 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuan Wang
Sample Efficient Adaptive Text-to-Speech
Sep 27, 2018
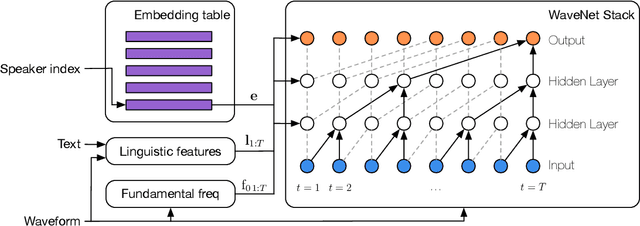
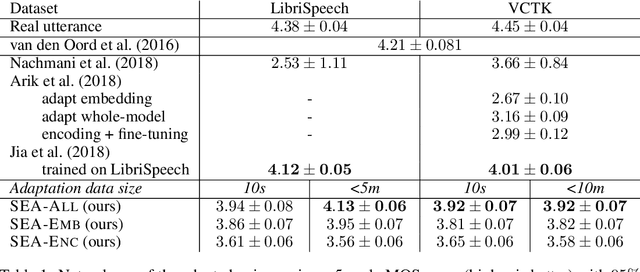
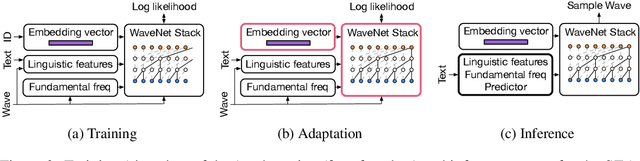
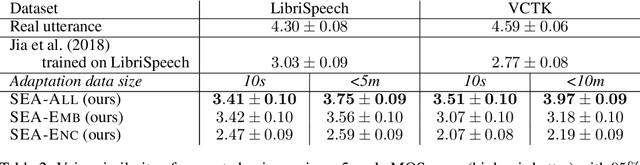
We present a meta-learning approach for adaptive text-to-speech (TTS) with few data. During training, we learn a multi-speaker model using a shared conditional WaveNet core and independent learned embeddings for each speaker. The aim of training is not to produce a neural network with fixed weights, which is then deployed as a TTS system. Instead, the aim is to produce a network that requires few data at deployment time to rapidly adapt to new speakers. We introduce and benchmark three strategies: (i) learning the speaker embedding while keeping the WaveNet core fixed, (ii) fine-tuning the entire architecture with stochastic gradient descent, and (iii) predicting the speaker embedding with a trained neural network encoder. The experiments show that these approaches are successful at adapting the multi-speaker neural network to new speakers, obtaining state-of-the-art results in both sample naturalness and voice similarity with merely a few minutes of audio data from new speakers.
An Efficient Approach for Polyps Detection in Endoscopic Videos Based on Faster R-CNN
Sep 04, 2018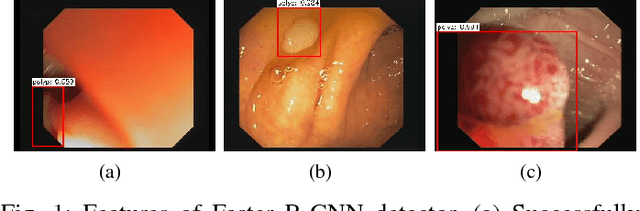
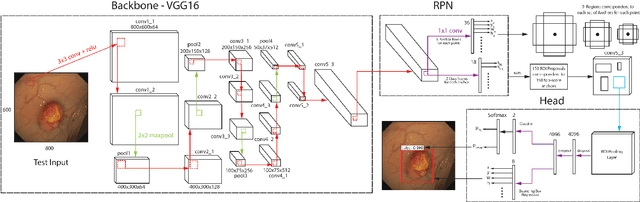
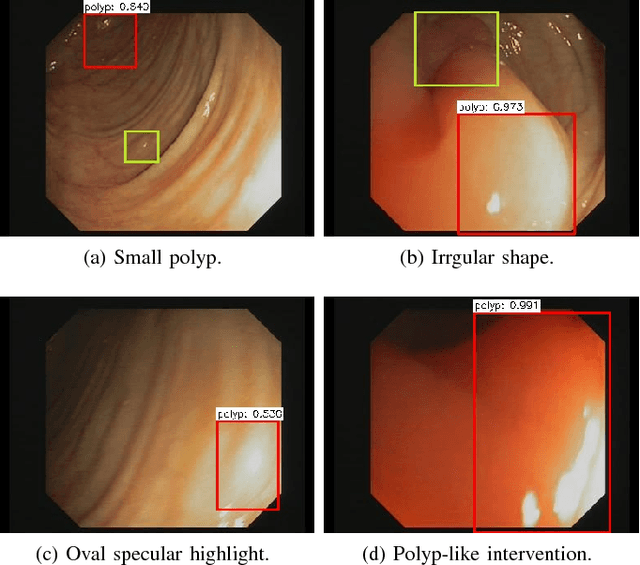
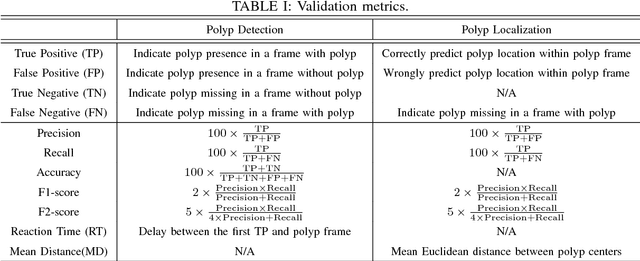
Polyp has long been considered as one of the major etiologies to colorectal cancer which is a fatal disease around the world, thus early detection and recognition of polyps plays a crucial role in clinical routines. Accurate diagnoses of polyps through endoscopes operated by physicians becomes a challenging task not only due to