 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Augmented Convolutional Networks
Apr 22, 2019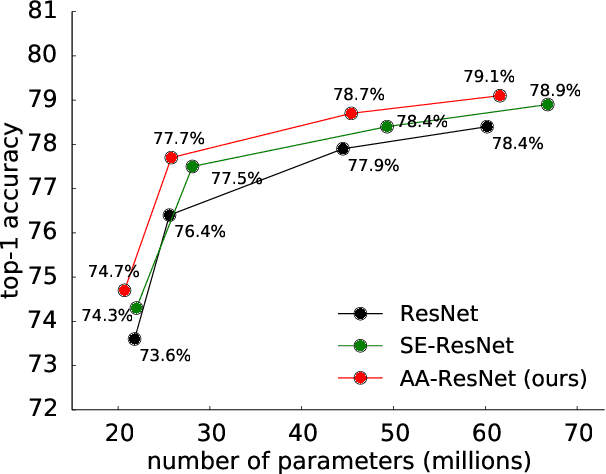
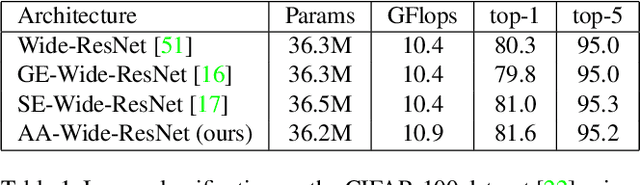
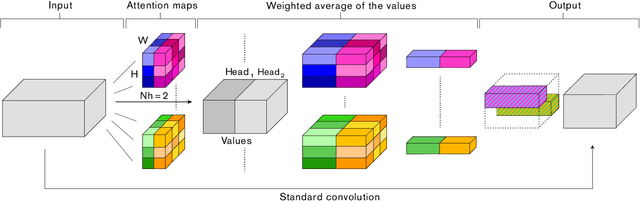
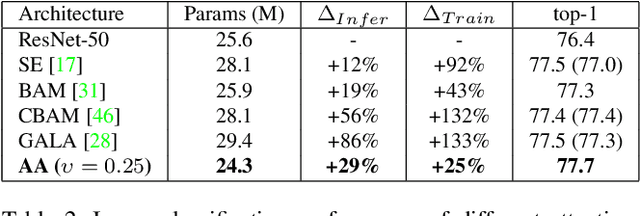
Convolutional networks have been the paradigm of choice in many computer vision applications. The convolution operation however has a significant weakness in that it only operates on a local neighborhood, thus missing global information. Self-attention, on the other hand, has emerged as a recent advance to capture long range interactions, but has mostly been applied to sequence modeling and generative modeling tasks. In this paper, we consider the use of self-attention for discriminative visual tasks as an alternative to convolutions. We introduce a novel two-dimensional relative self-attention mechanism that proves competitive in replacing convolutions as a stand-alone computational primitive for image classification. We find in control experiments that the best results are obtained when combining both convolutions and self-attention. We therefore propose to augment convolutional operators with this self-attention mechanism by concatenating convolutional feature maps with a set of feature maps produced via self-attention. Extensive experiments show that Attention Augmentation leads to consistent improvements in image classification on ImageNet and object detection on COCO across many different models and scales, including ResNets and a state-of-the art mobile constrained network, while keeping the number of parameters similar. In particular, our method achieves a $1.3\%$ top-1 accuracy improvement on ImageNet classification over a ResNet50 baseline and outperforms other attention mechanisms for images such as Squeeze-and-Excitation. It also achieves an improvement of 1.4 mAP in COCO Object Detection on top of a RetinaNet baseline.
