 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoAugment: Learning Augmentation Policies from Data
Oct 09, 2018
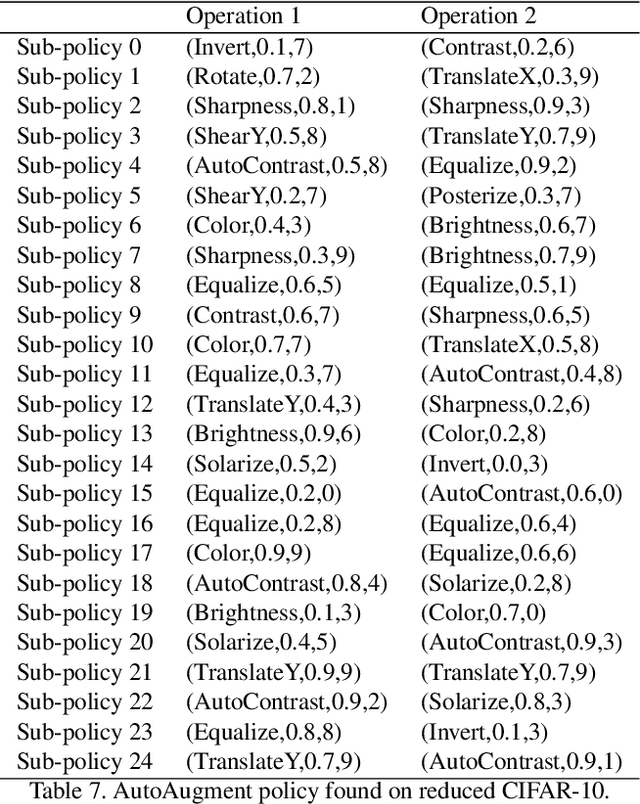


In this paper, we take a closer look at data augmentation for images, and describe a simple procedure called AutoAugment to search for improved data augmentation policies. Our key insight is to create a search space of data augmentation policies, evaluating the quality of a particular policy directly on the dataset of interest. In our implementation, we have designed a search space where a policy consists of many sub-policies, one of which is randomly chosen for each image in each mini-batch. A sub-policy consists of two operations, each operation being an image processing function such as translation, rotation, or shearing, and the probabilities and magnitudes with which the functions are applied. We use a search algorithm to find the best policy such that the neural network yields the highest validation accuracy on a target dataset. Our method achieves state-of-the-art accuracy on CIFAR-10, CIFAR-100, SVHN, and ImageNet (without additional data). On ImageNet, we attain a Top-1 accuracy of 83.54%. On CIFAR-10, we achieve an error rate of 1.48%, which is 0.65% better than the previous state-of-the-art. Finally, policies learned from one dataset can be transferred to work well on other similar datasets. For example, the policy learned on ImageNet allows us to achieve state-of-the-art accuracy on the fine grained visual classification dataset Stanford Cars, without fine-tuning weights pre-trained on additional data. Code to train Wide-ResNet, Shake-Shake and ShakeDrop models with AutoAugment policies can be found at https://github.com/tensorflow/models/tree/master/research/autoaugment
Semi-Supervised Sequence Modeling with Cross-View Training
Sep 22, 2018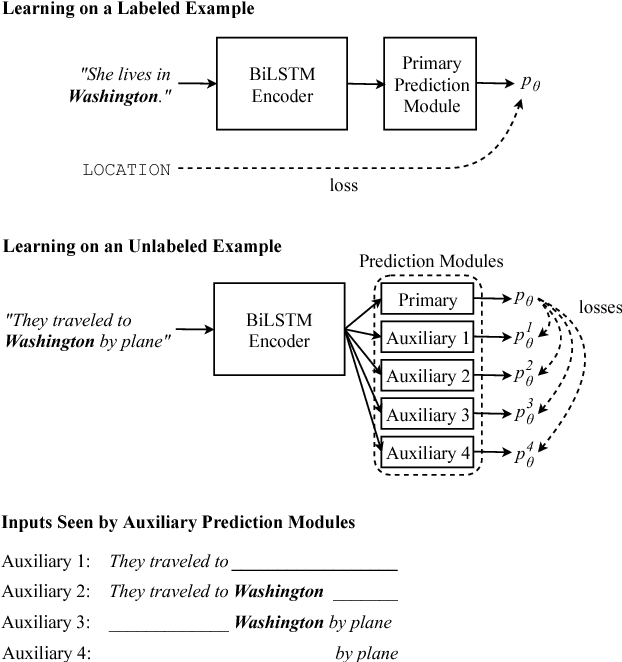
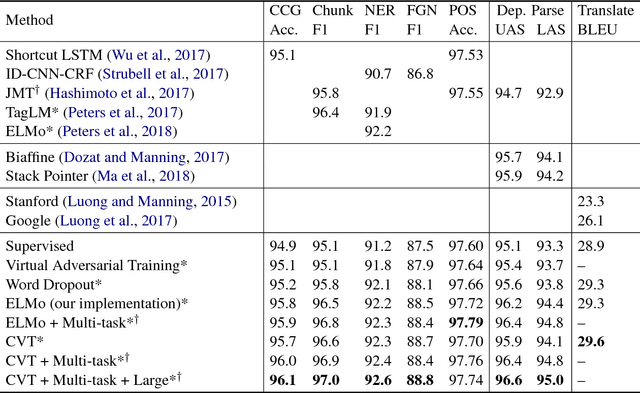
