 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Spatial-spectral Network Learning for Hyperspectral Compressive Snapshot Reconstruction
Dec 18, 2020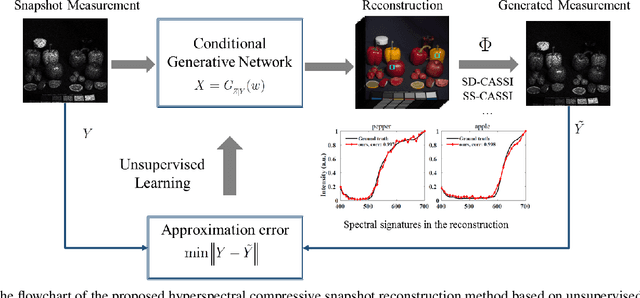


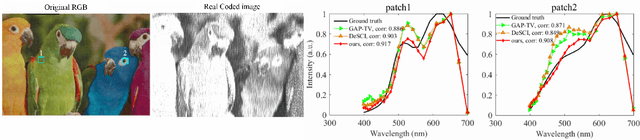
Hyperspectral compressive imaging takes advantage of compressive sensing theory to achieve coded aperture snapshot measurement without temporal scanning, and the entire three-dimensional spatial-spectral data is captured by a two-dimensional projection during a single integration period. Its core issue is how to reconstruct the underlying hyperspectral image using compressive sensing reconstruction algorithms. Due to the diversity in the spectral response characteristics and wavelength range of different spectral imaging devices, previous works are often inadequate to capture complex spectral variations or lack the adaptive capacity to new hyperspectral imagers. In order to address these issues, we propose an unsupervised spatial-spectral network to reconstruct hyperspectral images only from the compressive snapshot measurement. The proposed network acts as a conditional generative model conditioned on the snapshot measurement, and it exploits the spatial-spectral attention module to capture the joint spatial-spectral correlation of hyperspectral images. The network parameters are optimized to make sure that the network output can closely match the given snapshot measurement according to the imaging model, thus the proposed network can adapt to different imaging settings, which can inherently enhance the applicability of the network. Extensive experiments upon multiple datasets demonstrate that our network can achieve better reconstruction results than the state-of-the-art methods.
Meta-Learning with Network Pruning
Jul 07, 2020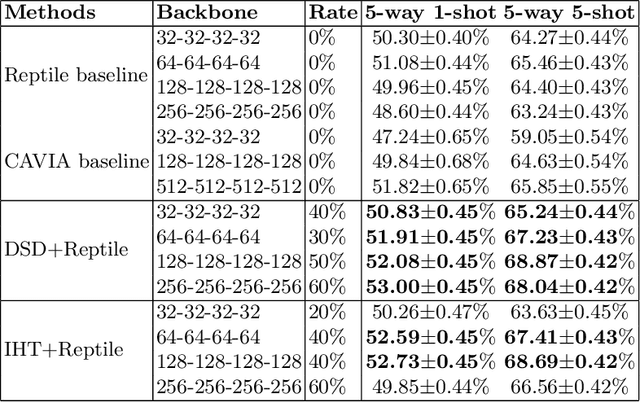
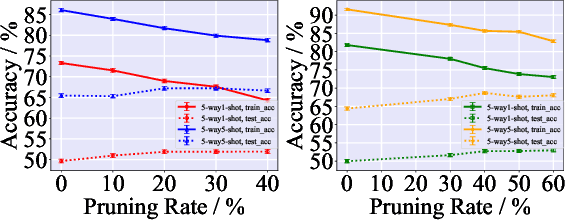
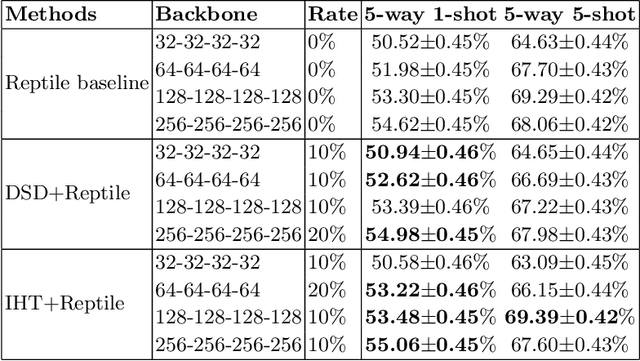
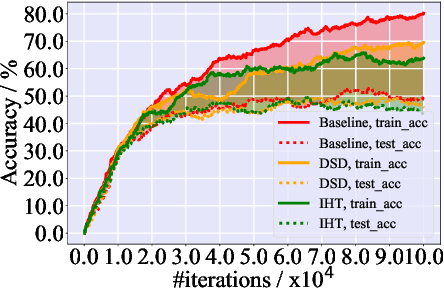
Meta-learning is a powerful paradigm for few-shot learning. Although with remarkable success witnessed in many applications, the existing optimization based meta-learning models with over-parameterized neural networks have been evidenced to ovetfit on training tasks. To remedy this deficiency, we propose a network pruning based meta-learning approach for overfitting reduction via explicitly controlling the capacity of network. A uniform concentration analysis reveals the benefit of network capacity constraint for reducing generalization gap of the proposed meta-learner. We have implemented our approach on top of Reptile assembled with two network pruning routines: Dense-Sparse-Dense (DSD) and Iterative Hard Thresholding (IHT). Extensive experimental results on benchmark datasets with different over-parameterized deep networks demonstrate that our method not only effectively alleviates meta-overfitting but also in many cases improves the overall generalization performance when applied to few-shot classification tasks.