the varying expertise of physicians, but also the inherent nature of endoscopic inspections. To facilitate this process, computer-aid techniques that emphasize fully-conventional image processing and novel machine learning enhanced approaches have been dedicatedly designed for polyp detection in endoscopic videos or images. Among all proposed algorithms, deep learning based methods take the lead in terms of multiple metrics in evolutions for algorithmic performance. In this work, a highly effective model, namely the faster region-based convolutional neural network (Faster R-CNN) is implemented for polyp detection. In comparison with the reported results of the state-of-the-art approaches on polyps detection, extensive experiments demonstrate that the Faster R-CNN achieves very competing results, and it is an efficient approach for clinical practice.
Look at Boundary: A Boundary-Aware Face Alignment Algorithm
May 26, 2018
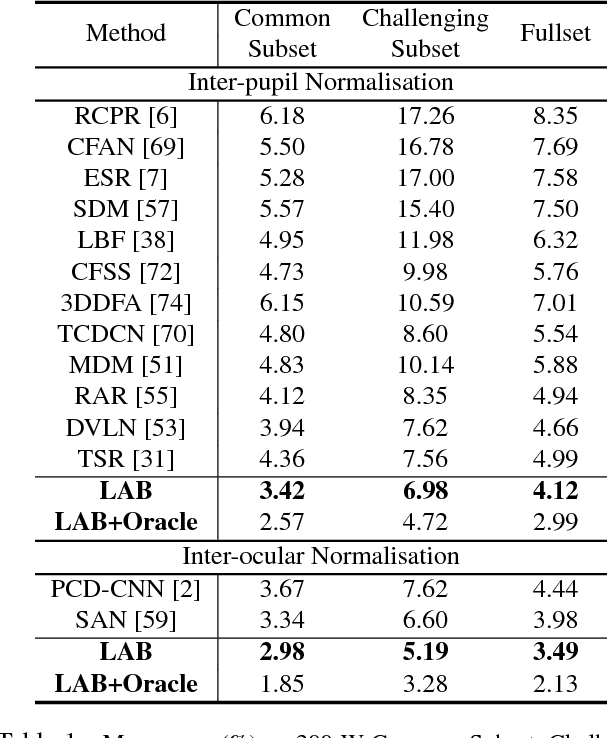
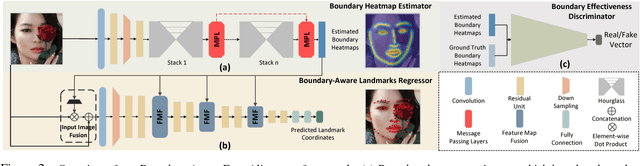
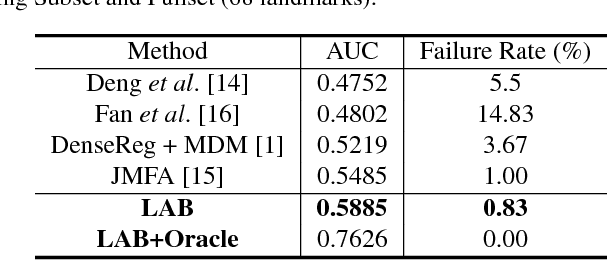
We present a novel boundary-aware face alignment algorithm by utilising boundary lines as the geometric structure of a human face to help facial landmark localisation. Unlike the conventional heatmap based method and regression based method, our approach derives face landmarks from boundary lines which remove the ambiguities in the landmark definition. Three questions are explored and answered by this work: 1. Why using boundary? 2. How to use boundary? 3. What is the relationship between boundary estimation and landmarks localisation? Our boundary- aware face alignment algorithm achieves 3.49% mean error on 300-W Fullset, which outperforms state-of-the-art methods by a large margin. Our method can also easily integrate information from other datasets. By utilising boundary information of 300-W