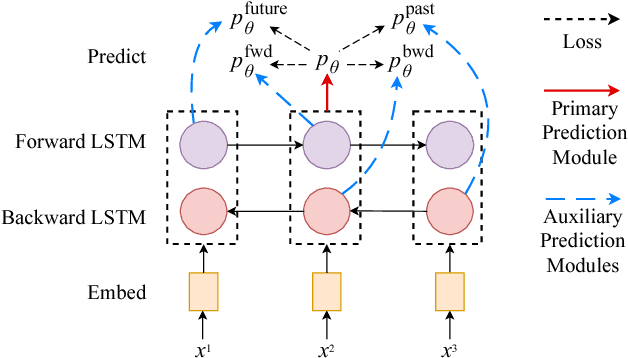
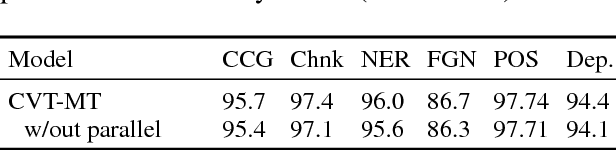
Unsupervised representation learning algorithms such as word2vec and ELMo improve the accuracy of many supervised NLP models, mainly because they can take advantage of large amounts of unlabeled text. However, the supervised models only learn from task-specific labeled data during the main training phase. We therefore propose Cross-View Training (CVT), a semi-supervised learning algorithm that improves the representations of a Bi-LSTM sentence encoder using a mix of labeled and unlabeled data. On labeled examples, standard supervised learning is used. On unlabeled examples, CVT teaches auxiliary prediction modules that see restricted views of the input (e.g., only part of a sentence) to match the predictions of the full model seeing the whole input. Since the auxiliary modules and the full model share intermediate representations, this in turn improves the full model. Moreover, we show that CVT is particularly effective when combined with multi-task learning. We evaluate CVT on five sequence tagging tasks, machine translation, and dependency parsing, achieving state-of-the-art results.
MnasNet: Platform-Aware Neural Architecture Search for Mobile
Jul 31, 2018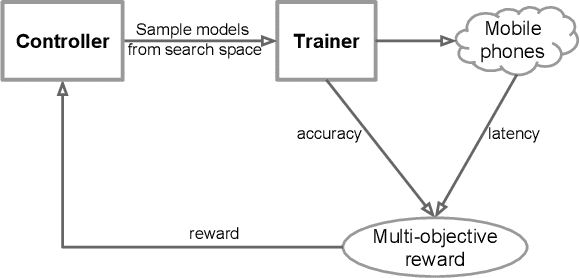
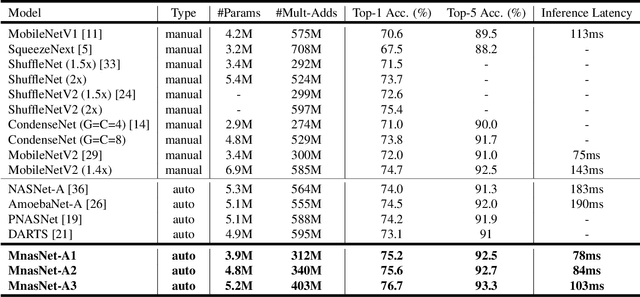
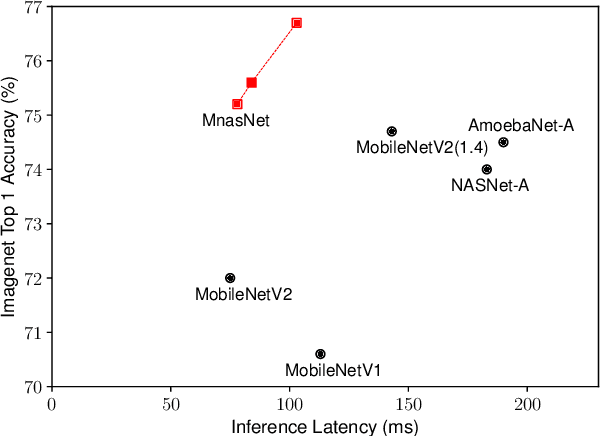
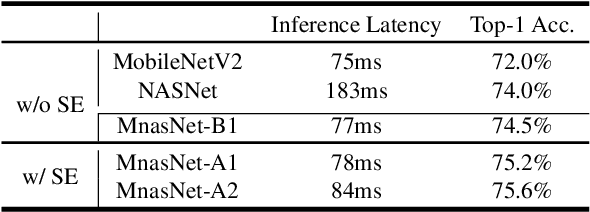
Designing convolutional neural networks (CNN) models for mobile devices is challenging because mobile models need to be small and fast, yet still accurate. Although significant effort has been dedicated to design and improve mobile models on all three dimensions, it is challenging to manually balance these trade-offs when there are so many architectural possibilities to consider. In this paper, we propose an automated neural architecture search approach for designing resource-constrained mobile CNN models. We propose to