Hyperspectral Image Classification with Attention Aided CNNs
Jun 12, 2020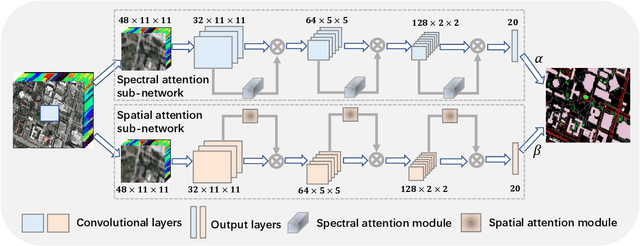
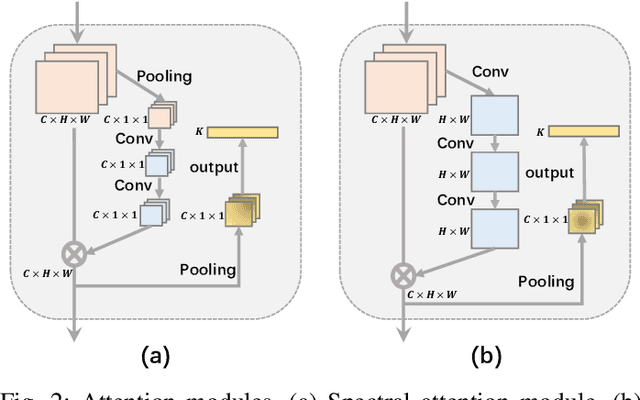

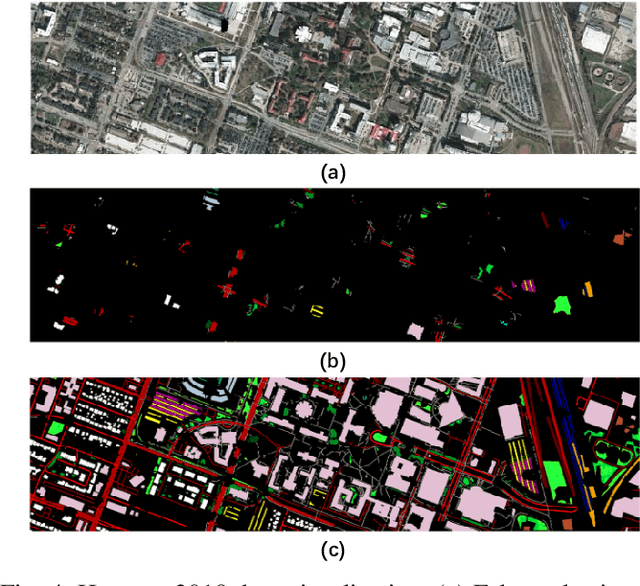
Convolutional neural networks (CNNs) have been widely used for hyperspectral image classification. As a common process, small cubes are firstly cropped from the hyperspectral image and then fed into CNNs to extract spectral and spatial features. It is well known that different spectral bands and spatial positions in the cubes have different discriminative abilities. If fully explored, this prior information will help improve the learning capacity of CNNs. Along this direction, we propose an attention aided CNN model for spectral-spatial classification of hyperspectral images. Specifically, a spectral attention sub-network and a spatial attention sub-network are proposed for spectral and spatial classification, respectively. Both of them are based on the traditional CNN model, and incorporate attention modules to aid networks focus on more discriminative channels or positions. In the final classification phase, the spectral classification result and the spatial classification result are combined together via an adaptively weighted summation method. To evaluate the effectiveness of the proposed model, we conduct experiments on three standard hyperspectral datasets. The experimental results show that the proposed model can achieve superior performance compared to several state-of-the-art CNN-related models.