dataset, our method achieves 3.92% mean error with 0.39% failure rate on COFW dataset, and 1.25% mean error on AFLW-Full dataset. Moreover, we propose a new dataset WFLW to unify training and testing across different factors, including poses, expressions, illuminations, makeups, occlusions, and blurriness. Dataset and model will be publicly available at https://wywu.github.io/projects/LAB/LAB.html
Improving Knowledge Graph Embedding Using Simple Constraints
May 08, 2018
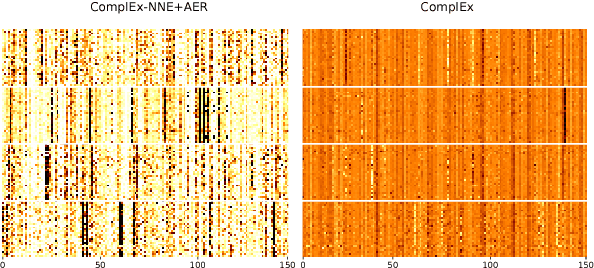
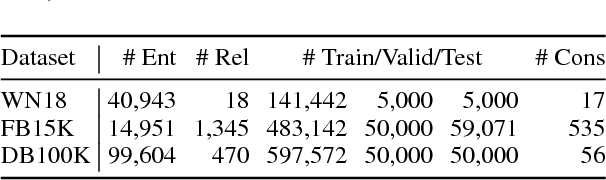
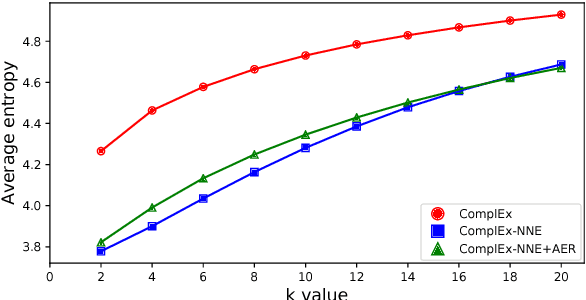
Embedding knowledge graphs (KGs) into continuous vector spaces is a focus of current research. Early works performed this task via simple models developed over KG triples. Recent attempts focused on either designing more complicated triple scoring models, or incorporating extra information beyond triples. This paper, by contrast, investigates the potential of using very simple constraints to improve KG embedding. We examine non-negativity constraints on entity representations and approximate entailment constraints on relation representations. The former help to learn compact and interpretable representations for entities. The latter further encode regularities of logical entailment between relations into their distributed representations. These constraints impose prior beliefs upon the structure of the embedding space, without negative impacts on efficiency or scalability. Evaluation on WordNet, Freebase, and DBpedia shows that our approach is simple yet surprisingly effective, significantly and consistently outperforming competitive baselines. The constraints imposed indeed improve model interpretability, leading to a substantially increased structuring of the embedding space. Code and data are available at https://github.com/iieir-km/ComplEx-NNE_AER.