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
Apr 18, 2019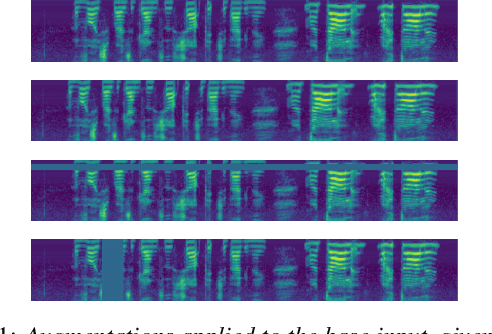
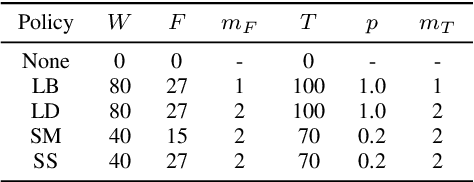
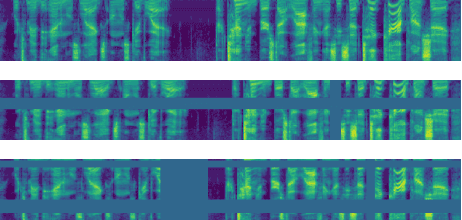
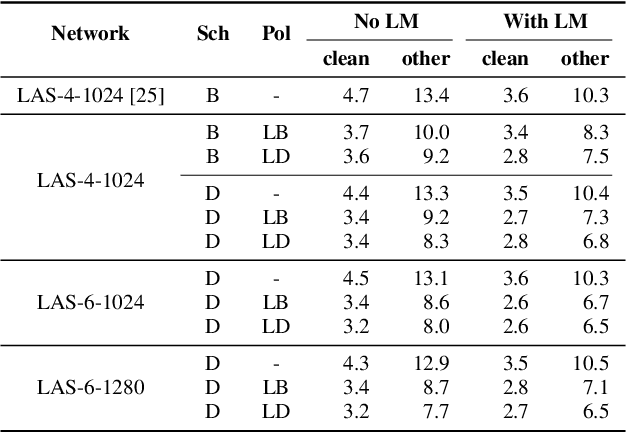
We present SpecAugment, a simple data augmentation method for speech recognition. SpecAugment is applied directly to the feature inputs of a neural network (i.e., filter bank coefficients). The augmentation policy consists of warping the features, masking blocks of frequency channels, and masking blocks of time steps. We apply SpecAugment on Listen, Attend and Spell networks for end-to-end speech recognition tasks. We achieve state-of-the-art performance on the LibriSpeech 960h and Swichboard 300h tasks, outperforming all prior work. On LibriSpeech, we achieve 6.8% WER on test-other without the use of a language model, and 5.8% WER with shallow fusion with a language model. This compares to the previous state-of-the-art hybrid system of 7.5% WER. For Switchboard, we achieve 7.2%/14.6% on the Switchboard/CallHome portion of the Hub5'00 test set without the use of a language model, and 6.8%/14.1% with shallow fusion, which compares to the previous state-of-the-art hybrid system at 8.3%/17.3% WER.
NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
Apr 16, 2019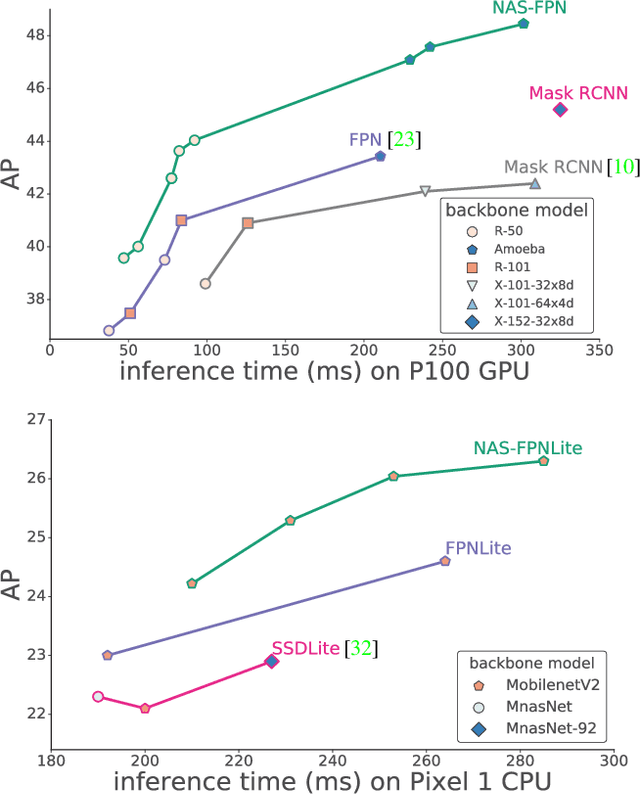
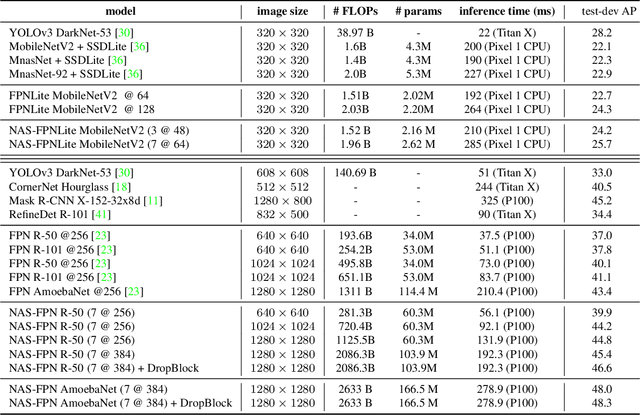
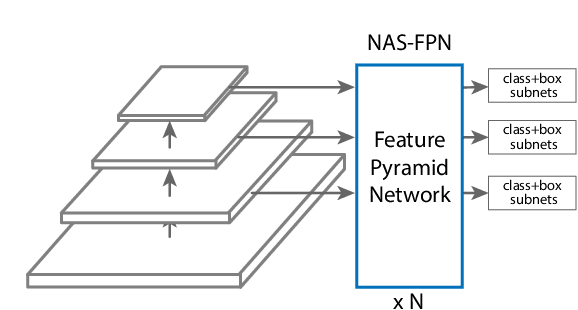
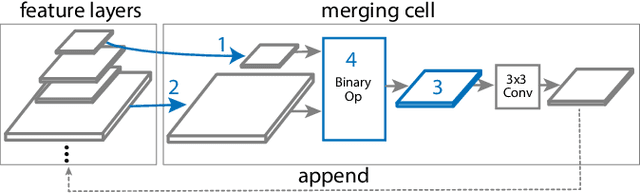
Current state-of-the-art convolutional architectures for object detection are manually designed. Here we aim to learn a better architecture of feature pyramid network for object detection. We adopt Neural Architecture Search and discover a new feature pyramid architecture in a novel scalable search space covering all cross-scale connections. The discovered architecture, named NAS-FPN, consists of a combination of top-down and bottom-up connections to fuse