Adaptive Graph Convolutional Network with Attention Graph Clustering for Co-saliency Detection
Mar 13, 2020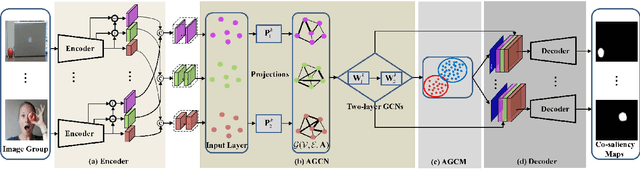
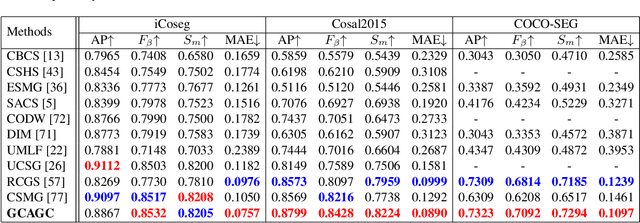
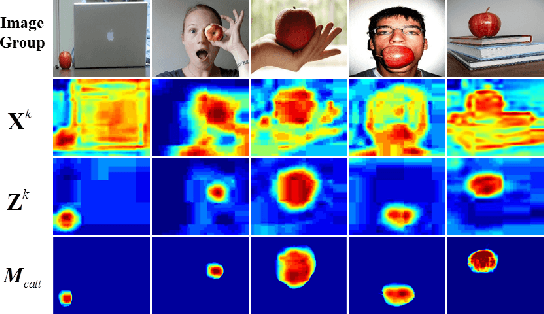
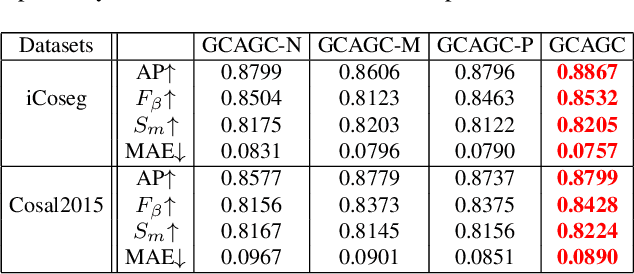
Co-saliency detection aims to discover the common and salient foregrounds from a group of relevant images. For this task, we present a novel adaptive graph convolutional network with attention graph clustering (GCAGC). Three major contributions have been made, and are experimentally shown to have substantial practical merits. First, we propose a graph convolutional network design to extract information cues to characterize the intra- and interimage correspondence. Second, we develop an attention graph clustering algorithm to discriminate the common objects from all the salient foreground objects in an unsupervised fashion. Third, we present a unified framework with encoder-decoder structure to jointly train and optimize the graph convolutional network, attention graph cluster, and co-saliency detection decoder in an end-to-end manner. We evaluate our proposed GCAGC method on three cosaliency detection benchmark datasets (iCoseg, Cosal2015 and COCO-SEG). Our GCAGC method obtains significant improvements over the state-of-the-arts on most of them.
Dual Temporal Memory Network for Efficient Video Object Segmentation
Mar 13, 2020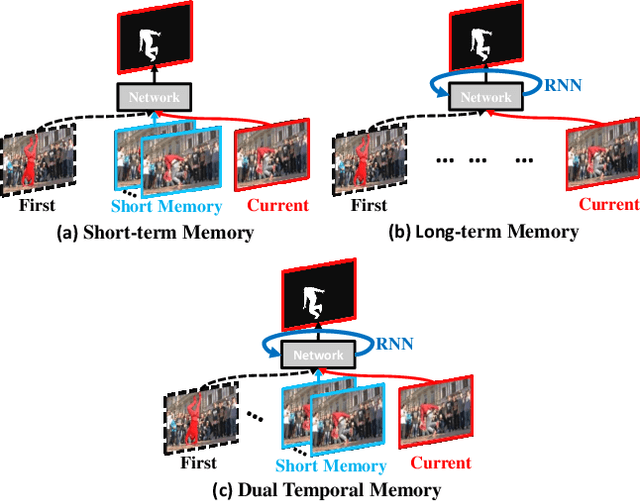
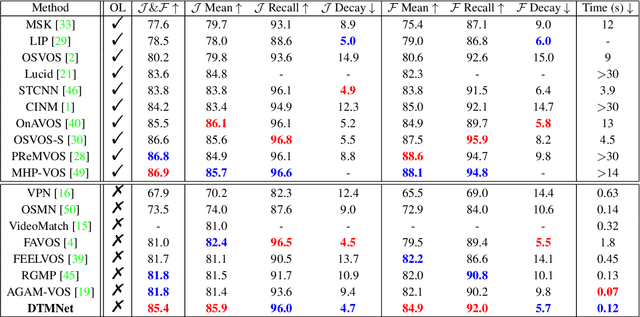
