 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-Level Explanation for the Generalization of a DNN
Feb 25, 2023



This paper explains the generalization power of a deep neural network (DNN) from the perspective of interactive concepts. Many recent studies have quantified a clear emergence of interactive concepts encoded by the DNN, which have been observed on different DNNs during the learning process. Therefore, in this paper, we investigate the generalization power of each interactive concept, and we use the generalization power of different interactive concepts to explain the generalization power of the entire DNN. Specifically, we define the complexity of each interactive concept. We find that simple concepts can be better generalized to testing data than complex concepts. The DNN with strong generalization power usually learns simple concepts more quickly and encodes fewer complex concepts. More crucially, we discover the detouring dynamics of learning complex concepts, which explain both the high learning difficulty and the low generalization power of complex concepts.
Bayesian Neural Networks Tend to Ignore Complex and Sensitive Concepts
Feb 25, 2023



In this paper, we focus on mean-field variational Bayesian Neural Networks (BNNs) and explore the representation capacity of such BNNs by investigating which types of concepts are less likely to be encoded by the BNN. It has been observed and studied that a relatively small set of interactive concepts usually emerge in the knowledge representation of a sufficiently-trained neural network, and such concepts can faithfully explain the network output. Based on this, our study proves that compared to standard deep neural networks (DNNs), it is less likely for BNNs to encode complex concepts. Experiments verify our theoretical proofs. Note that the tendency to encode less complex concepts does not necessarily imply weak representation power, considering that complex concepts exhibit low generalization power and high adversarial vulnerability.
Does a Neural Network Really Encode Symbolic Concept?
Feb 25, 2023Recently, a series of studies have tried to extract interactions between input variables modeled by a DNN and define such interactions as concepts encoded by the DNN. However, strictly speaking, there still lacks a solid guarantee whether such interactions indeed represent meaningful concepts. Therefore, in this paper, we examine the trustworthiness of interaction concepts from four perspectives. Extensive empirical studies have verified that a well-trained DNN usually encodes sparse, transferable, and discriminative concepts, which is partially aligned with human intuition.
Defects of Convolutional Decoder Networks in Frequency Representation
Oct 17, 2022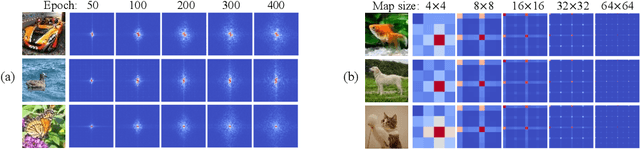
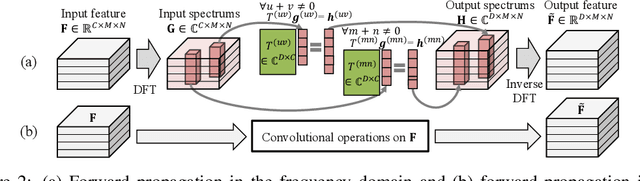


In this paper, we prove representation bottlenecks of a cascaded convolutional decoder network, considering the capacity of representing different frequency components of an input sample. We conduct the discrete Fourier transform on each channel of the feature map in an intermediate layer of the decoder network. Then, we introduce the rule of the forward propagation of such intermediate-layer spectrum maps, which is equivalent to the forward propagation of feature maps through a convolutional layer. Based on this, we find that each frequency component in the spectrum map is forward propagated independently with other frequency components. Furthermore, we prove two bottlenecks in representing feature spectrums. First, we prove that the convolution operation, the zero-padding operation, and a set of other settings all make a convolutional decoder network more likely to weaken high-frequency components. Second, we prove that the upsampling operation generates a feature spectrum, in which strong signals repetitively appears at certain frequencies.
Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification
Aug 18, 2022
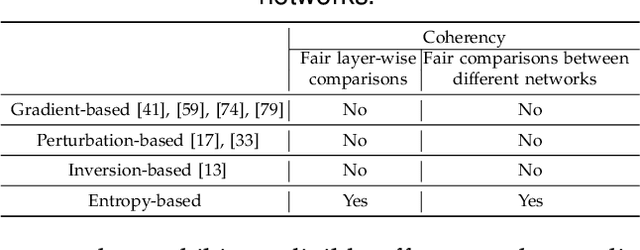
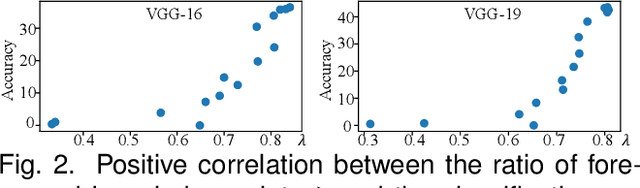
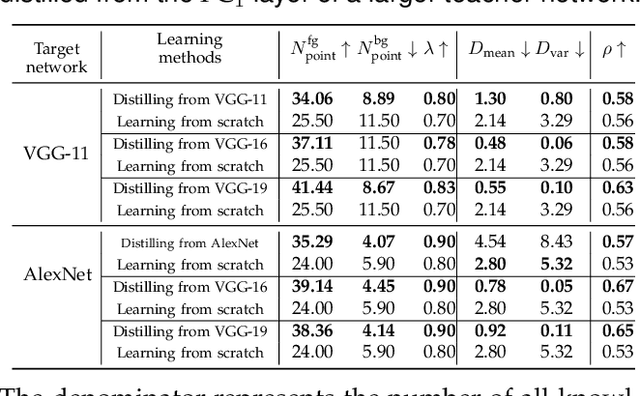
Compared to traditional learning from scratch, knowledge distillation sometimes makes the DNN achieve superior performance. This paper provides a new perspective to explain the success of knowledge distillation, i.e., quantifying knowledge points encoded in intermediate layers of a DNN for classification, based on the information theory. To this end, we consider the signal processing in a DNN as the layer-wise information discarding. A knowledge point is referred to as an input unit, whose information is much less discarded than other input units. Thus, we propose three hypotheses for knowledge distillation based on the quantification of knowledge points. 1. The DNN learning from knowledge distillation encodes more knowledge points than the DNN learning from scratch. 2. Knowledge distillation makes the DNN more likely to learn different knowledge points simultaneously. In comparison, the DNN learning from scratch tends to encode various knowledge points sequentially. 3. The DNN learning from knowledge distillation is often optimized more stably than the DNN learning from scratch. In order to verify the above hypotheses, we design three types of metrics with annotations of foreground objects to analyze feature representations of the DNN, \textit{i.e.} the quantity and the quality of knowledge points, the learning speed of different knowledge points, and the stability of optimization directions. In experiments, we diagnosed various DNNs for different classification tasks, i.e., image classification, 3D point cloud classification, binary sentiment classification, and question answering, which verified above hypotheses.
Proving Common Mechanisms Shared by Twelve Methods of Boosting Adversarial Transferability
Jul 24, 2022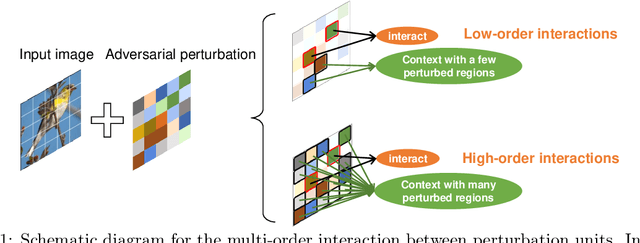
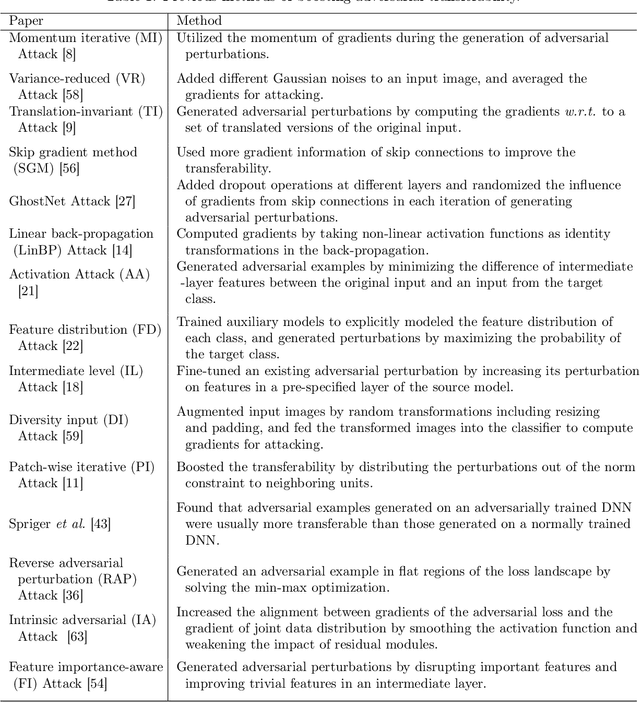
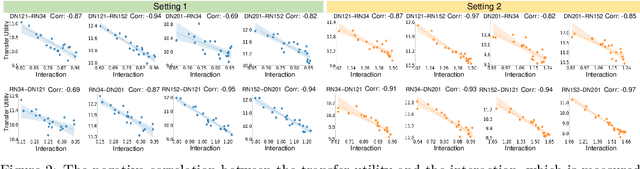
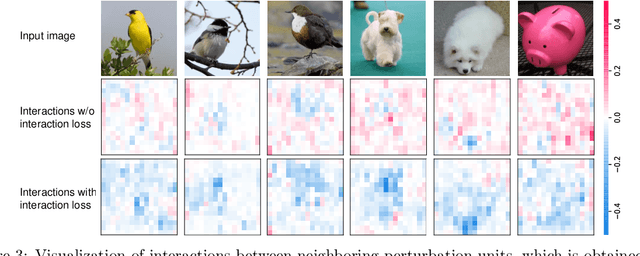