features across scales. NAS-FPN, combined with various backbone models in the RetinaNet framework, achieves better accuracy and latency tradeoff compared to state-of-the-art object detection models. NAS-FPN improves mobile detection accuracy by 2 AP compared to state-of-the-art SSDLite with MobileNetV2 model in [32] and achieves 48.3 AP which surpasses Mask R-CNN [10] detection accuracy with less computation time.
Soft Conditional Computation
Apr 10, 2019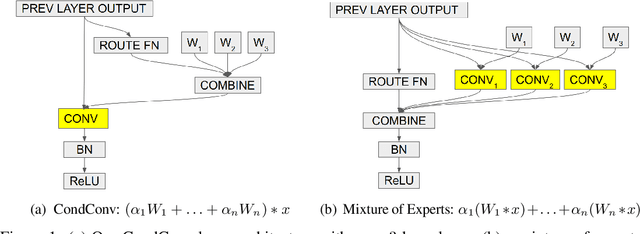
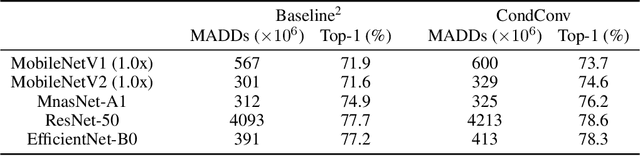
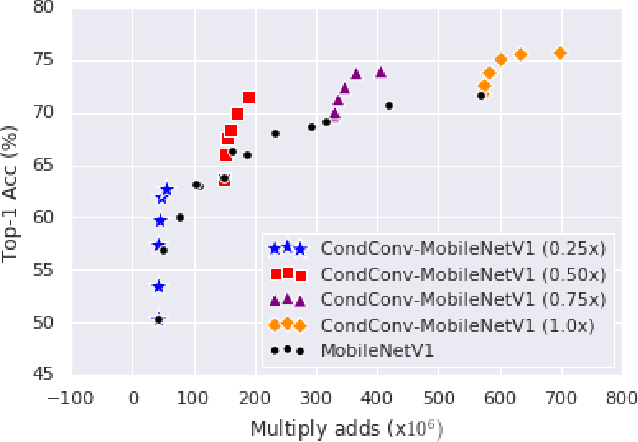

Conditional computation aims to increase the size and accuracy of a network, at a small increase in inference cost. Previous hard-routing models explicitly route the input to a subset of experts. We propose soft conditional computation, which, in contrast, utilizes all experts while still permitting efficient inference through parameter routing. Concretely, for a given convolutional layer, we wish to compute a linear combination of $n$ experts $\alpha_1 \cdot (W_1 * x) + \ldots + \alpha_n \cdot (W_n * x)$, where $\alpha_1, \ldots, \alpha_n$ are functions of the input learned through gradient descent. A straightforward evaluation requires $n$ convolutions. We propose an equivalent form of the above computation, $(\alpha_1 W_1 + \ldots + \alpha_n W_n) * x$, which requires only a single convolution. We demonstrate the efficacy of our method, named CondConv, by scaling up the MobileNetV1, MobileNetV2, and ResNet-50 model architectures to achieve higher accuracy while retaining efficient inference. On the ImageNet classification dataset, CondConv improves the top-1 validation accuracy of the MobileNetV1(0.5x) model from 63.8% to 71.6% while only increasing inference cost by 27%. On COCO object detection, CondConv improves the minival mAP of a MobileNetV1(1.0x) SSD model from 20.3 to 22.4 with just a 4% increase in inference cost.