explicitly incorporate latency information into the main objective so that the search can identify a model that achieves a good trade-off between accuracy and latency. Unlike in previous work, where mobile latency is considered via another, often inaccurate proxy (e.g., FLOPS), in our experiments, we directly measure real-world inference latency by executing the model on a particular platform, e.g., Pixel phones. To further strike the right balance between flexibility and search space size, we propose a novel factorized hierarchical search space that permits layer diversity throughout the network. Experimental results show that our approach consistently outperforms state-of-the-art mobile CNN models across multiple vision tasks. On the ImageNet classification task, our model achieves 74.0% top-1 accuracy with 76ms latency on a Pixel phone, which is 1.5x faster than MobileNetV2 (Sandler et al. 2018) and 2.4x faster than NASNet (Zoph et al. 2018) with the same top-1 accuracy. On the COCO object detection task, our model family achieves both higher mAP quality and lower latency than MobileNets.
Can Deep Reinforcement Learning Solve Erdos-Selfridge-Spencer Games?
Jun 29, 2018
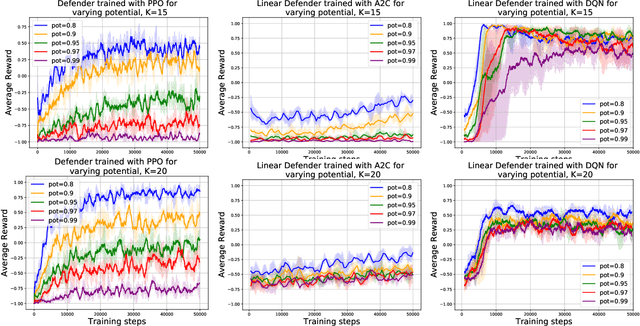
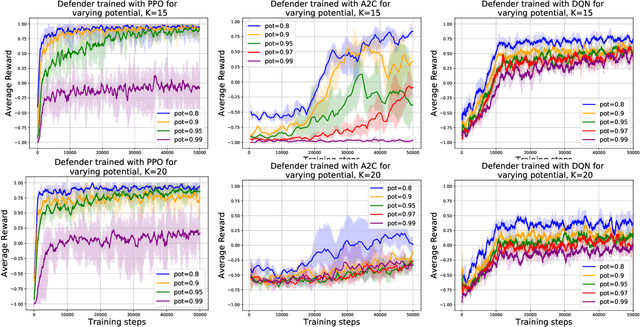
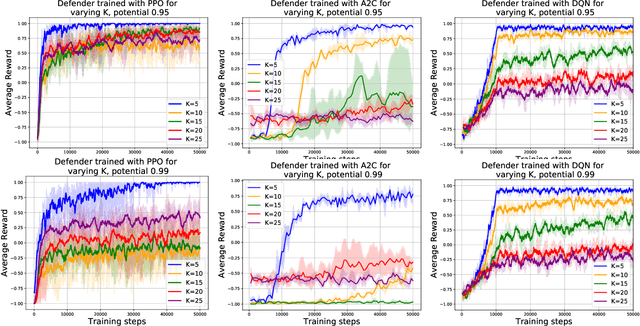
Deep reinforcement learning has achieved many recent successes, but our understanding of its strengths and limitations is hampered by the lack of rich environments in which we can fully characterize optimal behavior, and correspondingly diagnose individual actions against such a characterization. Here we consider a family of combinatorial games, arising from work of Erdos, Selfridge, and Spencer, and we propose their use as environments for evaluating and comparing different approaches to reinforcement learning. These games have a number of appealing features: they are challenging for current learning approaches, but