 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning deep representations by mutual information estimation and maximization
Oct 03, 2018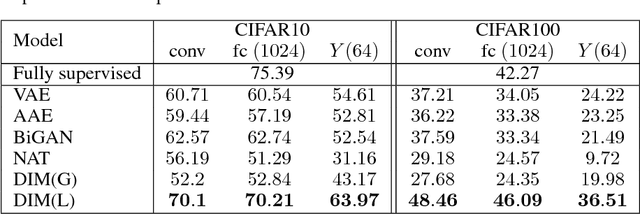
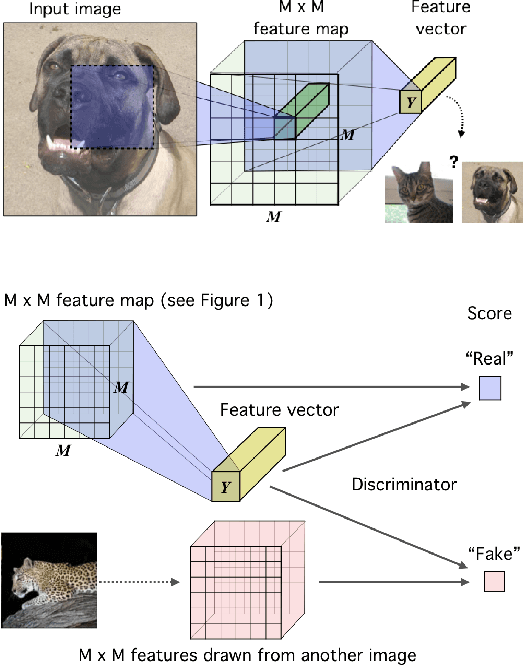
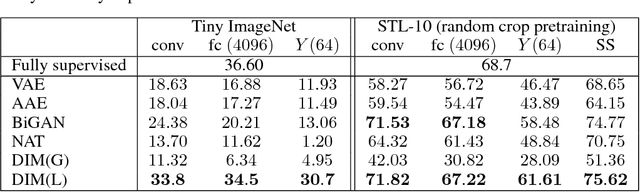
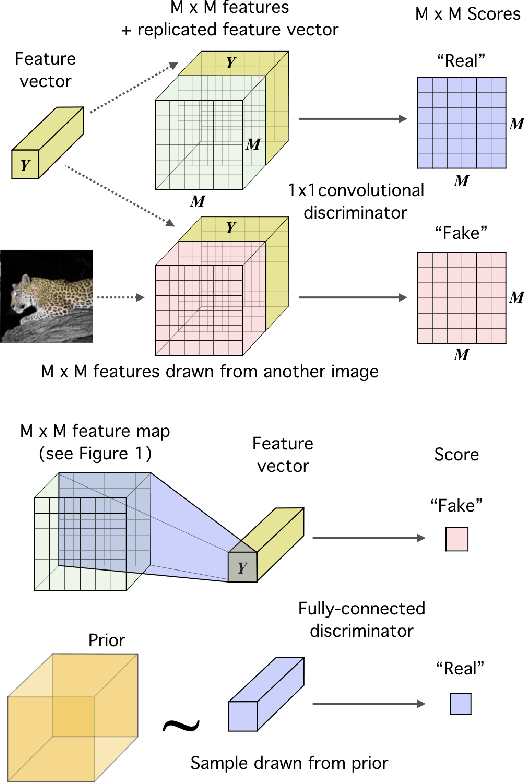
In this work, we perform unsupervised learning of representations by maximizing mutual information between an input and the output of a deep neural network encoder. Importantly, we show that structure matters: incorporating knowledge about locality of the input to the objective can greatly influence a representation's suitability for downstream tasks. We further control characteristics of the representation by matching to a prior distribution adversarially. Our method, which we call Deep InfoMax (DIM), outperforms a number of popular unsupervised learning methods and competes with fully-supervised learning on several classification tasks. DIM opens new avenues for unsupervised learning of representations and is an important step towards flexible formulations of representation-learning objectives for specific end-goals.
