 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Generative Modeling for Controllable Speech Synthesis
Oct 03, 2019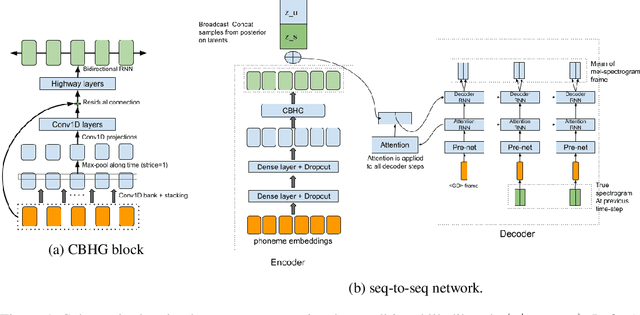


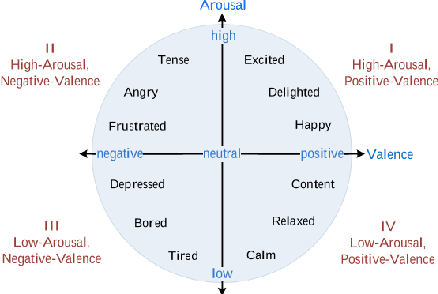
We present a novel generative model that combines state-of-the-art neural text-to-speech (TTS) with semi-supervised probabilistic latent variable models. By providing partial supervision to some of the latent variables, we are able to force them to take on consistent and interpretable purposes, which previously hasn't been possible with purely unsupervised TTS models. We demonstrate that our model is able to reliably discover and control important but rarely labelled attributes of speech, such as affect and speaking rate, with as little as 1% (30 minutes) supervision. Even at such low supervision levels we do not observe a degradation of synthesis quality compared to a state-of-the-art baseline. Audio samples are available on the web.
Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
Jul 24, 2019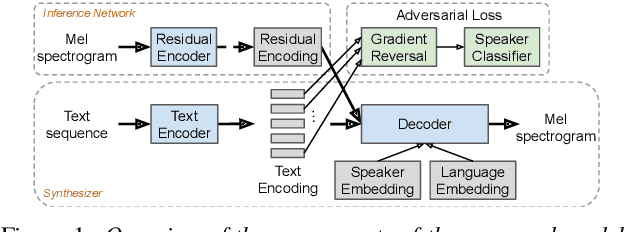
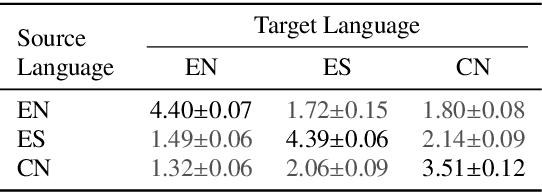
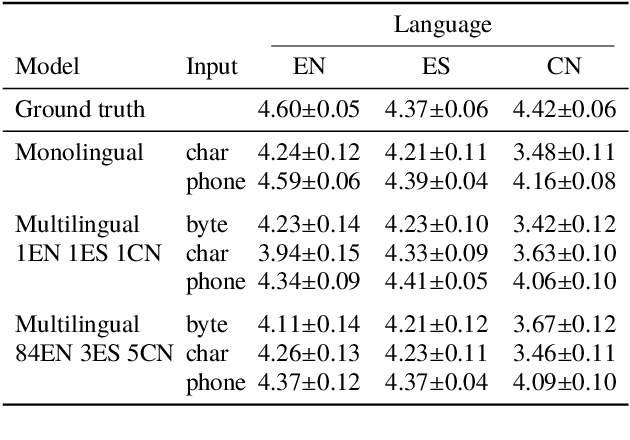
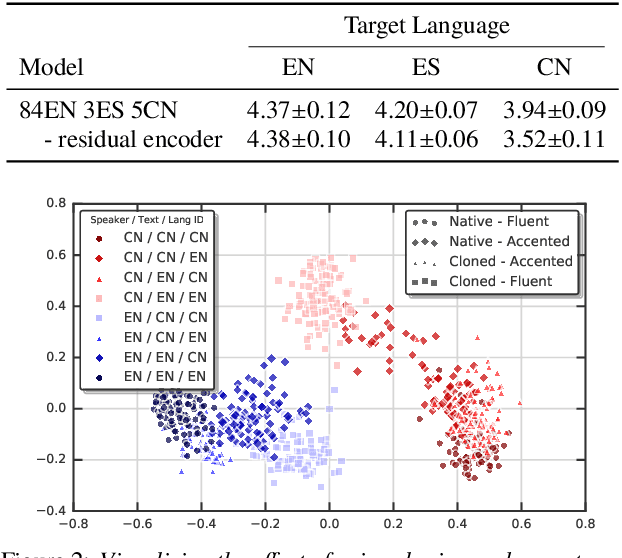
We present a multispeaker, multilingual text-to-speech (TTS) synthesis model based on Tacotron that is able to produce high quality speech in multiple languages. Moreover, the model is able to transfer voices across languages, e.g. synthesize fluent Spanish speech using an English speaker's voice, without training on any bilingual or parallel examples. Such transfer works across distantly related languages, e.g. English and Mandarin. Critical to achieving this result are: 1. using a phonemic input representation to encourage sharing of model capacity across languages, and 2. incorporating an adversarial loss term to encourage the model to disentangle its representation of speaker identity (which is perfectly correlated with language in the