they form (i) a low-dimensional, simply parametrized environment where (ii) there is a linear closed form solution for optimal behavior from any state, and (iii) the difficulty of the game can be tuned by changing environment parameters in an interpretable way. We use these Erdos-Selfridge-Spencer games not only to compare different algorithms, but test for generalization, make comparisons to supervised learning, analyse multiagent play, and even develop a self play algorithm. Code can be found at: https://github.com/rubai5/ESS_Game
Learning Longer-term Dependencies in RNNs with Auxiliary Losses
Jun 13, 2018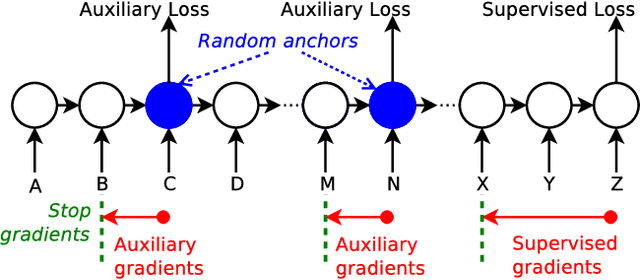
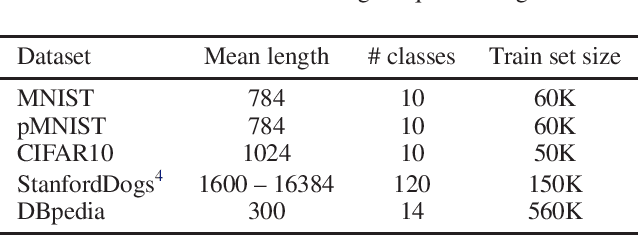
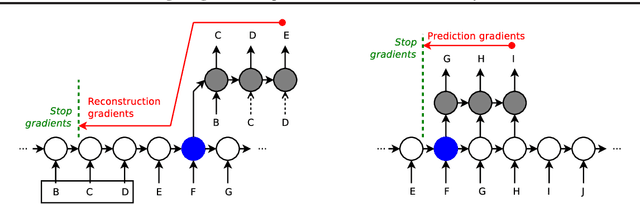
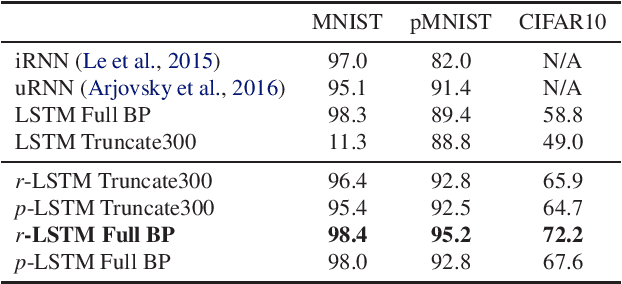
Despite recent advances in training recurrent neural networks (RNNs), capturing long-term dependencies in sequences remains a fundamental challenge. Most approaches use backpropagation through time (BPTT), which is difficult to scale to very long sequences. This paper proposes a simple method that improves the ability to capture long term dependencies in RNNs by adding an unsupervised auxiliary loss to the original objective. This auxiliary loss forces RNNs to either reconstruct previous events or predict next events in a sequence, making truncated backpropagation feasible for long sequences and also improving full BPTT. We evaluate our method on a variety of settings, including pixel-by-pixel image classification with sequence lengths up to 16\,000, and a real document classification benchmark. Our results highlight good performance and resource efficiency of this approach over competitive baselines, including other recurrent models and a comparable sized Transformer. Further analyses reveal beneficial effects of the auxiliary loss on optimization and regularization, as well as extreme cases where there is little to no backpropagation.