Deep Graph Infomax
Sep 27, 2018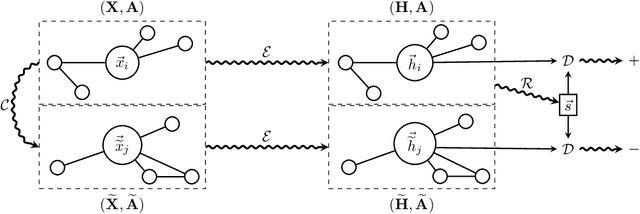
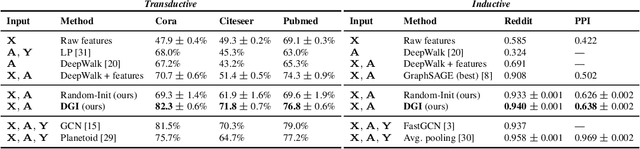
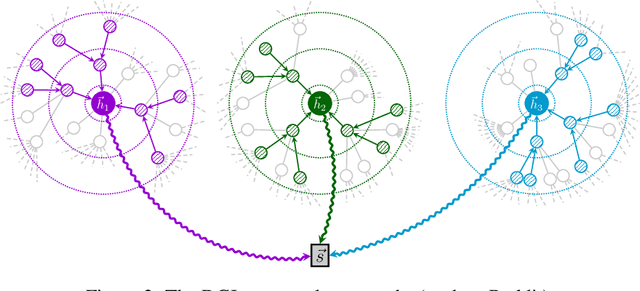

We present Deep Graph Infomax (DGI), a general approach for learning node representations within graph-structured data in an unsupervised manner. DGI relies on maximizing mutual information between patch representations and corresponding high-level summaries of graphs---both derived using established graph convolutional network architectures. The learnt patch representations summarize subgraphs centered around nodes of interest, and can thus be reused for downstream node-wise learning tasks. In contrast to most prior approaches to graph representation learning, DGI does not rely on random walks, and is readily applicable to both transductive and inductive learning setups. We demonstrate competitive performance on a variety of node classification benchmarks, which at times even exceeds the performance of supervised learning.
On-line Adaptative Curriculum Learning for GANs
Sep 12, 2018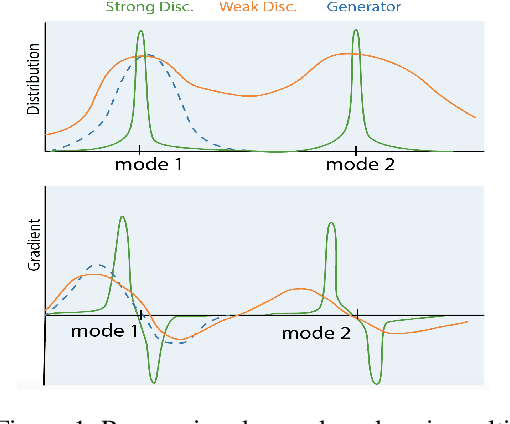


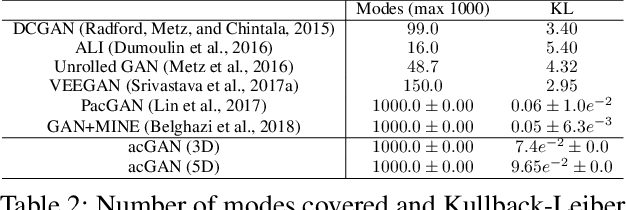
Generative Adversarial Networks (GANs) can successfully approximate a probability distribution and produce realistic samples. However, open questions such as sufficient convergence conditions and mode collapse still persist. In this paper, we build on existing work in the area by proposing a novel framework for training the generator against an ensemble of discriminator networks, which can be seen as a one-student/multiple-teachers setting. We formalize this problem within the full-information adversarial bandit framework, where we evaluate the capability of an algorithm to select mixtures of discriminators for providing the generator with feedback during learning. To this end, we propose a reward function which reflects the progress made by the generator and dynamically update the mixture weights allocated to each discriminator. We also draw connections between our algorithm and stochastic optimization methods and then show that existing approaches using multiple discriminators in literature can be recovered from our framework. We argue that less expressive discriminators are smoother and have a general coarse grained view of the modes map, which enforces the generator to cover a wide portion of the data distribution support. On the other hand, highly expressive discriminators ensure samples quality. Finally, experimental results show that our approach improves samples quality and diversity over existing baselines by effectively learning a curriculum. These results also support the claim that weaker discriminators have higher entropy improving modes coverage.