The Evolved Transformer
Feb 15, 2019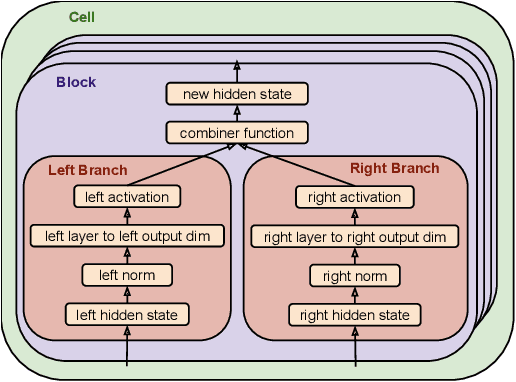
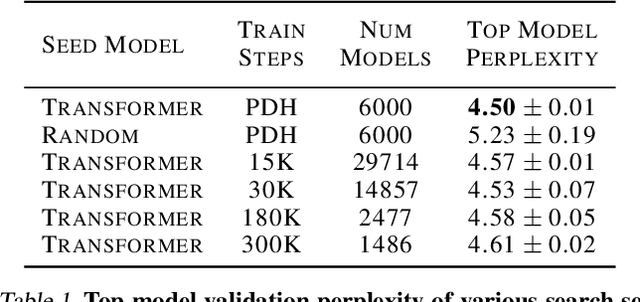
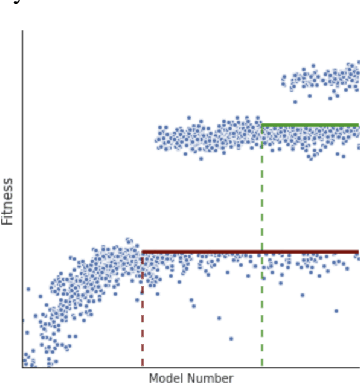
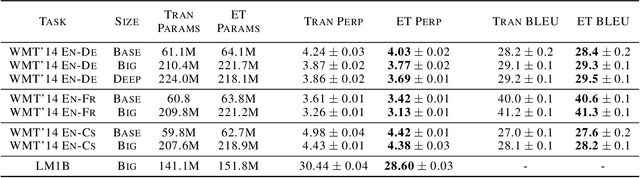
Recent works have highlighted the strengths of the Transformer architecture for dealing with sequence tasks. At the same time, neural architecture search has advanced to the point where it can outperform human-designed models. The goal of this work is to use architecture search to find a better Transformer architecture. We first construct a large search space inspired by the recent advances in feed-forward sequential models and then run evolutionary architecture search, seeding our initial population with the Transformer. To effectively run this search on the computationally expensive WMT 2014 English-German translation task, we develop the progressive dynamic hurdles method, which allows us to dynamically allocate more resources to more promising candidate models. The architecture found in our experiments - the Evolved Transformer - demonstrates consistent improvement over the Transformer on four well-established language tasks: WMT 2014 English-German, WMT 2014 English-French, WMT 2014 English-Czech and LM1B. At big model size, the Evolved Transformer is twice as efficient as the Transformer in FLOPS without loss in quality. At a much smaller - mobile-friendly - model size of ~7M parameters, the Evolved Transformer outperforms the Transformer by 0.7 BLEU on WMT'14 English-German.