training data) from the speech content. Further scaling up the model by training on multiple speakers of each language, and incorporating an autoencoding input to help stabilize attention during training, results in a model which can be used to consistently synthesize intelligible speech for training speakers in all languages seen during training, and in native or foreign accents.
Effective Use of Variational Embedding Capacity in Expressive End-to-End Speech Synthesis
Jul 09, 2019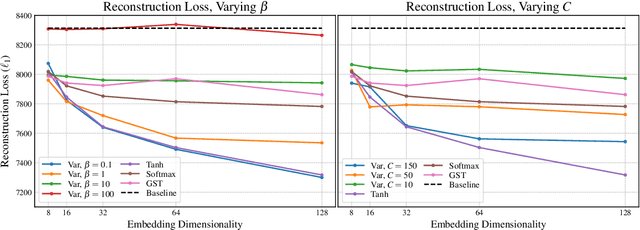
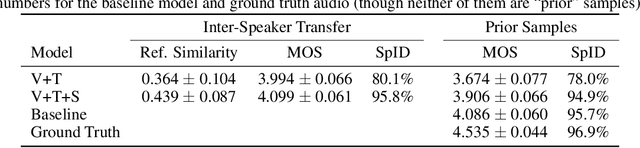
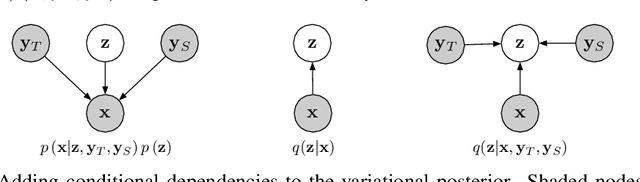
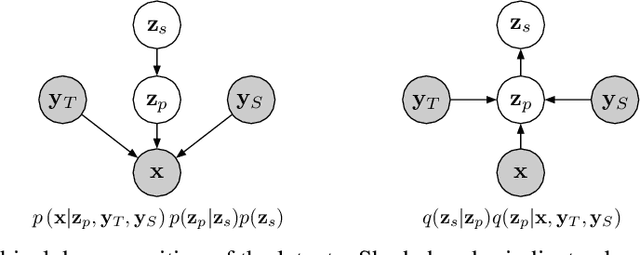
Recent work has explored sequence-to-sequence latent variable models for expressive speech synthesis (supporting control and transfer of prosody and style), but has not presented a coherent framework for understanding the trade-offs between the competing methods. In this paper, we propose embedding capacity as a unified method of analyzing the behavior of latent variable models of speech, comparing existing heuristic (non-variational) methods to variational methods that are able to explicitly constrain capacity using an upper bound on representational mutual information. In our proposed model (Capacitron), we show that by adding conditional dependencies to the variational posterior such that it matches the form of the true posterior, the same model can be used for high-precision prosody transfer, text-agnostic style transfer, and generation of natural-sounding prior samples. For multi-speaker models, Capacitron is able to preserve target speaker identity during inter-speaker prosody transfer and when drawing samples from the latent prior. Lastly, we introduce a method for decomposing embedding capacity hierarchically across two sets of latents, allowing a portion of the latent variability to be specified and the remaining variability sampled from a learned prior.
