 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorda Regret Minimization for Generalized Linear Dueling Bandits
Mar 15, 2023Dueling bandits are widely used to model preferential feedback that is prevalent in machine learning applications such as recommendation systems and ranking. In this paper, we study the Borda regret minimization problem for dueling bandits, which aims to identify the item with the highest Borda score while minimizing the cumulative regret. We propose a new and highly expressive generalized linear dueling bandits model, which covers many existing models. Surprisingly, the Borda regret minimization problem turns out to be difficult, as we prove a regret lower bound of order $\Omega(d^{2/3} T^{2/3})$, where $d$ is the dimension of contextual vectors and $T$ is the time horizon. To attain the lower bound, we propose an explore-then-commit type algorithm, which has a nearly matching regret upper bound $\tilde{O}(d^{2/3} T^{2/3})$. When the number of items/arms $K$ is small, our algorithm can achieve a smaller regret $\tilde{O}( (d \log K)^{1/3} T^{2/3})$ with proper choices of hyperparameters. We also conduct empirical experiments on both synthetic data and a simulated real-world environment, which corroborate our theoretical analysis.
The Benefits of Mixup for Feature Learning
Mar 15, 2023Mixup, a simple data augmentation method that randomly mixes two data points via linear interpolation, has been extensively applied in various deep learning applications to gain better generalization. However, the theoretical underpinnings of its efficacy are not yet fully understood. In this paper, we aim to seek a fundamental understanding of the benefits of Mixup. We first show that Mixup using different linear interpolation parameters for features and labels can still achieve similar performance to the standard Mixup. This indicates that the intuitive linearity explanation in Zhang et al., (2018) may not fully explain the success of Mixup. Then we perform a theoretical study of Mixup from the feature learning perspective. We consider a feature-noise data model and show that Mixup training can effectively learn the rare features (appearing in a small fraction of data) from its mixture with the common features (appearing in a large fraction of data). In contrast, standard training can only learn the common features but fails to learn the rare features, thus suffering from bad generalization performance. Moreover, our theoretical analysis also shows that the benefits of Mixup for feature learning are mostly gained in the early training phase, based on which we propose to apply early stopping in Mixup. Experimental results verify our theoretical findings and demonstrate the effectiveness of the early-stopped Mixup training.
Benign Overfitting for Two-layer ReLU Networks
Mar 07, 2023Modern deep learning models with great expressive power can be trained to overfit the training data but still generalize well. This phenomenon is referred to as benign overfitting. Recently, a few studies have attempted to theoretically understand benign overfitting in neural networks. However, these works are either limited to neural networks with smooth activation functions or to the neural tangent kernel regime. How and when benign overfitting can occur in ReLU neural networks remains an open problem. In this work, we seek to answer this question by establishing algorithm-dependent risk bounds for learning two-layer ReLU convolutional neural networks with label-flipping noise. We show that, under mild conditions, the neural network trained by gradient descent can achieve near-zero training loss and Bayes optimal test risk. Our result also reveals a sharp transition between benign and harmful overfitting under different conditions on data distribution in terms of test risk. Experiments on synthetic data back up our theory.
Learning High-Dimensional Single-Neuron ReLU Networks with Finite Samples
Mar 03, 2023This paper considers the problem of learning a single ReLU neuron with squared loss (a.k.a., ReLU regression) in the overparameterized regime, where the input dimension can exceed the number of samples. We analyze a Perceptron-type algorithm called GLM-tron (Kakade et al., 2011), and provide its dimension-free risk upper bounds for high-dimensional ReLU regression in both well-specified and misspecified settings. Our risk bounds recover several existing results as special cases. Moreover, in the well-specified setting, we also provide an instance-wise matching risk lower bound for GLM-tron. Our upper and lower risk bounds provide a sharp characterization of the high-dimensional ReLU regression problems that can be learned via GLM-tron. On the other hand, we provide some negative results for stochastic gradient descent (SGD) for ReLU regression with symmetric Bernoulli data: if the model is well-specified, the excess risk of SGD is provably no better than that of GLM-tron ignoring constant factors, for each problem instance; and in the noiseless case, GLM-tron can achieve a small risk while SGD unavoidably suffers from a constant risk in expectation. These results together suggest that GLM-tron might be preferable than SGD for high-dimensional ReLU regression.
