv2 are more semantically diverse than other contextual commonsense inference datasets. To solve the inference task, we propose a collection of pre-training objectives, including concept denoising and utterance sorting to prepare a pre-trained model for the downstream contextual commonsense inference task. Our results show that the proposed pre-training objectives are effective at adapting the pre-trained T5-Large model for the contextual commonsense inference task.