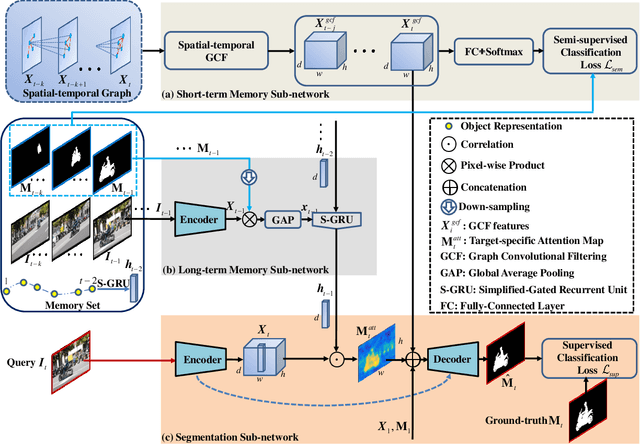
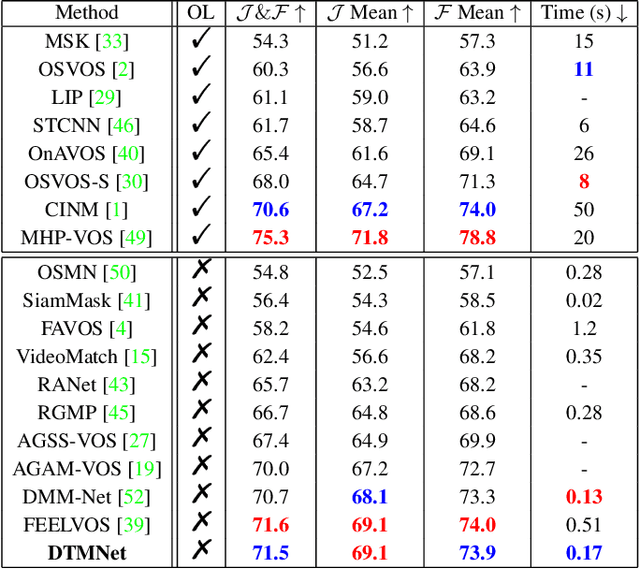
Video Object Segmentation (VOS) is typically formulated in a semi-supervised setting. Given the ground-truth segmentation mask on the first frame, the task of VOS is to track and segment the single or multiple objects of interests in the rest frames of the video at the pixel level. One of the fundamental challenges in VOS is how to make the most use of the temporal information to boost the performance. We present an end-to-end network which stores short- and long-term video sequence information preceding the current frame as the temporal memories to address the temporal modeling in VOS. Our network consists of two temporal sub-networks including a short-term memory sub-network and a long-term memory sub-network. The short-term memory sub-network models the fine-grained spatial-temporal interactions between local regions across neighboring frames in video via a graph-based learning framework, which can well preserve the visual consistency of local regions over time. The long-term memory sub-network models the long-range evolution of object via a Simplified-Gated Recurrent Unit (S-GRU), making the segmentation be robust against occlusions and drift errors. In our experiments, we show that our proposed method achieves a favorable and competitive performance on three frequently-used VOS datasets, including DAVIS 2016, DAVIS 2017 and Youtube-VOS in terms of both speed and accuracy.