Semi-Supervised Training for Improving Data Efficiency in End-to-End Speech Synthesis
Aug 30, 2018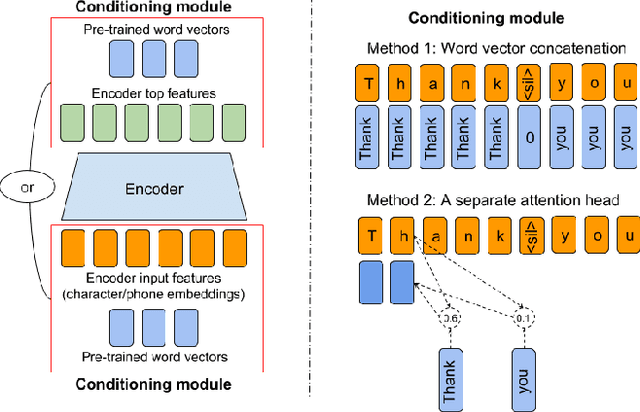
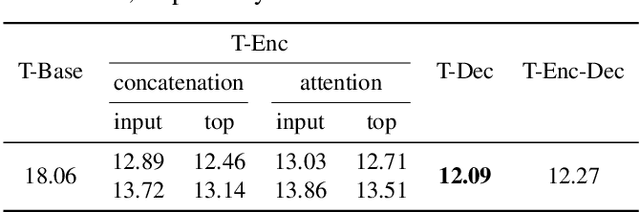
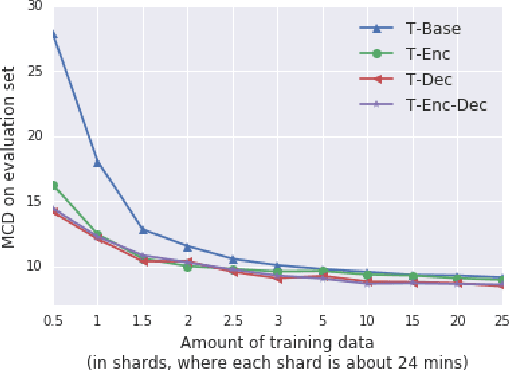
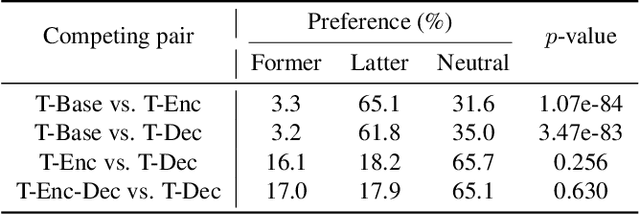
Although end-to-end text-to-speech (TTS) models such as Tacotron have shown excellent results, they typically require a sizable set of high-quality <text, audio> pairs for training, which are expensive to collect. In this paper, we propose a semi-supervised training framework to improve the data efficiency of Tacotron. The idea is to allow Tacotron to utilize textual and acoustic knowledge contained in large, publicly-available text and speech corpora. Importantly, these external data are unpaired and potentially noisy. Specifically, first we embed each word in the input text into word vectors and condition the Tacotron encoder on them. We then use an unpaired speech corpus to pre-train the Tacotron decoder in the acoustic domain. Finally, we fine-tune the model using available paired data. We demonstrate that the proposed framework enables Tacotron to generate intelligible speech using less than half an hour of paired training data.