Spatio-temporal Dynamics of Intrinsic Networks in Functional Magnetic Imaging Data Using Recurrent Neural Networks
Aug 27, 2018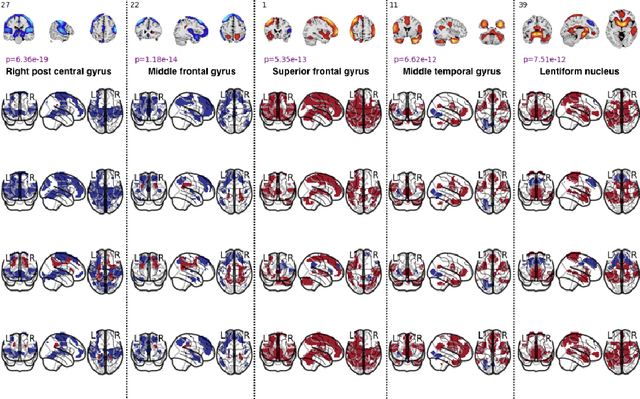
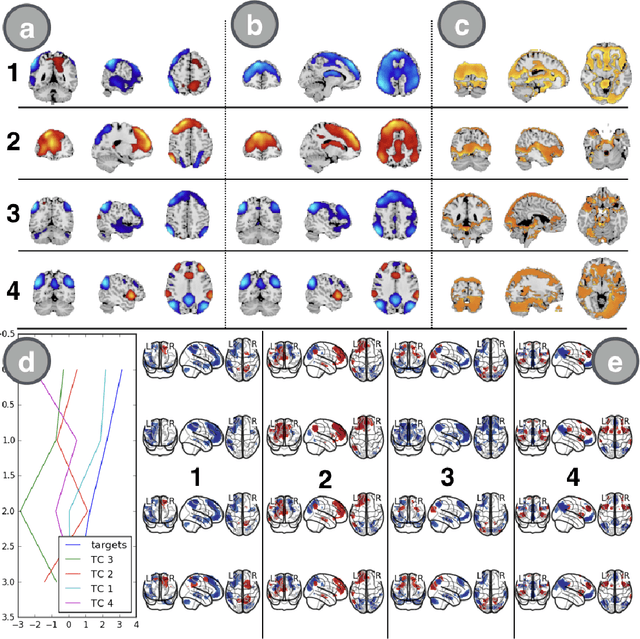
We introduce a novel recurrent neural network (RNN) approach to account for temporal dynamics and dependencies in brain networks observed via functional magnetic resonance imaging (fMRI). Our approach directly parameterizes temporal dynamics through recurrent connections, which can be used to formulate blind source separation with a conditional (rather than marginal) independence assumption, which we call RNN-ICA. This formulation enables us to visualize the temporal dynamics of both first order (activity) and second order (directed connectivity) information in brain networks that are widely studied in a static sense, but not well-characterized dynamically. RNN-ICA predicts dynamics directly from the recurrent states of the RNN in both task and resting state fMRI. Our results show both task-related and group-differentiating directed connectivity.