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Jan 18, 2019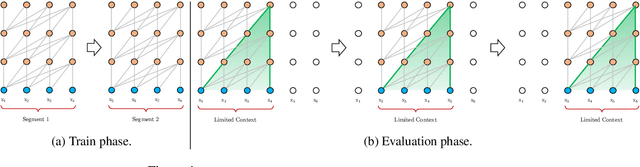
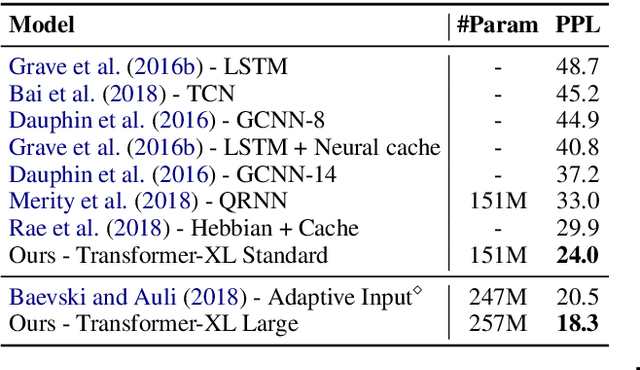
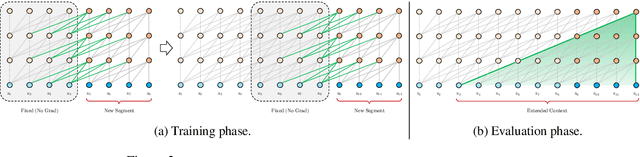
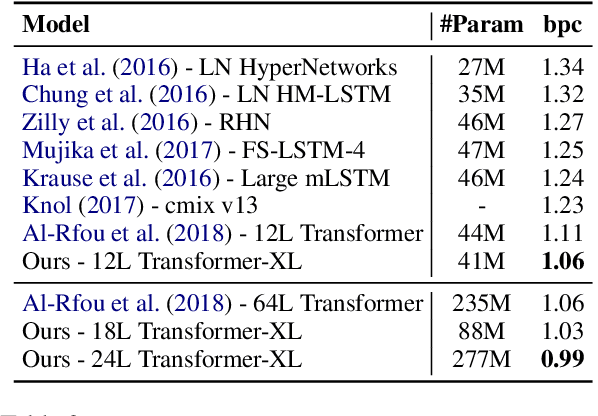
Transformer networks have a potential of learning longer-term dependency, but are limited by a fixed-length context in the setting of language modeling. As a solution, we propose a novel neural architecture, Transformer-XL, that enables Transformer to learn dependency beyond a fixed length without disrupting temporal coherence. Concretely, it consists of a segment-level recurrence mechanism and a novel positional encoding scheme. Our method not only enables capturing longer-term dependency, but also resolves the problem of context fragmentation. As a result, Transformer-XL learns dependency that is about 80% longer than RNNs and 450% longer than vanilla Transformers, achieves better performance on both short and long sequences, and is up to 1,800+ times faster than vanilla Transformer during evaluation. Additionally, we improve the state-of-the-art (SoTA) results of bpc/perplexity from 1.06 to 0.99 on enwiki8, from 1.13 to 1.08 on text8, from 20.5 to 18.3 on WikiText-103, from 23.7 to 21.8 on One Billion Word, and from 55.3 to 54.5 on Penn Treebank (without finetuning). Our code, pretrained models, and hyperparameters are available in both Tensorflow and PyTorch.
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Dec 12, 2018



GPipe is a scalable pipeline parallelism library that enables learning of giant deep neural networks. It partitions network layers across accelerators and pipelines execution to achieve high hardware utilization. It leverages recomputation to minimize activation memory usage. For example, using partitions over 8 accelerators, it is able to train networks that are 25x larger, demonstrating its scalability. It also guarantees that the computed gradients remain consistent regardless of the number of partitions. It achieves an almost linear speed up without any changes in the model parameters: when using 4x more accelerators, training the same model is up to 3.5x faster. We train a 557 million parameters AmoebaNet model on ImageNet and achieve a new state-of-the-art 84.3% top-1 / 97.0% top-5 accuracy on ImageNet 2012 dataset. Finally, we use this learned model to finetune multiple popular image classification datasets and obtain competitive results, including pushing the CIFAR-10 accuracy to 99% and CIFAR-100 accuracy to 91.3%.