Generalized End-to-End Loss for Speaker Verification
Jan 31, 2018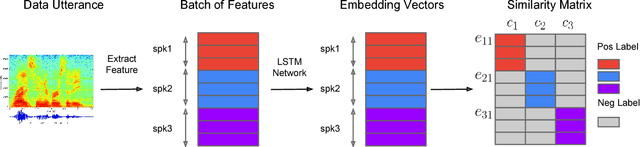
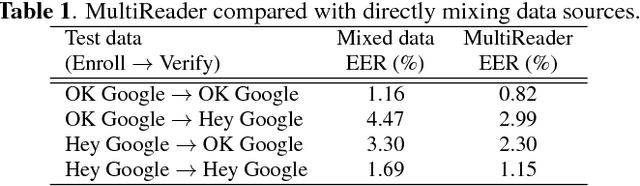
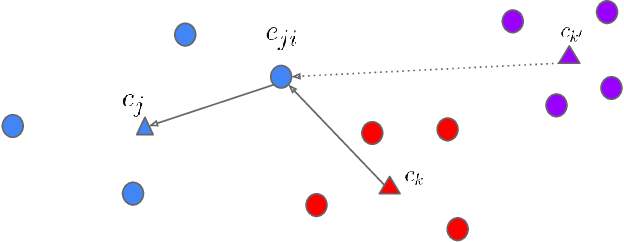
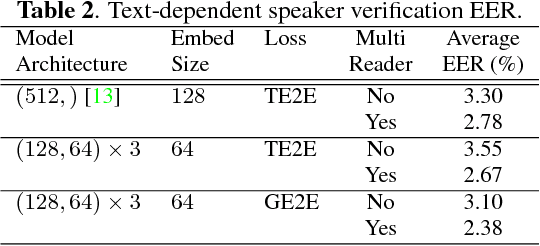
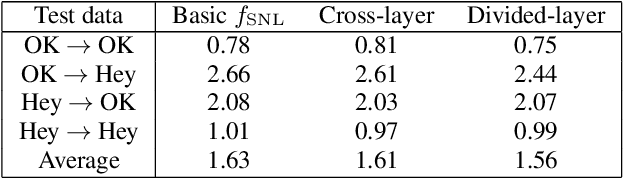
In this paper, we propose a new loss function called generalized end-to-end (GE2E) loss, which makes the training of speaker verification models more efficient than our previous tuple-based end-to-end (TE2E) loss function. Unlike TE2E, the GE2E loss function updates the network in a way that emphasizes examples that are difficult to verify at each step of the training process. Additionally, the GE2E loss does not require an initial stage of example selection. With these properties, our model with the new loss function decreases speaker verification EER by more than 10%, while reducing the training time by 60% at the same time. We also introduce the MultiReader technique, which allows us to do domain adaptation - training a more accurate model that supports multiple keywords (i.e. "OK Google" and "Hey Google") as well as multiple dialects.