Variance Regularizing Adversarial Learning
Aug 19, 2018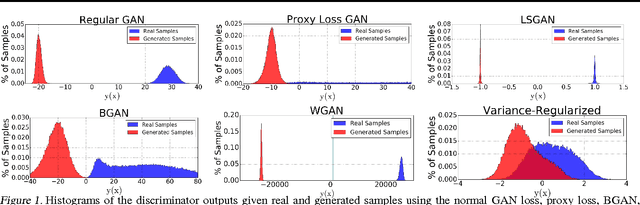

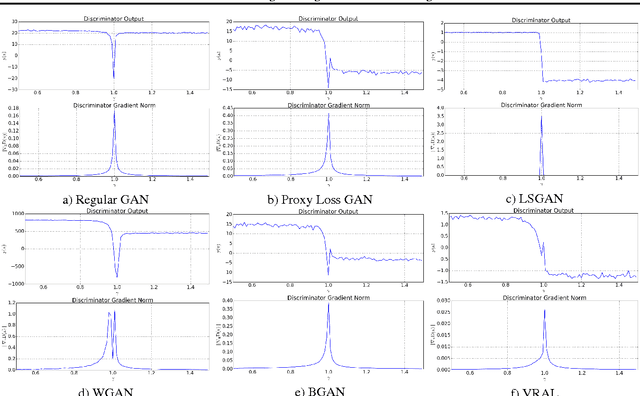

We introduce a novel approach for training adversarial models by replacing the discriminator score with a bi-modal Gaussian distribution over the real/fake indicator variables. In order to do this, we train the Gaussian classifier to match the target bi-modal distribution implicitly through meta-adversarial training. We hypothesize that this approach ensures a non-zero gradient to the generator, even in the limit of a perfect classifier. We test our method against standard benchmark image datasets as well as show the classifier output distribution is smooth and has overlap between the real and fake modes.
MINE: Mutual Information Neural Estimation
Jun 07, 2018


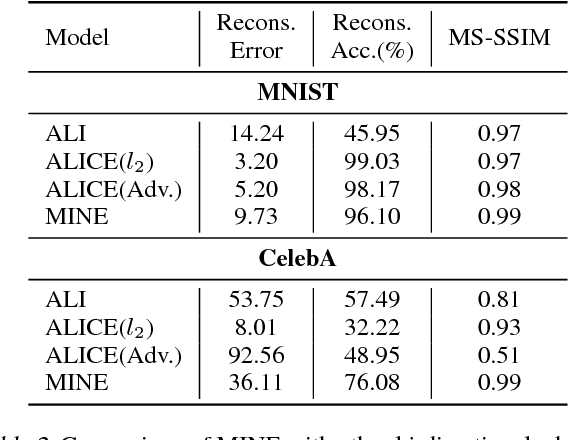
We argue that the estimation of mutual information between high dimensional continuous random variables can be achieved by gradient descent over neural networks. We present a Mutual Information Neural Estimator (MINE) that is linearly scalable in dimensionality as well as in sample size, trainable through back-prop, and strongly consistent. We present a handful of applications on which MINE can be used to minimize or maximize mutual information. We apply MINE to improve adversarially trained generative models. We also use MINE to implement Information Bottleneck, applying it to supervised classification; our results demonstrate substantial improvement in flexibility and performance in these settings.
* 19 pages, 6 figures
Boundary-Seeking Generative Adversarial Networks
Feb 21, 2018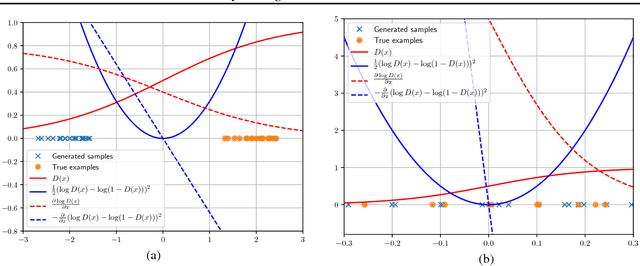

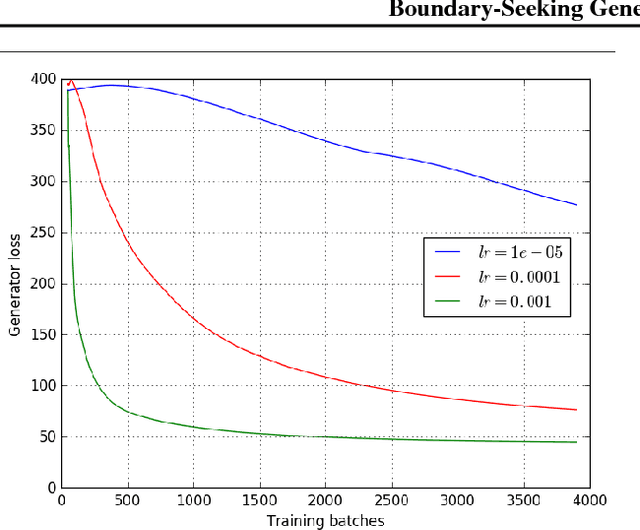
Generative adversarial networks (GANs) are a learning framework that rely on training a discriminator to estimate a measure of difference between a target and generated distributions. GANs, as normally formulated, rely on the generated samples being completely differentiable w.r.t. the generative parameters, and thus do not work for discrete data. We introduce a method for training GANs with discrete data that uses the estimated difference measure from the discriminator to compute importance weights for generated samples, thus providing a policy gradient for training the generator. The importance weights have a strong connection to the decision boundary of the discriminator, and we call our method boundary-seeking GANs (BGANs). We demonstrate the effectiveness of the proposed algorithm with discrete image and character-based natural language generation. In addition, the boundary-seeking objective extends to continuous data, which can be used to improve stability of training, and we demonstrate this on Celeba, Large-scale Scene Understanding (LSUN) bedrooms, and Imagenet without conditioning.