Domain Adaptive Transfer Learning with Specialist Models
Dec 11, 2018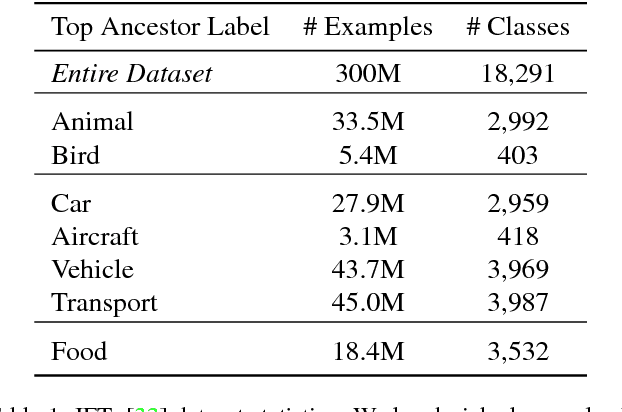
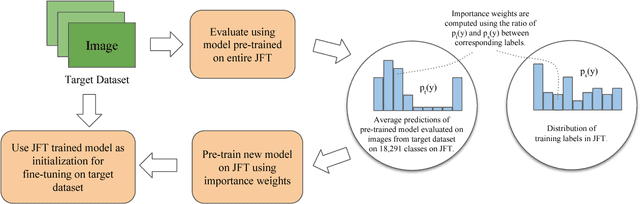
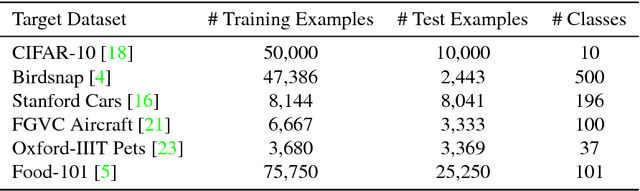
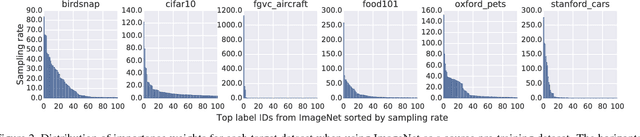
Transfer learning is a widely used method to build high performing computer vision models. In this paper, we study the efficacy of transfer learning by examining how the choice of data impacts performance. We find that more pre-training data does not always help, and transfer performance depends on a judicious choice of pre-training data. These findings are important given the continued increase in dataset sizes. We further propose domain adaptive transfer learning, a simple and effective pre-training method using importance weights computed based on the target dataset. Our method to compute importance weights follow from ideas in domain adaptation, and we show a novel application to transfer learning. Our methods achieve state-of-the-art results on multiple fine-grained classification datasets and are well-suited for use in practice.
DropBlock: A regularization method for convolutional networks
Oct 30, 2018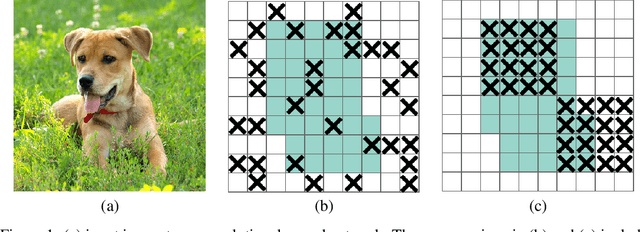
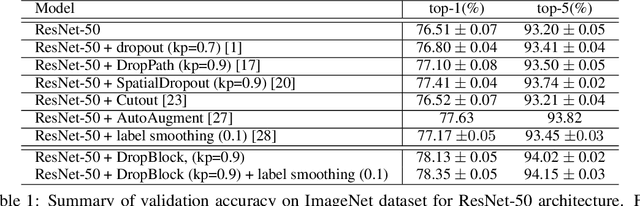
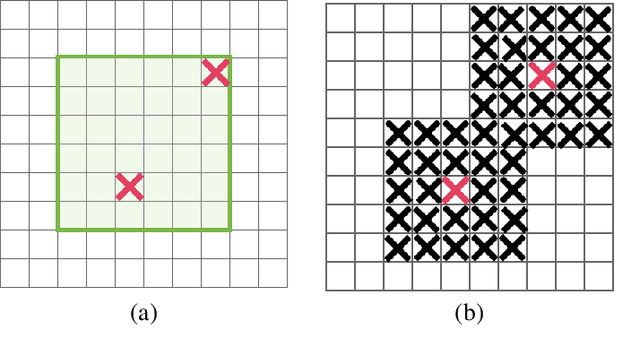

Deep neural networks often work well when they are over-parameterized and trained with a massive amount of noise and regularization, such as weight decay and dropout. Although dropout is widely used as a regularization technique for fully connected layers, it is often less effective for convolutional layers. This lack of success of dropout for convolutional layers is perhaps due to the fact that activation units in convolutional layers are spatially correlated so information can still flow through convolutional networks despite dropout. Thus a structured form of dropout is needed to regularize convolutional networks. In this paper, we introduce DropBlock, a form of structured dropout, where units in a contiguous region of a feature map are dropped together. We found that applying DropbBlock in skip connections in addition to the convolution layers increases the accuracy. Also, gradually increasing number of dropped units during training leads to better accuracy and more robust to hyperparameter choices. Extensive experiments show that DropBlock works better than dropout in regularizing convolutional networks. On ImageNet classification, ResNet-50 architecture with DropBlock achieves $78.13\%$ accuracy, which is more than $1.6\%$ improvement on the baseline. On COCO detection, DropBlock improves Average Precision of RetinaNet from $36.8\%$ to $38.4\%$.
