 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Really is Commonsense Knowledge?
Nov 06, 2024



Commonsense datasets have been well developed in Natural Language Processing, mainly through crowdsource human annotation. However, there are debates on the genuineness of commonsense reasoning benchmarks. In specific, a significant portion of instances in some commonsense benchmarks do not concern commonsense knowledge. That problem would undermine the measurement of the true commonsense reasoning ability of evaluated models. It is also suggested that the problem originated from a blurry concept of commonsense knowledge, as distinguished from other types of knowledge. To demystify all of the above claims, in this study, we survey existing definitions of commonsense knowledge, ground into the three frameworks for defining concepts, and consolidate them into a multi-framework unified definition of commonsense knowledge (so-called consolidated definition). We then use the consolidated definition for annotations and experiments on the CommonsenseQA and CommonsenseQA 2.0 datasets to examine the above claims. Our study shows that there exists a large portion of non-commonsense-knowledge instances in the two datasets, and a large performance gap on these two subsets where Large Language Models (LLMs) perform worse on commonsense-knowledge instances.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024



Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
ConstraintChecker: A Plugin for Large Language Models to Reason on Commonsense Knowledge Bases
Jan 25, 2024



Reasoning over Commonsense Knowledge Bases (CSKB), i.e. CSKB reasoning, has been explored as a way to acquire new commonsense knowledge based on reference knowledge in the original CSKBs and external prior knowledge. Despite the advancement of Large Language Models (LLM) and prompt engineering techniques in various reasoning tasks, they still struggle to deal with CSKB reasoning. One of the problems is that it is hard for them to acquire explicit relational constraints in CSKBs from only in-context exemplars, due to a lack of symbolic reasoning capabilities (Bengio et al., 2021). To this end, we proposed **ConstraintChecker**, a plugin over prompting techniques to provide and check explicit constraints. When considering a new knowledge instance, ConstraintChecker employs a rule-based module to produce a list of constraints, then it uses a zero-shot learning module to check whether this knowledge instance satisfies all constraints. The acquired constraint-checking result is then aggregated with the output of the main prompting technique to produce the final output. Experimental results on CSKB Reasoning benchmarks demonstrate the effectiveness of our method by bringing consistent improvements over all prompting methods. Codes and data are available at \url{https://github.com/HKUST-KnowComp/ConstraintChecker}.
COLA: Contextualized Commonsense Causal Reasoning from the Causal Inference Perspective
May 09, 2023



Detecting commonsense causal relations (causation) between events has long been an essential yet challenging task. Given that events are complicated, an event may have different causes under various contexts. Thus, exploiting context plays an essential role in detecting causal relations. Meanwhile, previous works about commonsense causation only consider two events and ignore their context, simplifying the task formulation. This paper proposes a new task to detect commonsense causation between two events in an event sequence (i.e., context), called contextualized commonsense causal reasoning. We also design a zero-shot framework: COLA (Contextualized Commonsense Causality Reasoner) to solve the task from the causal inference perspective. This framework obtains rich incidental supervision from temporality and balances covariates from multiple timestamps to remove confounding effects. Our extensive experiments show that COLA can detect commonsense causality more accurately than baselines.
CKBP v2: An Expert-Annotated Evaluation Set for Commonsense Knowledge Base Population
Apr 20, 2023



Populating Commonsense Knowledge Bases (CSKB) is an important yet hard task in NLP, as it tackles knowledge from external sources with unseen events and entities. Fang et al. (2021a) proposed a CSKB Population benchmark with an evaluation set CKBP v1. However, CKBP v1 adopts crowdsourced annotations that suffer from a substantial fraction of incorrect answers, and the evaluation set is not well-aligned with the external knowledge source as a result of random sampling. In this paper, we introduce CKBP v2, a new high-quality CSKB Population benchmark, which addresses the two mentioned problems by using experts instead of crowd-sourced annotation and by adding diversified adversarial samples to make the evaluation set more representative. We conduct extensive experiments comparing state-of-the-art methods for CSKB Population on the new evaluation set for future research comparisons. Empirical results show that the population task is still challenging, even for large language models (LLM) such as ChatGPT. Codes and data are available at https://github.com/HKUST-KnowComp/CSKB-Population.
A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity
Feb 28, 2023