Attention-Based Models for Text-Dependent Speaker Verification
Jan 31, 2018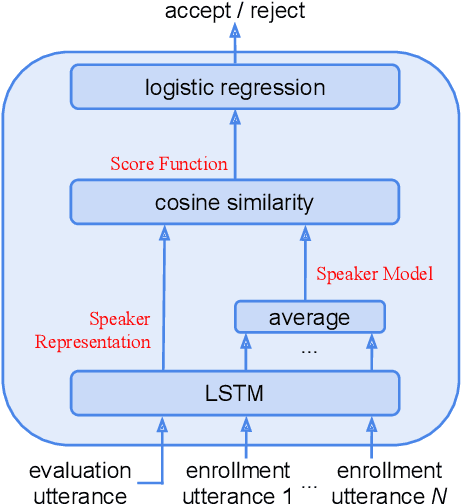
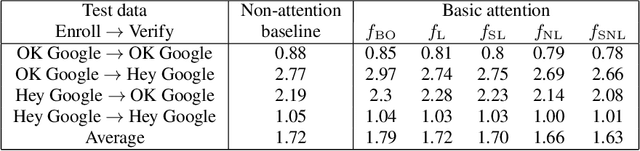
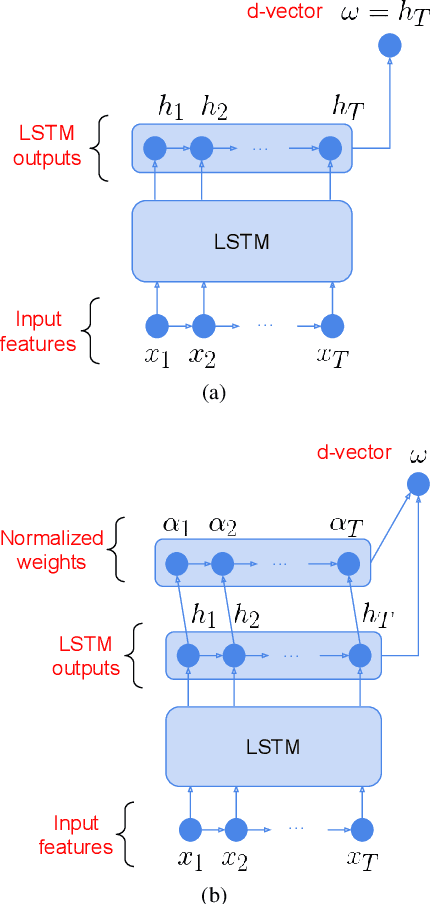
Attention-based models have recently shown great performance on a range of tasks, such as speech recognition, machine translation, and image captioning due to their ability to summarize relevant information that expands through the entire length of an input sequence. In this paper, we analyze the usage of attention mechanisms to the problem of sequence summarization in our end-to-end text-dependent speaker recognition system. We explore different topologies and their variants of the attention layer, and compare different pooling methods on the attention weights. Ultimately, we show that attention-based models can improves the Equal Error Rate (EER) of our speaker verification system by relatively 14% compared to our non-attention LSTM baseline model.