Predicting Expressive Speaking Style From Text In End-To-End Speech Synthesis
Aug 04, 2018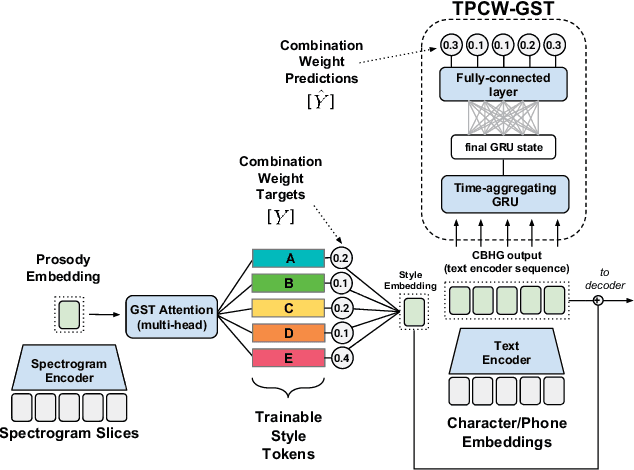

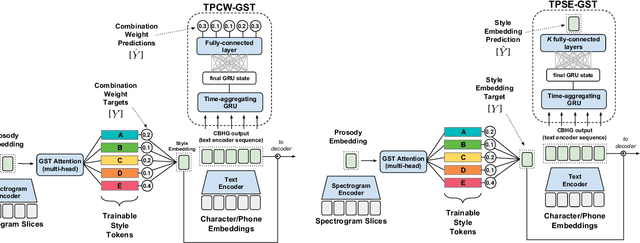

Global Style Tokens (GSTs) are a recently-proposed method to learn latent disentangled representations of high-dimensional data. GSTs can be used within Tacotron, a state-of-the-art end-to-end text-to-speech synthesis system, to uncover expressive factors of variation in speaking style. In this work, we introduce the Text-Predicted Global Style Token (TP-GST) architecture, which treats GST combination weights or style embeddings as "virtual" speaking style labels within Tacotron. TP-GST learns to predict stylistic renderings from text alone, requiring neither explicit labels during training nor auxiliary inputs for inference. We show that, when trained on a dataset of expressive speech, our system generates audio with more pitch and energy variation than two state-of-the-art baseline models. We further demonstrate that TP-GSTs can synthesize speech with background noise removed, and corroborate these analyses with positive results on human-rated listener preference audiobook tasks. Finally, we demonstrate that multi-speaker TP-GST models successfully factorize speaker identity and speaking style. We provide a website with audio samples for each of our findings.
Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron
Mar 24, 2018
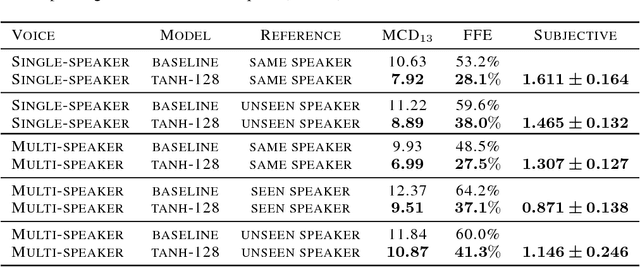

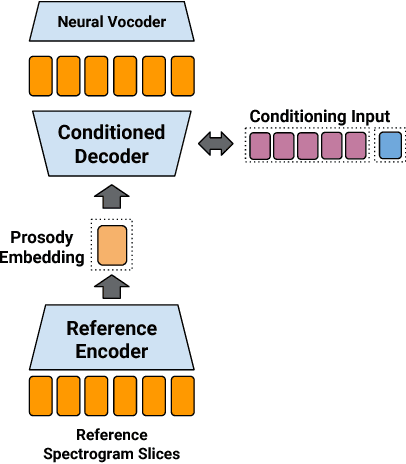
We present an extension to the Tacotron speech synthesis architecture that learns a latent embedding space of prosody, derived from a reference acoustic representation containing the desired prosody. We show that conditioning Tacotron on this learned embedding space results in synthesized audio that matches the prosody of the reference signal with fine time detail even when the reference and synthesis speakers are different. Additionally, we show that a reference prosody embedding can be used to synthesize text that is different from that of the reference utterance. We define several quantitative and subjective metrics for evaluating prosody transfer, and report results with accompanying audio samples from single-speaker and 44-speaker Tacotron models on a prosody transfer task.
Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis
Mar 23, 2018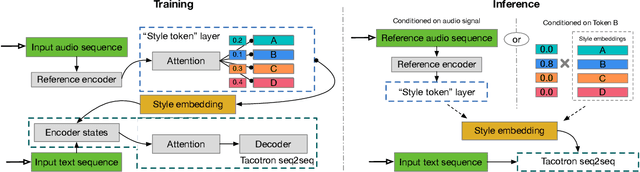
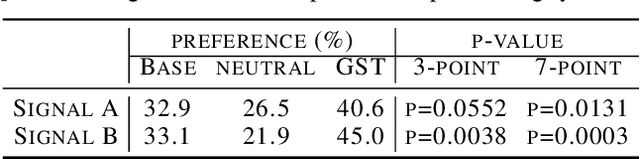
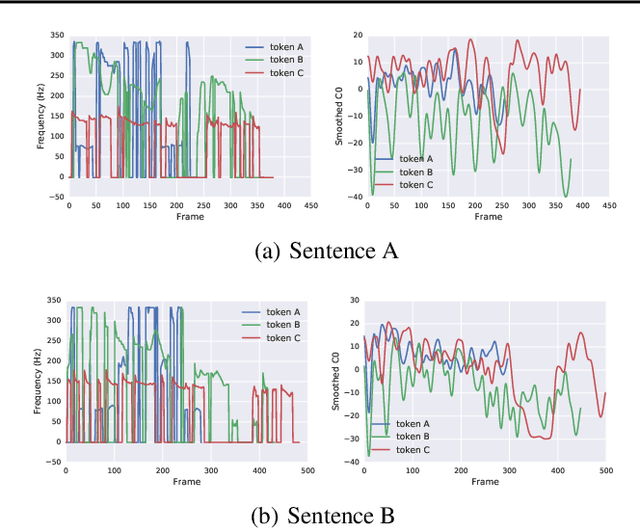

In this work, we propose "global style tokens" (GSTs), a bank of embeddings that are jointly trained within Tacotron, a state-of-the-art end-to-end speech synthesis system. The embeddings are trained with no explicit labels, yet learn to model a large range of acoustic expressiveness. GSTs lead to a rich set of significant results. The soft interpretable "labels" they generate can be used to control synthesis in novel ways, such as varying speed and speaking style - independently of the text content. They can also be used for style transfer, replicating the speaking style of a single audio clip across an entire long-form text corpus. When trained on noisy, unlabeled found data, GSTs learn to factorize noise and speaker identity, providing a path towards highly scalable but robust speech synthesis.
Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions
Feb 16, 2018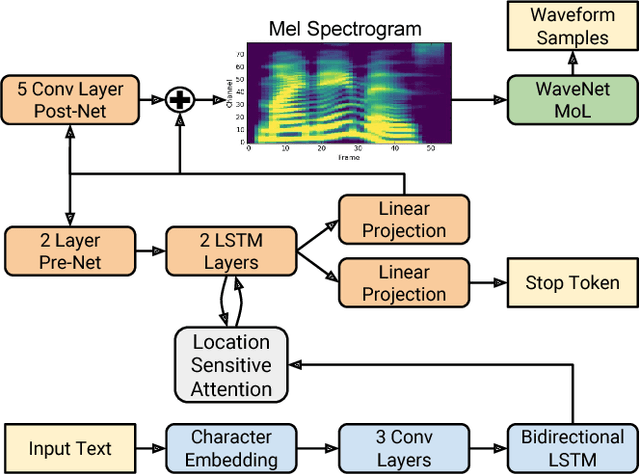

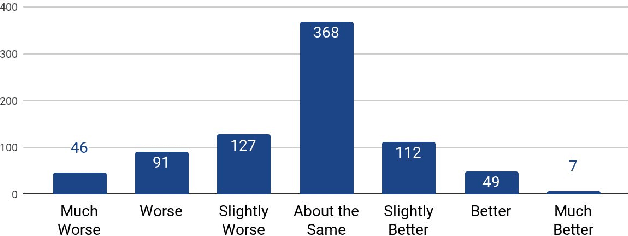
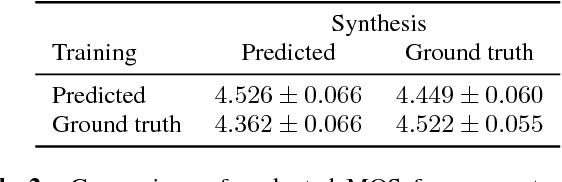
This paper describes Tacotron 2, a neural network architecture for speech synthesis directly from text. The system is composed of a recurrent sequence-to-sequence feature prediction network that maps character embeddings to mel-scale spectrograms, followed by a modified WaveNet model acting as a vocoder to synthesize timedomain waveforms from those spectrograms. Our model achieves a mean opinion score (MOS) of $4.53$ comparable to a MOS of $4.58$ for professionally recorded speech. To validate our design choices, we present ablation studies of key components of our system and evaluate the impact of using mel spectrograms as the input to WaveNet instead of linguistic, duration, and $F_0$ features. We further demonstrate that using a compact acoustic intermediate representation enables significant simplification of the WaveNet architecture.
Uncovering Latent Style Factors for Expressive Speech Synthesis
Nov 01, 2017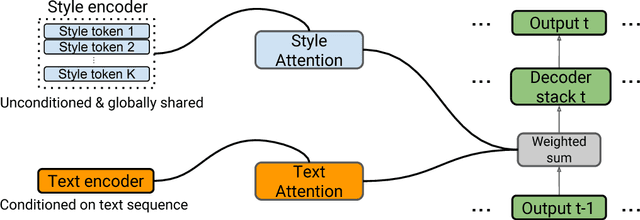
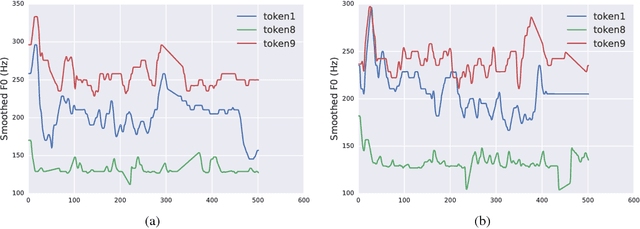
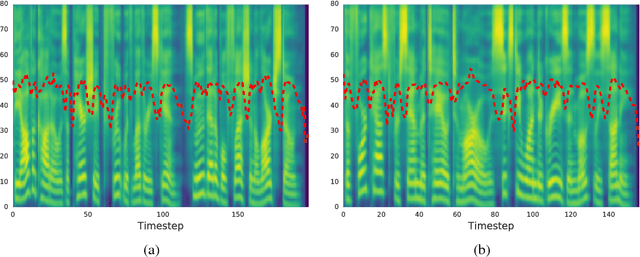
Prosodic modeling is a core problem in speech synthesis. The key challenge is producing desirable prosody from textual input containing only phonetic information. In this preliminary study, we introduce the concept of "style tokens" in Tacotron, a recently proposed end-to-end neural speech synthesis model. Using style tokens, we aim to extract independent prosodic styles from training data. We show that without annotation data or an explicit supervision signal, our approach can automatically learn a variety of prosodic variations in a purely data-driven way. Importantly, each style token corresponds to a fixed style factor regardless of the given text sequence. As a result, we can control the prosodic style of synthetic speech in a somewhat predictable and globally consistent way.