Classification of Hyperspectral and LiDAR Data Using Coupled CNNs
Feb 04, 2020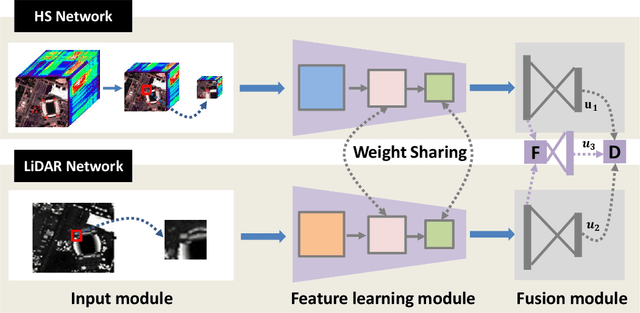
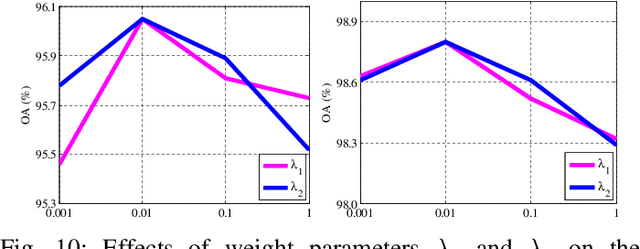
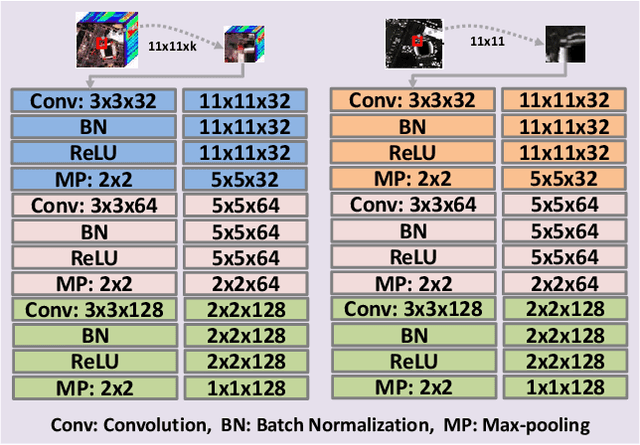
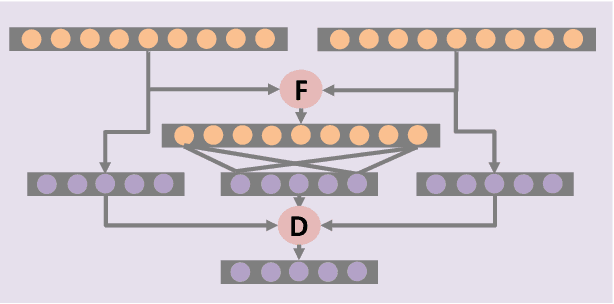
In this paper, we propose an efficient and effective framework to fuse hyperspectral and Light Detection And Ranging (LiDAR) data using two coupled convolutional neural networks (CNNs). One CNN is designed to learn spectral-spatial features from hyperspectral data, and the other one is used to capture the elevation information from LiDAR data. Both of them consist of three convolutional layers, and the last two convolutional layers are coupled together via a parameter sharing strategy. In the fusion phase, feature-level and decision-level fusion methods are simultaneously used to integrate these heterogeneous features sufficiently. For the feature-level fusion, three different fusion strategies are evaluated, including the concatenation strategy, the maximization strategy, and the summation strategy. For the decision-level fusion, a weighted summation strategy is adopted, where the weights are determined by the classification accuracy of each output. The proposed model is evaluated on an urban data set acquired over Houston, USA, and a rural one captured over Trento, Italy. On the Houston data, our model can achieve a new record overall accuracy of 96.03%. On the Trento data, it achieves an overall accuracy of 99.12%. These results sufficiently certify the effectiveness of our proposed model.
Video Saliency Prediction Using Enhanced Spatiotemporal Alignment Network
Jan 02, 2020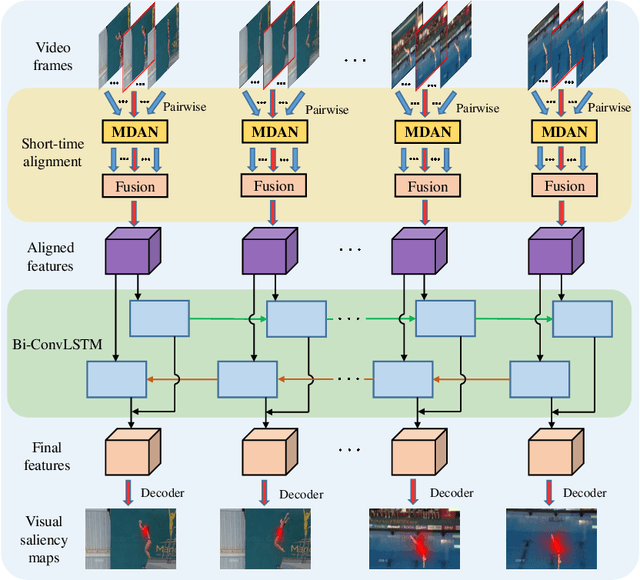
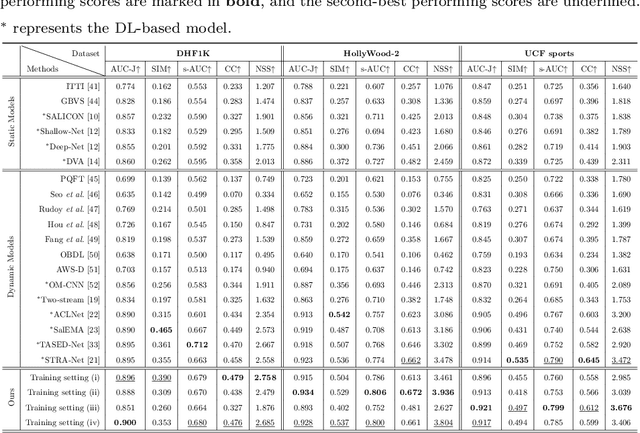

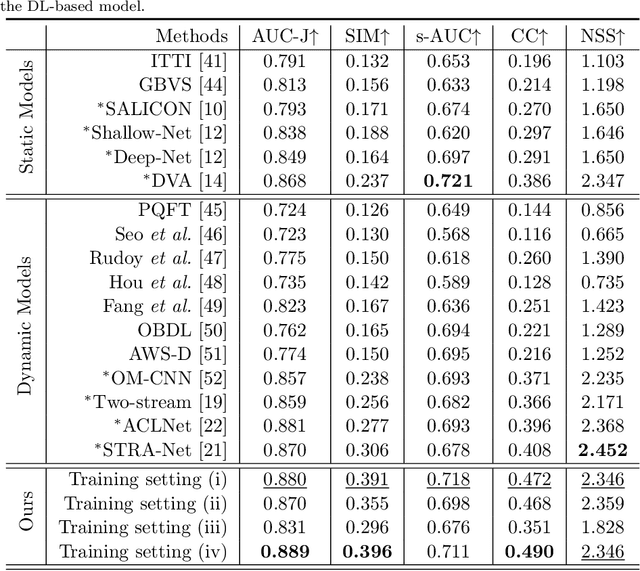
Due to a variety of motions across different frames, it is highly challenging to learn an effective spatiotemporal representation for accurate video saliency prediction (VSP). To address this issue, we develop an effective spatiotemporal feature alignment network tailored to VSP, mainly including two key sub-networks: a multi-scale deformable convolutional alignment network (MDAN) and a bidirectional convolutional Long Short-Term Memory (Bi-ConvLSTM) network. The MDAN learns to align the features of the neighboring frames to the reference one in a coarse-to-fine manner, which can well handle various motions. Specifically, the