Although many methods have been proposed to enhance the transferability of adversarial perturbations, these methods are designed in a heuristic manner, and the essential mechanism for improving adversarial transferability is still unclear. This paper summarizes the common mechanism shared by twelve previous transferability-boosting methods in a unified view, i.e., these methods all reduce game-theoretic interactions between regional adversarial perturbations. To this end, we focus on the attacking utility of all interactions between regional adversarial perturbations, and we first discover and prove the negative correlation between the adversarial transferability and the attacking utility of interactions. Based on this discovery, we theoretically prove and empirically verify that twelve previous transferability-boosting methods all reduce interactions between regional adversarial perturbations. More crucially, we consider the reduction of interactions as the essential reason for the enhancement of adversarial transferability. Furthermore, we design the interaction loss to directly penalize interactions between regional adversarial perturbations during attacking. Experimental results show that the interaction loss significantly improves the transferability of adversarial perturbations.
Batch Normalization Is Blind to the First and Second Derivatives of the Loss
Jun 02, 2022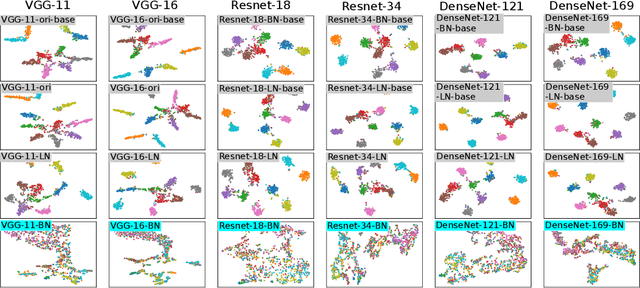
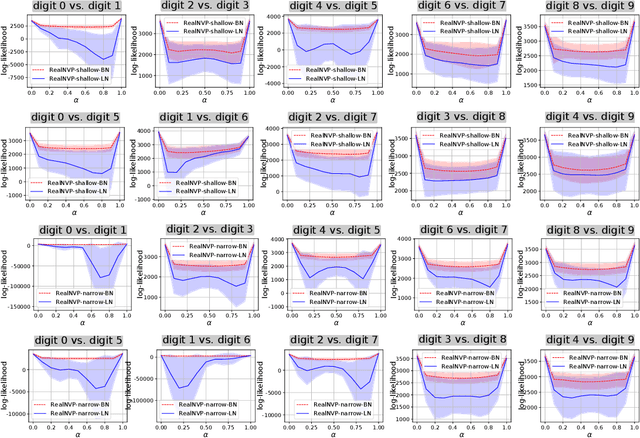
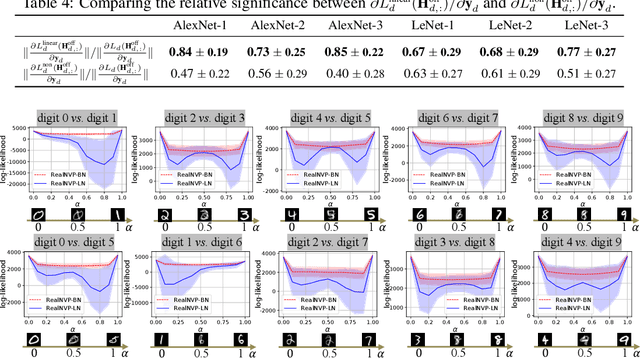

In this paper, we prove the effects of the BN operation on the back-propagation of the first and second derivatives of the loss. When we do the Taylor series expansion of the loss function, we prove that the BN operation will block the influence of the first-order term and most influence of the second-order term of the loss. We also find that such a problem is caused by the standardization phase of the BN operation. Experimental results have verified our theoretical conclusions, and we have found that the BN operation significantly affects feature representations in specific tasks, where losses of different samples share similar analytic formulas.