Speaker Diarization with LSTM
Jan 31, 2018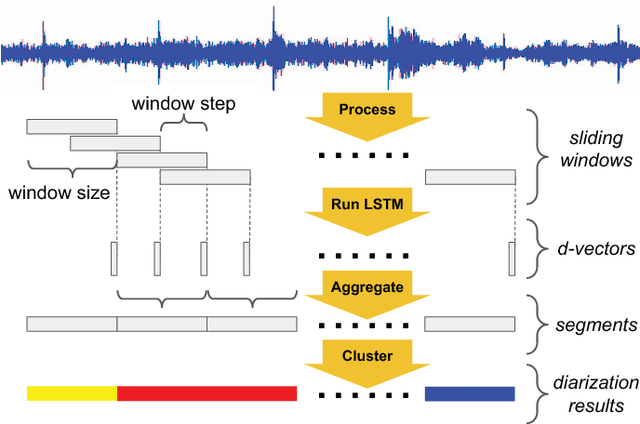
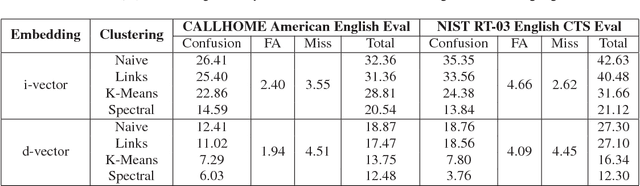

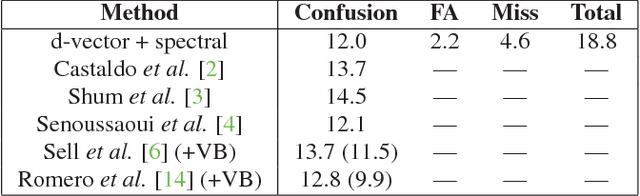
For many years, i-vector based audio embedding techniques were the dominant approach for speaker verification and speaker diarization applications. However, mirroring the rise of deep learning in various domains, neural network based audio embeddings, also known as d-vectors, have consistently demonstrated superior speaker verification performance. In this paper, we build on the success of d-vector based speaker verification systems to develop a new d-vector based approach to speaker diarization. Specifically, we combine LSTM-based d-vector audio embeddings with recent work in non-parametric clustering to obtain a state-of-the-art speaker diarization system. Our system is evaluated on three standard public datasets, suggesting that d-vector based diarization systems offer significant advantages over traditional i-vector based systems. We achieved a 12.0% diarization error rate on NIST SRE 2000 CALLHOME, while our model is trained with out-of-domain data from voice search logs.
Links: A High-Dimensional Online Clustering Method
Jan 30, 2018We present a novel algorithm, called Links, designed to perform online clustering on unit vectors in a high-dimensional Euclidean space. The algorithm is appropriate when it is necessary to cluster data efficiently as it streams in, and is to be contrasted with traditional batch clustering algorithms that have access to all data at once. For example, Links has been successfully applied to embedding vectors generated from face images or voice recordings for the purpose of recognizing people, thereby providing real-time identification during video or audio capture.
Knowledge Graph Embedding with Iterative Guidance from Soft Rules
Nov 30, 2017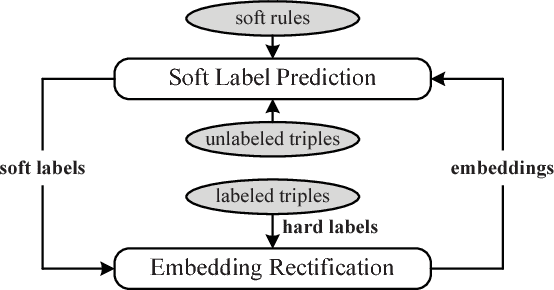

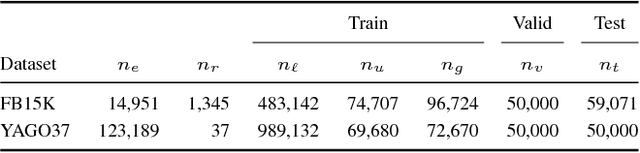
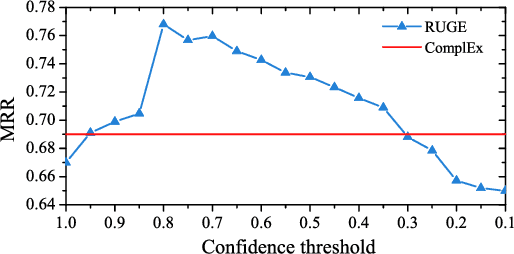
Embedding knowledge graphs (KGs) into continuous vector spaces is a focus of current research. Combining such an embedding model with logic rules has recently attracted increasing attention. Most previous attempts made a one-time injection of logic rules, ignoring the interactive nature between embedding learning and logical inference. And they focused only on hard rules, which always hold with no exception and usually require extensive manual effort to create or validate. In this paper, we propose Rule-Guided Embedding (RUGE), a novel paradigm of KG embedding with iterative guidance from soft rules. RUGE enables an embedding model to learn simultaneously from 1) labeled triples that have been directly observed in a given KG, 2) unlabeled triples whose labels are going to be predicted iteratively, and 3) soft rules with various confidence levels extracted automatically from the KG. In the learning process, RUGE iteratively queries rules to obtain soft labels for unlabeled triples, and integrates such newly labeled triples to update the embedding model. Through this iterative procedure, knowledge embodied in logic rules may be better transferred into the learned embeddings. We evaluate RUGE in link prediction on Freebase and YAGO. Experimental results show that: 1) with rule knowledge injected iteratively, RUGE achieves significant and consistent improvements over state-of-the-art baselines; and 2) despite their uncertainties, automatically extracted soft rules are highly beneficial to KG embedding, even those with moderate confidence levels. The code and data used for this paper can be obtained from https://github.com/iieir-km/RUGE.