MDAN owns a pyramidal feature hierarchy structure that first leverages deformable convolution (Dconv) to align the lower-resolution features across frames, and then aggregates the aligned features to align the higher-resolution features, progressively enhancing the features from top to bottom. The output of MDAN is then fed into the Bi-ConvLSTM for further enhancement, which captures the useful long-time temporal information along forward and backward timing directions to effectively guide attention orientation shift prediction under complex scene transformation. Finally, the enhanced features are decoded to generate the predicted saliency map. The proposed model is trained end-to-end without any intricate post processing. Extensive evaluations on four VSP benchmark datasets demonstrate that the proposed method achieves favorable performance against state-of-the-art methods. The source codes and all the results will be released.
Deep Object Co-segmentation via Spatial-Semantic Network Modulation
Nov 29, 2019
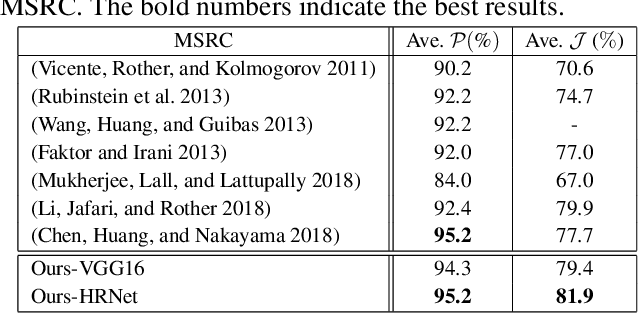
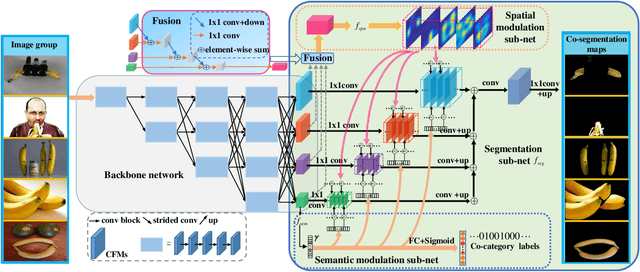
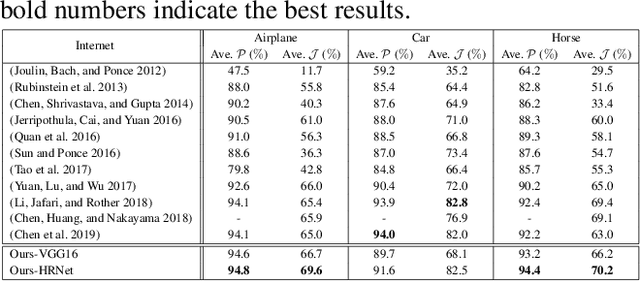
Object co-segmentation is to segment the shared objects in multiple relevant images, which has numerous applications in computer vision. This paper presents a spatial and semantic modulated deep network framework for object co-segmentation. A backbone network is adopted to extract multi-resolution image features. With the multi-resolution features of the relevant images as input, we design a spatial modulator to learn a mask for each image. The spatial modulator captures the correlations of image feature descriptors via unsupervised learning. The learned mask can roughly localize the shared foreground object while suppressing the background. For the semantic modulator, we model it as a supervised image classification task. We propose a hierarchical second-order pooling module to transform the image features for classification use. The outputs of the two modulators manipulate the multi-resolution features by a shift-and-scale operation so that the features focus on segmenting co-object regions. The proposed model is trained end-to-end without any intricate post-processing. Extensive experiments on four image co-segmentation benchmark datasets demonstrate the superior accuracy of the proposed method compared to state-of-the-art methods.