A Simple Method for Commonsense Reasoning
Jun 07, 2018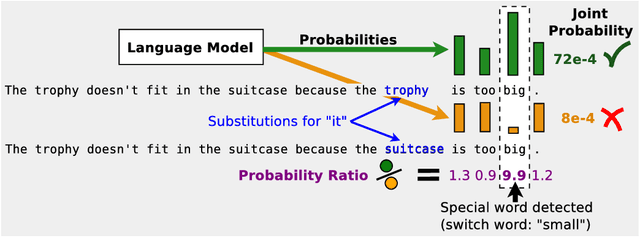



Commonsense reasoning is a long-standing challenge for deep learning. For example, it is difficult to use neural networks to tackle the Winograd Schema dataset~\cite{levesque2011winograd}. In this paper, we present a simple method for commonsense reasoning with neural networks, using unsupervised learning. Key to our method is the use of language models, trained on a massive amount of unlabled data, to score multiple choice questions posed by commonsense reasoning tests. On both Pronoun Disambiguation and Winograd Schema challenges, our models outperform previous state-of-the-art methods by a large margin, without using expensive annotated knowledge bases or hand-engineered features. We train an array of large RNN language models that operate at word or character level on LM-1-Billion, CommonCrawl, SQuAD, Gutenberg Books, and a customized corpus for this task and show that diversity of training data plays an important role in test performance. Further analysis also shows that our system successfully discovers important features of the context that decide the correct answer, indicating a good grasp of commonsense knowledge.
Do Better ImageNet Models Transfer Better?
May 23, 2018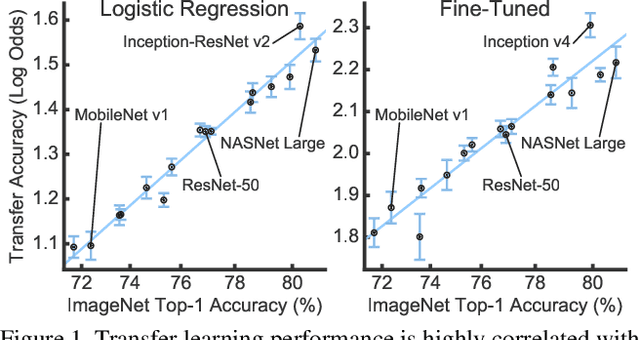
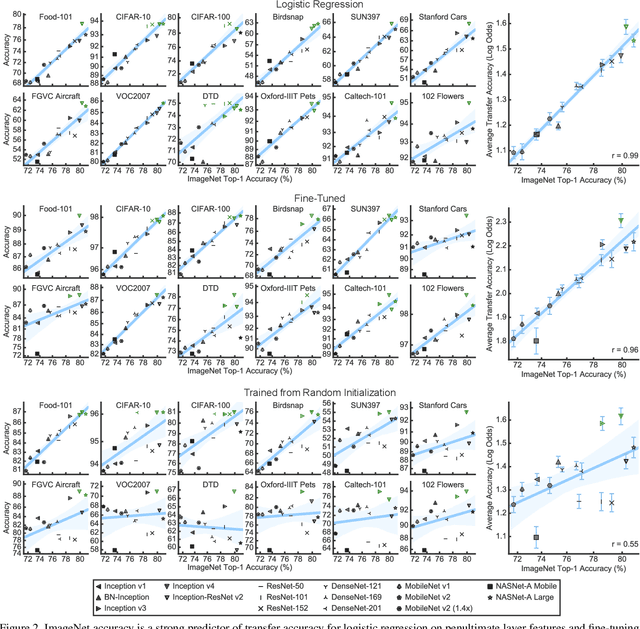
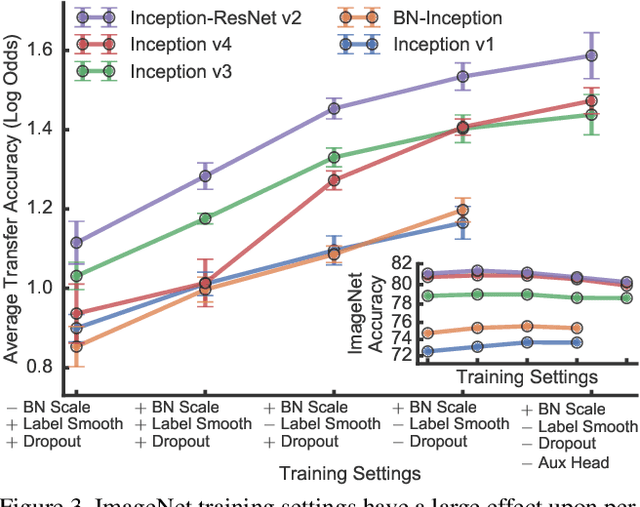
Transfer learning has become a cornerstone of computer vision with the advent of ImageNet features, yet little work has been done to evaluate the performance of ImageNet architectures across different datasets. An implicit hypothesis in modern computer vision research is that models that perform better on ImageNet necessarily perform better on other vision tasks. However, this hypothesis has never been systematically tested. Here, we compare the performance of 13 classification models on 12 image classification tasks in three settings: as fixed feature extractors, fine-tuned, and trained from random initialization. We find that, when networks are used as fixed feature extractors, ImageNet accuracy is