Why Adversarial Training of ReLU Networks Is Difficult?
May 30, 2022
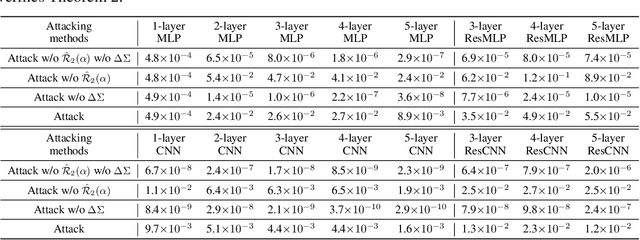
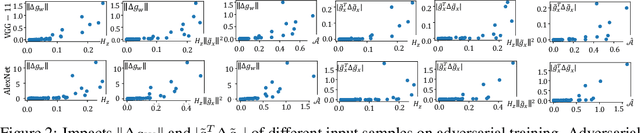

This paper mathematically derives an analytic solution of the adversarial perturbation on a ReLU network, and theoretically explains the difficulty of adversarial training. Specifically, we formulate the dynamics of the adversarial perturbation generated by the multi-step attack, which shows that the adversarial perturbation tends to strengthen eigenvectors corresponding to a few top-ranked eigenvalues of the Hessian matrix of the loss w.r.t. the input. We also prove that adversarial training tends to strengthen the influence of unconfident input samples with large gradient norms in an exponential manner. Besides, we find that adversarial training strengthens the influence of the Hessian matrix of the loss w.r.t. network parameters, which makes the adversarial training more likely to oscillate along directions of a few samples, and boosts the difficulty of adversarial training. Crucially, our proofs provide a unified explanation for previous findings in understanding adversarial training.
RASAT: Integrating Relational Structures into Pretrained Seq2Seq Model for Text-to-SQL
May 14, 2022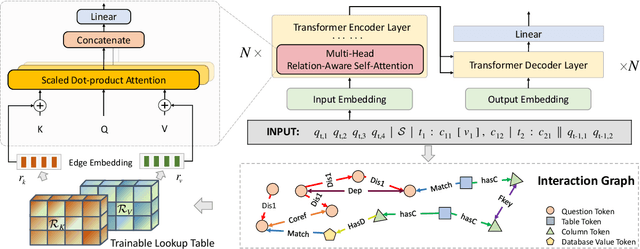
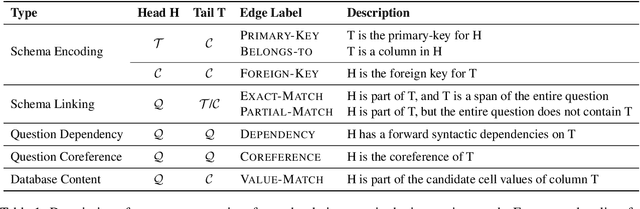
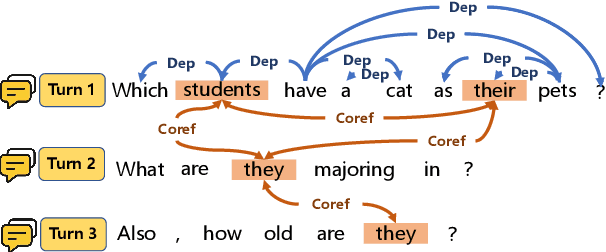
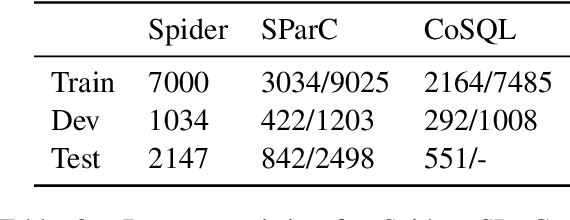
Relational structures such as schema linking and schema encoding have been validated as a key component to qualitatively translating natural language into SQL queries. However, introducing these structural relations comes with prices: they often result in a specialized model structure, which largely prohibits the use of large pretrained models in text-to-SQL. To address this problem, we propose