Cascaded Recurrent Neural Networks for Hyperspectral Image Classification
Feb 28, 2019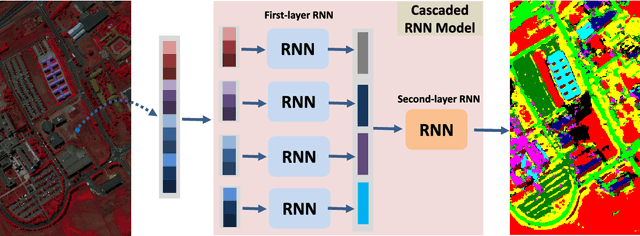
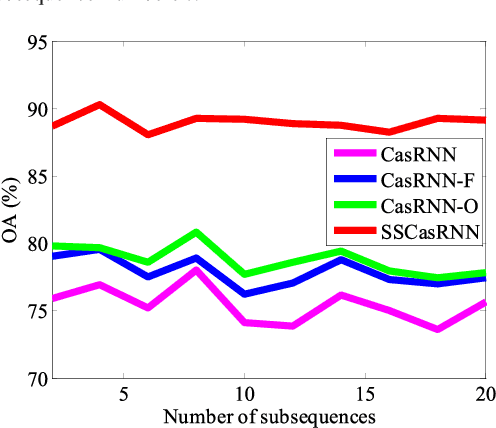
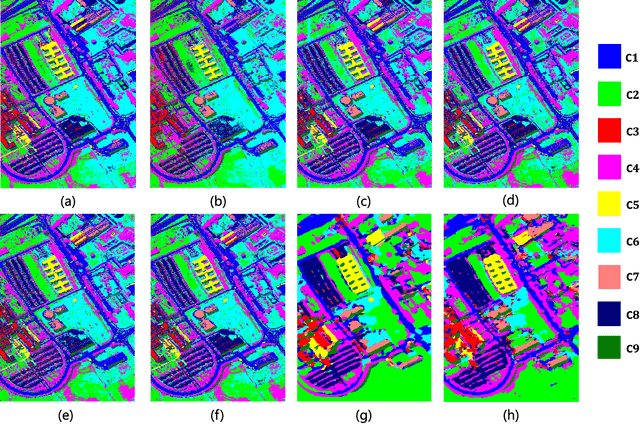
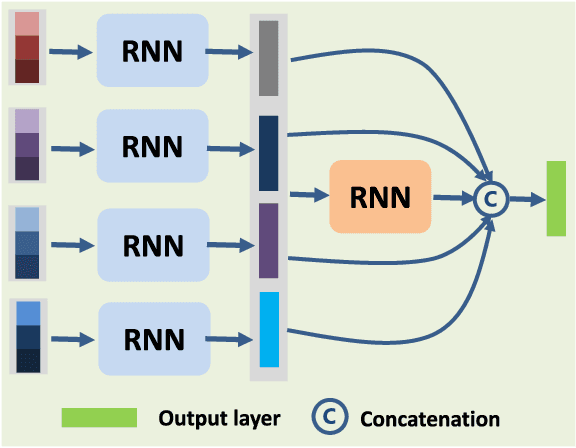
By considering the spectral signature as a sequence, recurrent neural networks (RNNs) have been successfully used to learn discriminative features from hyperspectral images (HSIs) recently. However, most of these models only input the whole spectral bands into RNNs directly, which may not fully explore the specific properties of HSIs. In this paper, we propose a cascaded RNN model using gated recurrent units (GRUs) to explore the redundant and complementary information of HSIs. It mainly consists of two RNN layers. The first RNN layer is used to eliminate redundant information between adjacent spectral bands, while the second RNN layer aims to learn the complementary information from non-adjacent spectral bands. To improve the discriminative ability of the learned features, we design two strategies for the proposed model. Besides, considering the rich spatial information contained in HSIs, we further extend the proposed model to its spectral-spatial counterpart by incorporating some convolutional layers. To test the effectiveness of our proposed models, we conduct experiments on two widely used HSIs. The experimental results show that our proposed models can achieve better results than the compared models.