Iterative Refinement of the Approximate Posterior for Directed Belief Networks
Feb 20, 2018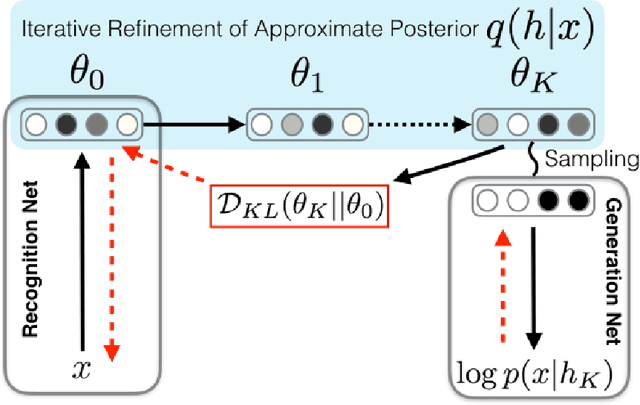
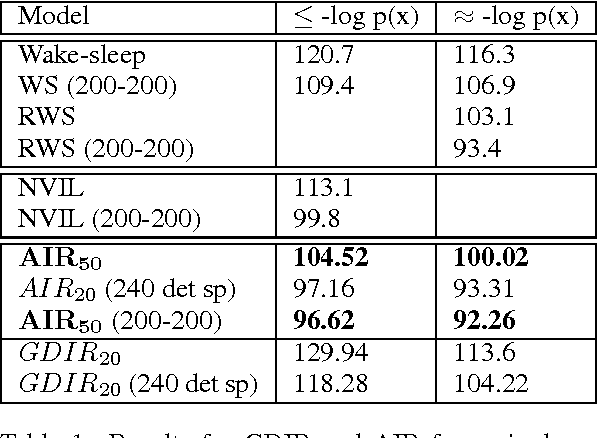

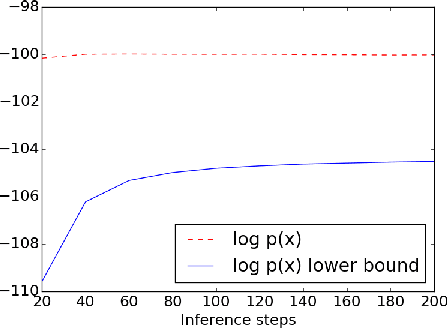
Variational methods that rely on a recognition network to approximate the posterior of directed graphical models offer better inference and learning than previous methods. Recent advances that exploit the capacity and flexibility in this approach have expanded what kinds of models can be trained. However, as a proposal for the posterior, the capacity of the recognition network is limited, which can constrain the representational power of the generative model and increase the variance of Monte Carlo estimates. To address these issues, we introduce an iterative refinement procedure for improving the approximate posterior of the recognition network and show that training with the refined posterior is competitive with state-of-the-art methods. The advantages of refinement are further evident in an increased effective sample size, which implies a lower variance of gradient estimates.