Tacotron: Towards End-to-End Speech Synthesis
Apr 06, 2017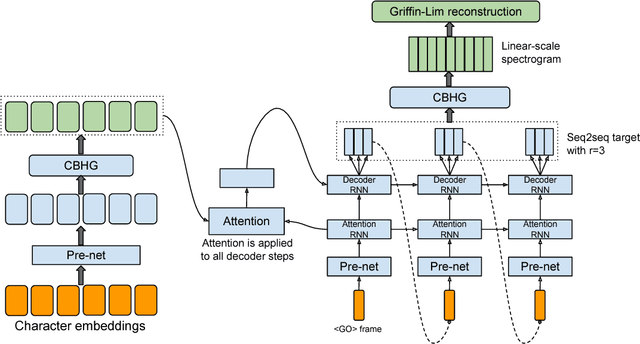
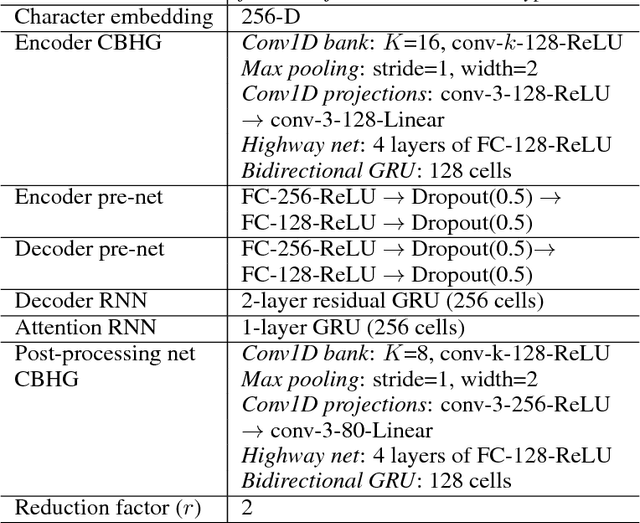
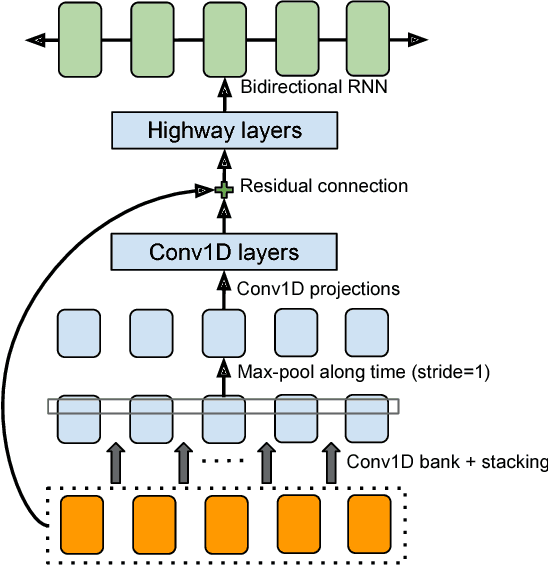
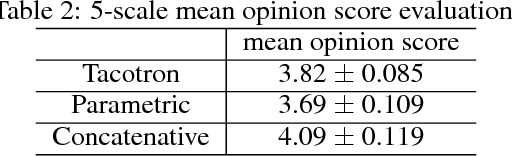
A text-to-speech synthesis system typically consists of multiple stages, such as a text analysis frontend, an acoustic model and an audio synthesis module. Building these components often requires extensive domain expertise and may contain brittle design choices. In this paper, we present Tacotron, an end-to-end generative text-to-speech model that synthesizes speech directly from characters. Given <text, audio> pairs, the model can be trained completely from scratch with random initialization. We present several key techniques to make the sequence-to-sequence framework perform well for this challenging task. Tacotron achieves a 3.82 subjective 5-scale mean opinion score on US English, outperforming a production parametric system in terms of naturalness. In addition, since Tacotron generates speech at the frame level, it's substantially faster than sample-level autoregressive methods.