Joint Active Learning with Feature Selection via CUR Matrix Decomposition
Sep 09, 2018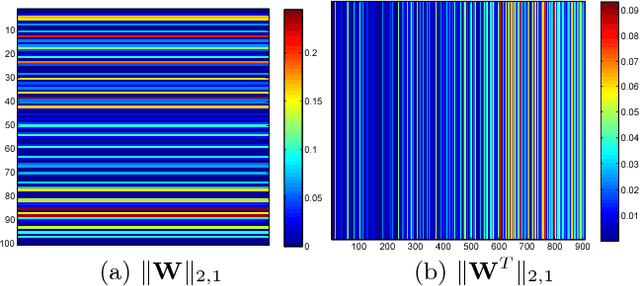
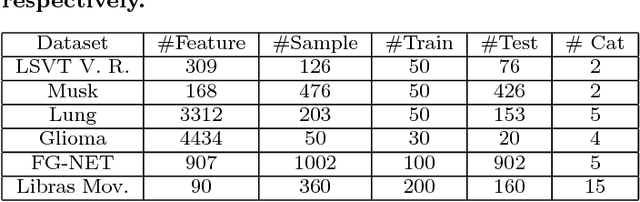
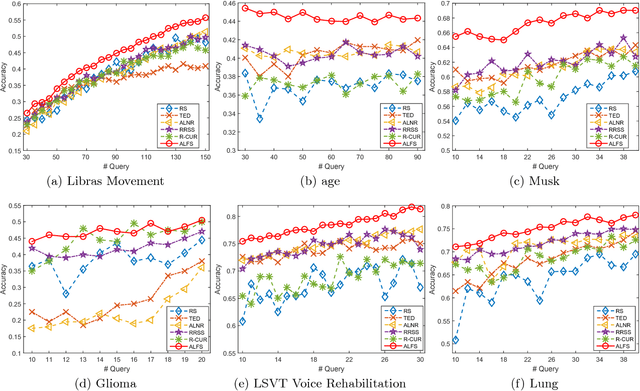
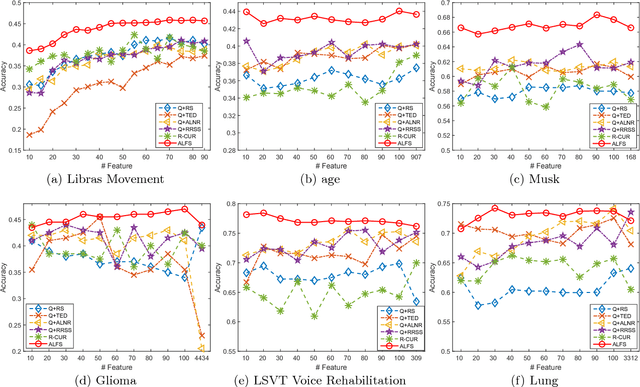
This paper presents an unsupervised learning approach for simultaneous sample and feature selection, which is in contrast to existing works which mainly tackle these two problems separately. In fact the two tasks are often interleaved with each other: noisy and high-dimensional features will bring adverse effect on sample selection, while informative or representative samples will be beneficial to feature selection. Specifically, we propose a framework to jointly conduct active learning and feature selection based on the CUR matrix decomposition. From the data reconstruction perspective, both the selected samples and features can best approximate the original dataset respectively, such that the selected samples characterized by the features are highly representative. In particular, our method runs in one-shot without the procedure of iterative sample selection for progressive labeling. Thus, our model is especially suitable when there are few labeled samples or even in the absence of supervision, which is a particular challenge for existing methods. As the joint learning problem is NP-hard, the proposed formulation involves a convex but non-smooth optimization problem. We solve it efficiently by an iterative algorithm, and prove its global convergence. Experimental results on publicly available datasets corroborate the efficacy of our method compared with the state-of-the-art.