Variance-Dependent Regret Bounds for Linear Bandits and Reinforcement Learning: Adaptivity and Computational Efficiency
Feb 21, 2023

Recently, several studies (Zhou et al., 2021a; Zhang et al., 2021b; Kim et al., 2021; Zhou and Gu, 2022) have provided variance-dependent regret bounds for linear contextual bandits, which interpolates the regret for the worst-case regime and the deterministic reward regime. However, these algorithms are either computationally intractable or unable to handle unknown variance of the noise. In this paper, we present a novel solution to this open problem by proposing the first computationally efficient algorithm for linear bandits with heteroscedastic noise. Our algorithm is adaptive to the unknown variance of noise and achieves an $\tilde{O}(d \sqrt{\sum_{k = 1}^K \sigma_k^2} + d)$ regret, where $\sigma_k^2$ is the variance of the noise at the round $k$, $d$ is the dimension of the contexts and $K$ is the total number of rounds. Our results are based on an adaptive variance-aware confidence set enabled by a new Freedman-type concentration inequality for self-normalized martingales and a multi-layer structure to stratify the context vectors into different layers with different uniform upper bounds on the uncertainty. Furthermore, our approach can be extended to linear mixture Markov decision processes (MDPs) in reinforcement learning. We propose a variance-adaptive algorithm for linear mixture MDPs, which achieves a problem-dependent horizon-free regret bound that can gracefully reduce to a nearly constant regret for deterministic MDPs. Unlike existing nearly minimax optimal algorithms for linear mixture MDPs, our algorithm does not require explicit variance estimation of the transitional probabilities or the use of high-order moment estimators to attain horizon-free regret. We believe the techniques developed in this paper can have independent value for general online decision making problems.
Structure-informed Language Models Are Protein Designers
Feb 09, 2023This paper demonstrates that language models are strong structure-based protein designers. We present LM-Design, a generic approach to reprogramming sequence-based protein language models (pLMs), that have learned massive sequential evolutionary knowledge from the universe of natural protein sequences, to acquire an immediate capability to design preferable protein sequences for given folds. We conduct a structural surgery on pLMs, where a lightweight structural adapter is implanted into pLMs and endows it with structural awareness. During inference, iterative refinement is performed to effectively optimize the generated protein sequences. Experiments show that LM-Design improves the state-of-the-art results by a large margin, leading to up to 4% to 12% accuracy gains in sequence recovery (e.g., 55.65%/56.63% on CATH 4.2/4.3 single-chain benchmarks, and >60% when designing protein complexes). We provide extensive and in-depth analyses, which verify that LM-Design can (1) indeed leverage both structural and sequential knowledge to accurately handle structurally non-deterministic regions, (2) benefit from scaling data and model size, and (3) generalize to other proteins (e.g., antibodies and de novo proteins)
Corruption-Robust Algorithms with Uncertainty Weighting for Nonlinear Contextual Bandits and Markov Decision Processes
Dec 12, 2022Despite the significant interest and progress in reinforcement learning (RL) problems with adversarial corruption, current works are either confined to the linear setting or lead to an undesired $\tilde{O}(\sqrt{T}\zeta)$ regret bound, where $T$ is the number of rounds and $\zeta$ is the total amount of corruption. In this paper, we consider the contextual bandit with general function approximation and propose a computationally efficient algorithm to achieve a regret of $\tilde{O}(\sqrt{T}+\zeta)$. The proposed algorithm relies on the recently developed uncertainty-weighted least-squares regression from linear contextual bandit \citep{he2022nearly} and a new weighted estimator of uncertainty for the general function class. In contrast to the existing analysis that heavily relies on the linear structure, we develop a novel technique to control the sum of weighted uncertainty, thus establishing the final regret bounds. We then generalize our algorithm to the episodic MDP setting and first achieve an additive dependence on the corruption level $\zeta$ in the scenario of general function approximation. Notably, our algorithms achieve regret bounds either nearly match the performance lower bound or improve the existing methods for all the corruption levels and in both known and unknown $\zeta$ cases.