Stochastic natural gradient descent draws posterior samples in function space
Oct 16, 2018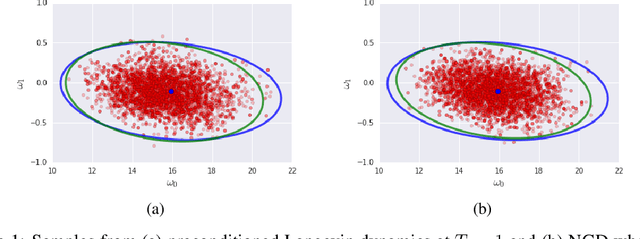
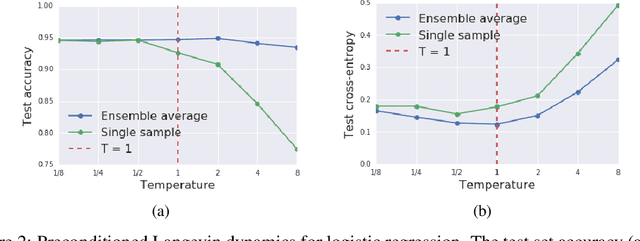
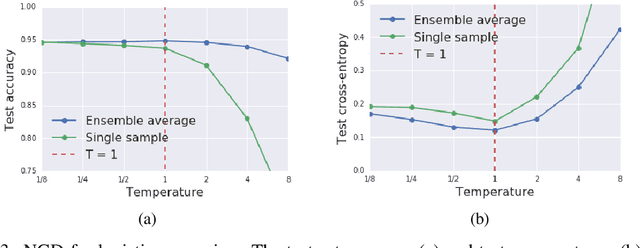
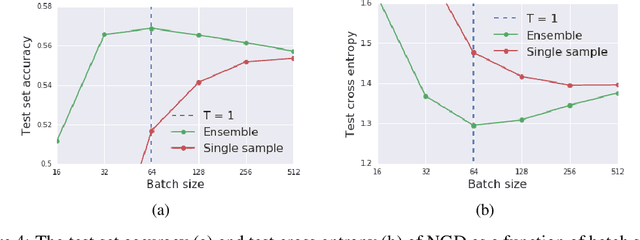
We prove that as the model predictions on the training set approach the true conditional distribution of labels given inputs, the noise inherent in minibatch gradients causes the stationary distribution of natural gradient descent to approach a Bayesian posterior near local minima as the learning rate $\epsilon \rightarrow 0$. The temperature $T \approx \epsilon N/(2B)$ of this posterior is controlled by the learning rate, training set size $N$ and batch size $B$. However minibatch NGD is not parameterisation invariant, and we therefore introduce "stochastic natural gradient descent", which preserves parameterisation invariance by introducing a multiplicative bias to the stationary distribution. We identify this bias as the well known Jeffreys prior. To support our claims, we show that the distribution of samples from NGD is close to the Laplace approximation to the posterior when $T = 1$. Furthermore, the test loss of ensembles drawn using NGD falls rapidly as we increase the batch size until $B \approx \epsilon N/2$, while above this point the test loss is constant or rises slowly.