Distributed Simulation Platform for Autonomous Driving
May 31, 2017
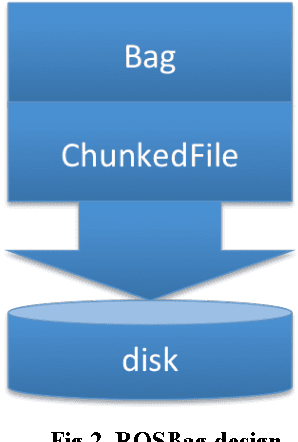
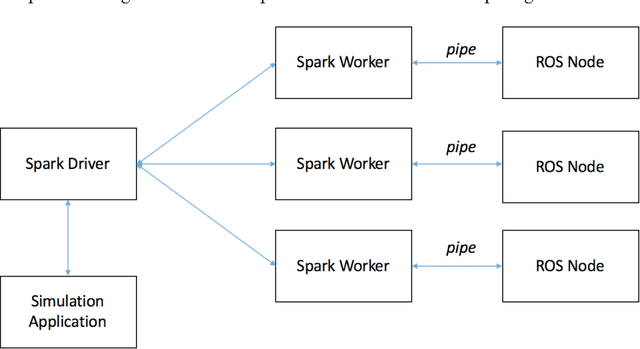
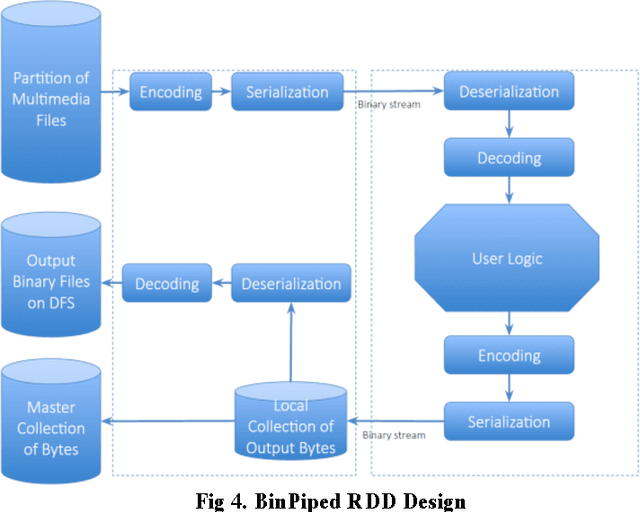
Autonomous vehicle safety and reliability are the paramount requirements when developing autonomous vehicles. These requirements are guaranteed by massive functional and performance tests. Conducting these tests on real vehicles is extremely expensive and time consuming, and thus it is imperative to develop a simulation platform to perform these tasks. For simulation, we can utilize the Robot Operating System (ROS) for data playback to test newly developed algorithms. However, due to the massive amount of simulation data, performing simulation on single machines is not practical. Hence, a high-performance distributed simulation platform is a critical piece in autonomous driving development. In this paper we present our experiences of building a production distributed autonomous driving simulation platform. This platform is built upon Spark distributed framework, for distributed computing management, and ROS, for data playback simulations.