Nearly Minimax Optimal Reinforcement Learning for Linear Markov Decision Processes
Dec 12, 2022
We study reinforcement learning (RL) with linear function approximation. For episodic time-inhomogeneous linear Markov decision processes (linear MDPs) whose transition dynamic can be parameterized as a linear function of a given feature mapping, we propose the first computationally efficient algorithm that achieves the nearly minimax optimal regret $\tilde O(d\sqrt{H^3K})$, where $d$ is the dimension of the feature mapping, $H$ is the planning horizon, and $K$ is the number of episodes. Our algorithm is based on a weighted linear regression scheme with a carefully designed weight, which depends on a new variance estimator that (1) directly estimates the variance of the \emph{optimal} value function, (2) monotonically decreases with respect to the number of episodes to ensure a better estimation accuracy, and (3) uses a rare-switching policy to update the value function estimator to control the complexity of the estimated value function class. Our work provides a complete answer to optimal RL with linear MDPs, and the developed algorithm and theoretical tools may be of independent interest.
A General Framework for Sample-Efficient Function Approximation in Reinforcement Learning
Sep 30, 2022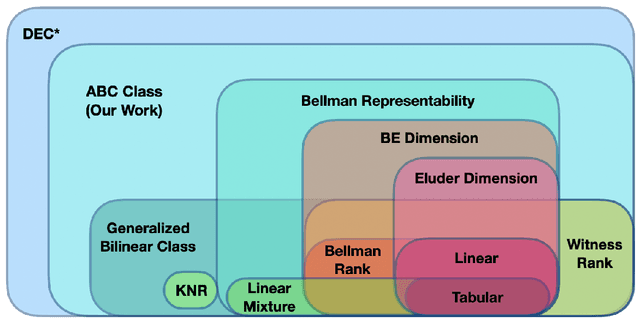
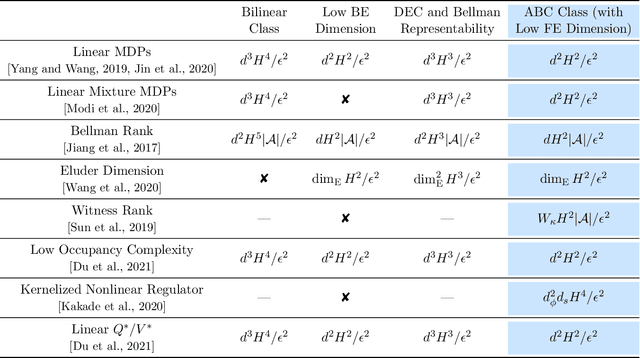
With the increasing need for handling large state and action spaces, general function approximation has become a key technique in reinforcement learning (RL). In this paper, we propose a general framework that unifies model-based and model-free RL, and an Admissible Bellman Characterization (ABC) class that subsumes nearly all Markov Decision Process (MDP) models in the literature for tractable RL. We propose a novel estimation function with decomposable structural properties for optimization-based exploration and the functional eluder dimension as a complexity measure of the ABC class. Under our framework, a new sample-efficient algorithm namely OPtimization-based ExploRation with Approximation (OPERA) is proposed, achieving regret bounds that match or improve over the best-known results for a variety of MDP models. In particular, for MDPs with low Witness rank, under a slightly stronger assumption, OPERA improves the state-of-the-art sample complexity results by a factor of $dH$. Our framework provides a generic interface to design and analyze new RL models and algorithms.
Learning Two-Player Mixture Markov Games: Kernel Function Approximation and Correlated Equilibrium
Aug 10, 2022We consider learning Nash equilibria in two-player zero-sum Markov Games with nonlinear function approximation, where the action-value function is approximated by a function in a Reproducing Kernel Hilbert Space (RKHS). The key challenge is how to do exploration in the high-dimensional function space. We propose a novel online learning algorithm to find a Nash equilibrium by minimizing the duality gap. At the core of our algorithms are upper and lower confidence bounds that are derived based on the principle of optimism in the face of uncertainty. We prove that our algorithm is able to attain an $O(\sqrt{T})$ regret with polynomial computational complexity, under very mild assumptions on the reward function and the underlying dynamic of the Markov Games. We also propose several extensions of our algorithm, including an algorithm with Bernstein-type bonus that can achieve a tighter regret bound, and another algorithm for model misspecification that can be applied to neural function approximation.