only weakly predictive of accuracy on other tasks ($r^2=0.24$). In this setting, ResNets consistently outperform networks that achieve higher accuracy on ImageNet. When networks are fine-tuned, we observe a substantially stronger correlation ($r^2 = 0.86$). We achieve state-of-the-art performance on eight image classification tasks simply by fine-tuning state-of-the-art ImageNet architectures, outperforming previous results based on specialized methods for transfer learning. Finally, we observe that, on three small fine-grained image classification datasets, networks trained from random initialization perform similarly to ImageNet-pretrained networks. Together, our results show that ImageNet architectures generalize well across datasets, with small improvements in ImageNet accuracy producing improvements across other tasks, but ImageNet features are less general than previously suggested.
QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension
Apr 23, 2018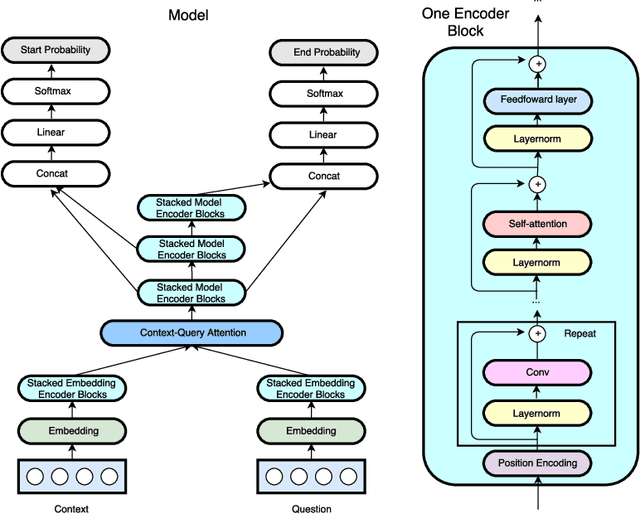

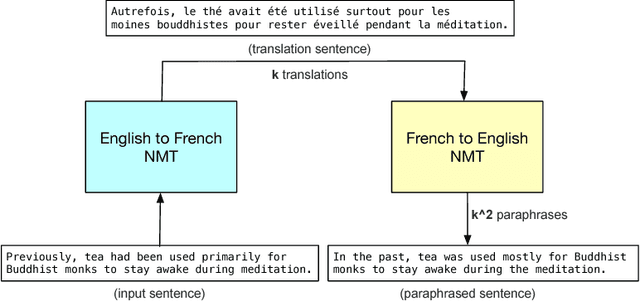
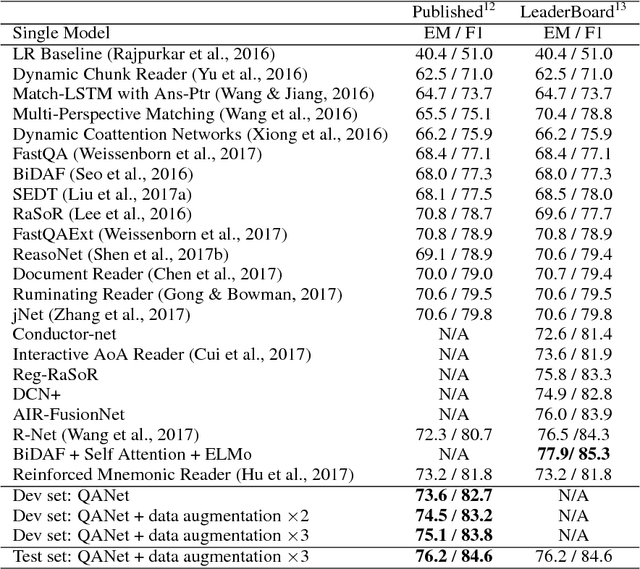
Current end-to-end machine reading and question answering (Q\&A) models are primarily based on recurrent neural networks (RNNs) with attention. Despite their success, these models are often slow for both training and inference due to the sequential nature of RNNs. We propose a new Q\&A architecture called QANet, which does not require recurrent networks: Its encoder consists exclusively of convolution and self-attention, where convolution models local interactions and self-attention models global interactions. On the SQuAD dataset, our model is 3x to 13x faster in training and 4x to 9x faster in inference, while achieving equivalent accuracy to recurrent models. The speed-up gain allows us to train the model with much more data. We hence combine our model with data generated by backtranslation from a neural machine translation model. On the SQuAD dataset, our single model, trained with augmented data, achieves 84.6 F1 score on the test set, which is significantly better than the best published F1 score of 81.8.