This paper proposes a framework for quantitatively evaluating interactive LLMs such as ChatGPT using publicly available data sets. We carry out an extensive technical evaluation of ChatGPT using 23 data sets covering 8 different common NLP application tasks. We evaluate the multitask, multilingual and multi-modal aspects of ChatGPT based on these data sets and a newly designed multimodal dataset. We find that ChatGPT outperforms LLMs with zero-shot learning on most tasks and even outperforms fine-tuned models on some tasks. We find that it is better at understanding non-Latin script languages than generating them. It is able to generate multimodal content from textual prompts, via an intermediate code generation step. Moreover, we find that ChatGPT is 63.41% accurate on average in 10 different reasoning categories under logical reasoning, non-textual reasoning, and commonsense reasoning, hence making it an unreliable reasoner. It is, for example, better at deductive than inductive reasoning. ChatGPT suffers from hallucination problems like other LLMs and it generates more extrinsic hallucinations from its parametric memory as it does not have access to an external knowledge base. Finally, the interactive feature of ChatGPT enables human collaboration with the underlying LLM to improve its performance, i.e, 8% ROUGE-1 on summarization and 2% ChrF++ on machine translation, in a multi-turn "prompt engineering" fashion. We also release codebase for evaluation set extraction.
PseudoReasoner: Leveraging Pseudo Labels for Commonsense Knowledge Base Population
Oct 14, 2022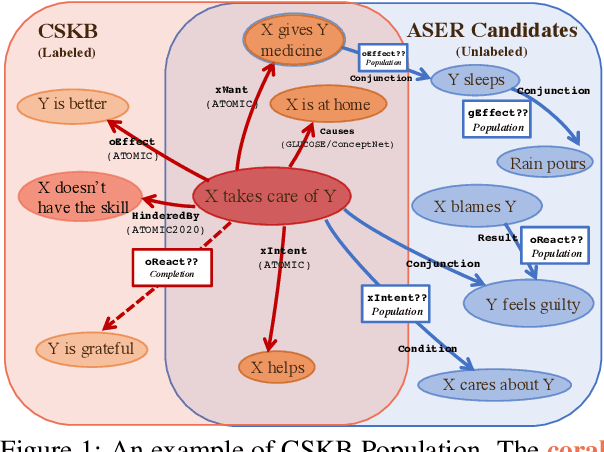

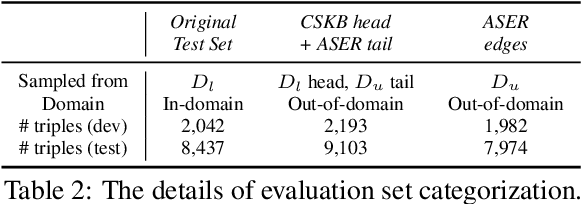
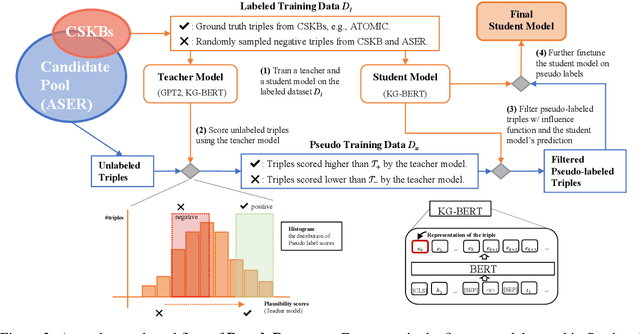
Commonsense Knowledge Base (CSKB) Population aims at reasoning over unseen entities and assertions on CSKBs, and is an important yet hard commonsense reasoning task. One challenge is that it requires out-of-domain generalization ability as the source CSKB for training is of a relatively smaller scale (1M) while the whole candidate space for population is way larger (200M). We propose PseudoReasoner, a semi-supervised learning framework for CSKB population that uses a teacher model pre-trained on CSKBs to provide pseudo labels on the unlabeled candidate dataset for a student model to learn from. The teacher can be a generative model rather than restricted to discriminative models as previous works. In addition, we design a new filtering procedure for pseudo labels based on influence function and the student model's prediction to further improve the performance. The framework can improve the backbone model KG-BERT (RoBERTa-large) by 3.3 points on the overall performance and especially, 5.3 points on the out-of-domain performance, and achieves the state-of-the-art. Codes and data are available at https://github.com/HKUST-KnowComp/PseudoReasoner.