ACtuAL: Actor-Critic Under Adversarial Learning
Nov 13, 2017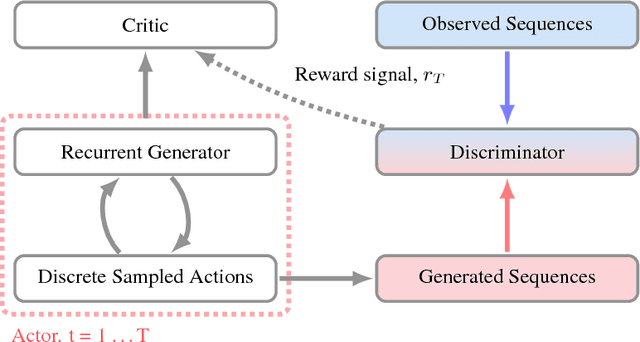
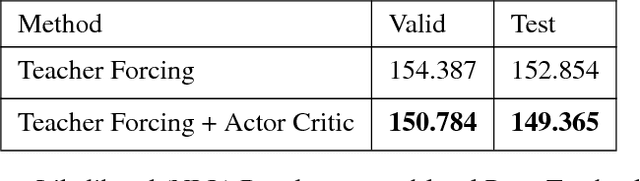
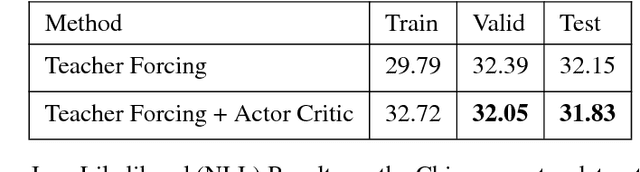

Generative Adversarial Networks (GANs) are a powerful framework for deep generative modeling. Posed as a two-player minimax problem, GANs are typically trained end-to-end on real-valued data and can be used to train a generator of high-dimensional and realistic images. However, a major limitation of GANs is that training relies on passing gradients from the discriminator through the generator via back-propagation. This makes it fundamentally difficult to train GANs with discrete data, as generation in this case typically involves a non-differentiable function. These difficulties extend to the reinforcement learning setting when the action space is composed of discrete decisions. We address these issues by reframing the GAN framework so that the generator is no longer trained using gradients through the discriminator, but is instead trained using a learned critic in the actor-critic framework with a Temporal Difference (TD) objective. This is a natural fit for sequence modeling and we use it to achieve improvements on language modeling tasks over the standard Teacher-Forcing methods.
Maximum-Likelihood Augmented Discrete Generative Adversarial Networks
Feb 26, 2017


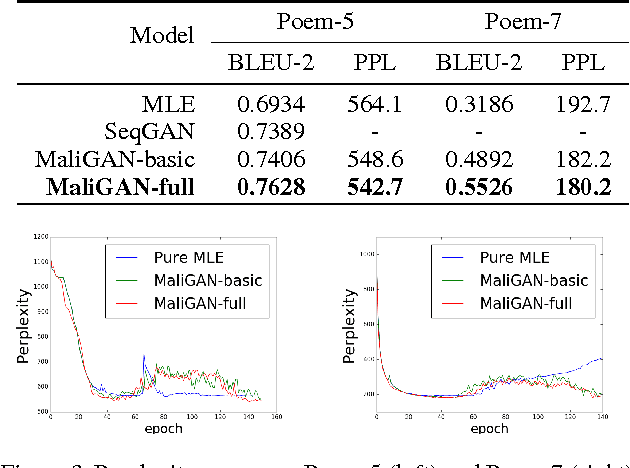
Despite the successes in capturing continuous distributions, the application of generative adversarial networks (GANs) to discrete settings, like natural language tasks, is rather restricted. The fundamental reason is the difficulty of back-propagation through discrete random variables combined with the inherent instability of the GAN training objective. To address these problems, we propose Maximum-Likelihood Augmented Discrete Generative Adversarial Networks. Instead of directly optimizing the GAN objective, we derive a novel and low-variance objective using the discriminator's output that follows corresponds to the log-likelihood. Compared with the original, the new objective is proved to be consistent in theory and beneficial in practice. The experimental results on various discrete datasets demonstrate the effectiveness of the proposed approach.