Learning Transferable Architectures for Scalable Image Recognition
Apr 11, 2018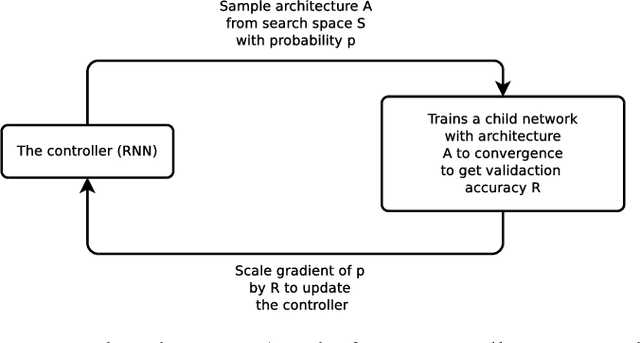
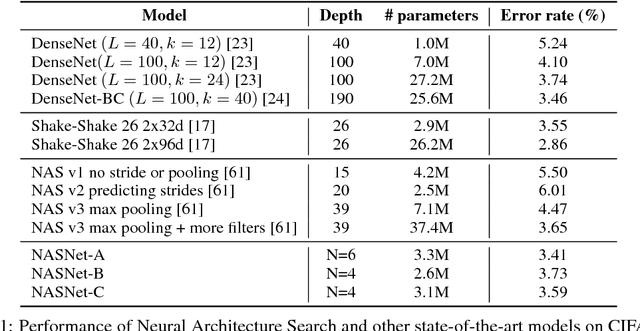
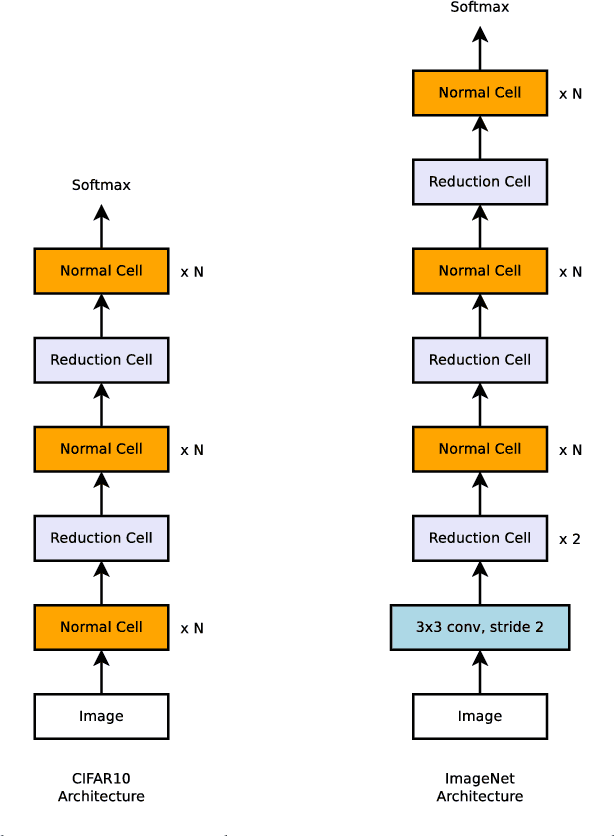
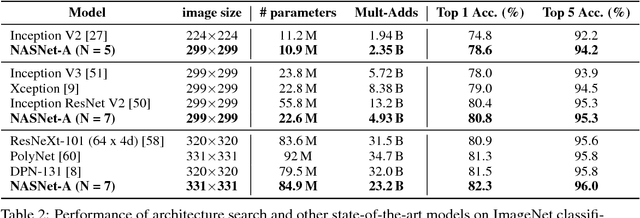
Developing neural network image classification models often requires significant architecture engineering. In this paper, we study a method to learn the model architectures directly on the dataset of interest. As this approach is expensive when the dataset is large, we propose to search for an architectural building block on a small dataset and then transfer the block to a larger dataset. The key contribution of this work is the design of a new search space (the "NASNet search space") which enables transferability. In our experiments, we search for the best convolutional layer (or "cell") on the CIFAR-10 dataset and then apply this cell to the ImageNet dataset by stacking together more copies of this cell, each with their own parameters to design a convolutional architecture, named "NASNet architecture". We also introduce a new regularization technique called ScheduledDropPath that significantly improves generalization in the NASNet models. On CIFAR-10 itself, NASNet achieves 2.4% error rate, which is state-of-the-art. On ImageNet, NASNet achieves, among the published works, state-of-the-art accuracy of 82.7% top-1 and 96.2% top-5 on ImageNet. Our model is 1.2% better in top-1 accuracy than the best human-invented architectures while having 9 billion fewer FLOPS - a reduction of 28% in computational demand from the previous state-of-the-art model. When evaluated at different levels of computational cost, accuracies of NASNets exceed those of the state-of-the-art human-designed models. For instance, a small version of NASNet also achieves 74% top-1 accuracy, which is 3.1% better than equivalently-sized, state-of-the-art models for mobile platforms. Finally, the learned features by NASNet used with the Faster-RCNN framework surpass state-of-the-art by 4.0% achieving 43.1% mAP on the COCO dataset.
Neural Program Synthesis with Priority Queue Training
Mar 23, 2018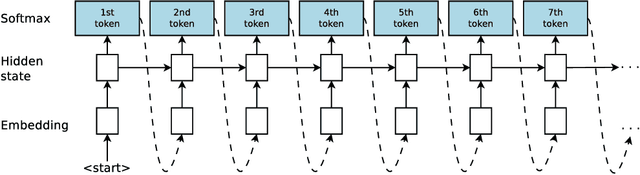


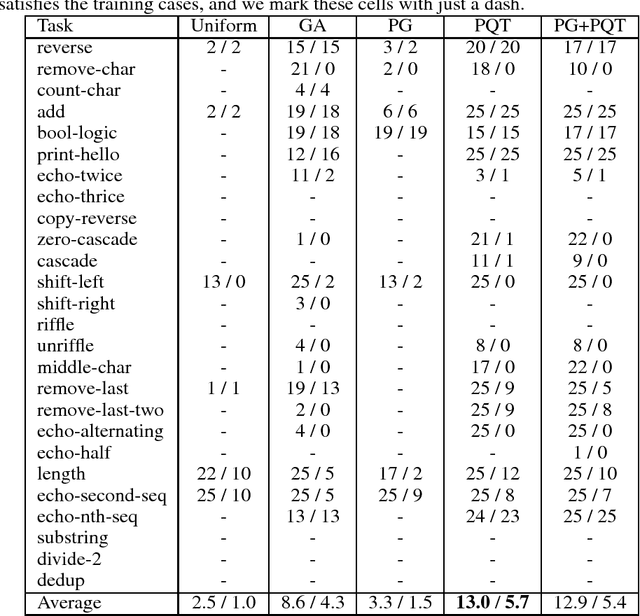
We consider the task of program synthesis in the presence of a reward function over the output of programs, where the goal is to find programs with maximal rewards. We employ an iterative optimization scheme, where we train an RNN on a dataset of K best programs from a priority queue of the generated programs so far. Then, we synthesize new programs and add them to the priority queue by sampling from the RNN. We benchmark our algorithm, called priority queue training (or PQT), against genetic algorithm and reinforcement learning baselines on a simple but expressive Turing complete programming language called BF. Our experimental results show that our simple PQT algorithm significantly outperforms the baselines. By adding a program length penalty to the reward function, we are able to synthesize short, human readable programs.