RASAT: a Transformer seq2seq architecture augmented with relation-aware self-attention that could leverage a variety of relational structures while at the meantime being able to effectively inherit the pretrained parameters from the T5 model. Our model is able to incorporate almost all types of existing relations in the literature, and in addition, we propose to introduce co-reference relations for the multi-turn scenario. Experimental results on three widely used text-to-SQL datasets, covering both single-turn and multi-turn scenarios, have shown that RASAT could achieve competitive results in all three benchmarks, achieving state-of-the-art performance in execution accuracy (80.5\% EX on Spider, 53.1\% IEX on SParC, and 37.5\% IEX on CoSQL).
Towards Theoretical Analysis of Transformation Complexity of ReLU DNNs
May 04, 2022
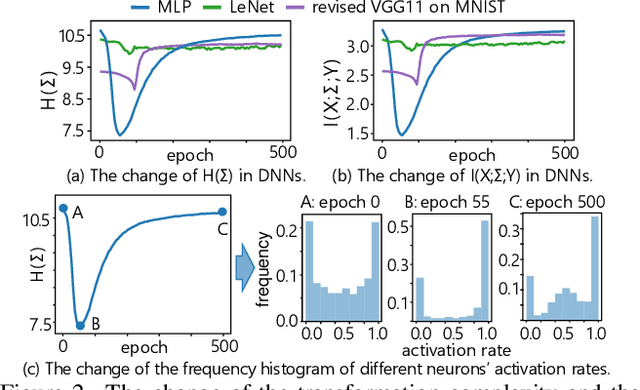
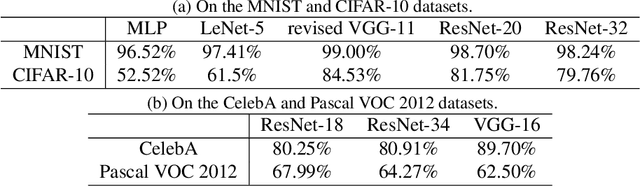
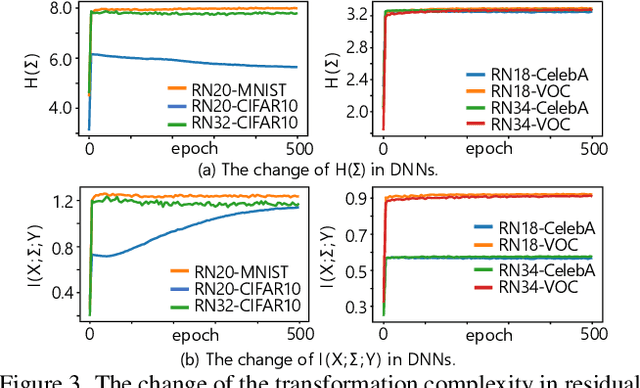
This paper aims to theoretically analyze the complexity of feature transformations encoded in DNNs with ReLU layers. We propose metrics to measure three types of complexities of transformations based on the information theory. We further discover and prove the strong correlation between the complexity and the disentanglement of transformations. Based on the proposed metrics, we analyze two typical phenomena of the change of the transformation complexity during the training process, and explore the ceiling of a DNN's complexity. The proposed metrics can also be used as a loss to learn a DNN with the minimum complexity, which also controls the over-fitting level of the DNN and influences adversarial robustness, adversarial transferability, and knowledge consistency. Comprehensive comparative studies have provided new perspectives to understand the DNN.