 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D Diffusion for Dynamic Protein Structure Prediction with Reference Guided Motion Alignment
Aug 22, 2024



Protein structure prediction is pivotal for understanding the structure-function relationship of proteins, advancing biological research, and facilitating pharmaceutical development and experimental design. While deep learning methods and the expanded availability of experimental 3D protein structures have accelerated structure prediction, the dynamic nature of protein structures has received limited attention. This study introduces an innovative 4D diffusion model incorporating molecular dynamics (MD) simulation data to learn dynamic protein structures. Our approach is distinguished by the following components: (1) a unified diffusion model capable of generating dynamic protein structures, including both the backbone and side chains, utilizing atomic grouping and side-chain dihedral angle predictions; (2) a reference network that enhances structural consistency by integrating the latent embeddings of the initial 3D protein structures; and (3) a motion alignment module aimed at improving temporal structural coherence across multiple time steps. To our knowledge, this is the first diffusion-based model aimed at predicting protein trajectories across multiple time steps simultaneously. Validation on benchmark datasets demonstrates that our model exhibits high accuracy in predicting dynamic 3D structures of proteins containing up to 256 amino acids over 32 time steps, effectively capturing both local flexibility in stable states and significant conformational changes.
Dynamic PDB: A New Dataset and a SE(3) Model Extension by Integrating Dynamic Behaviors and Physical Properties in Protein Structures
Aug 22, 2024



Despite significant progress in static protein structure collection and prediction, the dynamic behavior of proteins, one of their most vital characteristics, has been largely overlooked in prior research. This oversight can be attributed to the limited availability, diversity, and heterogeneity of dynamic protein datasets. To address this gap, we propose to enhance existing prestigious static 3D protein structural databases, such as the Protein Data Bank (PDB), by integrating dynamic data and additional physical properties. Specifically, we introduce a large-scale dataset, Dynamic PDB, encompassing approximately 12.6K proteins, each subjected to all-atom molecular dynamics (MD) simulations lasting 1 microsecond to capture conformational changes. Furthermore, we provide a comprehensive suite of physical properties, including atomic velocities and forces, potential and kinetic energies of proteins, and the temperature of the simulation environment, recorded at 1 picosecond intervals throughout the simulations. For benchmarking purposes, we evaluate state-of-the-art methods on the proposed dataset for the task of trajectory prediction. To demonstrate the value of integrating richer physical properties in the study of protein dynamics and related model design, we base our approach on the SE(3) diffusion model and incorporate these physical properties into the trajectory prediction process. Preliminary results indicate that this straightforward extension of the SE(3) model yields improved accuracy, as measured by MAE and RMSD, when the proposed physical properties are taken into consideration.
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Jun 16, 2024



The field of portrait image animation, driven by speech audio input, has experienced significant advancements in the generation of realistic and dynamic portraits. This research delves into the complexities of synchronizing facial movements and creating visually appealing, temporally consistent animations within the framework of diffusion-based methodologies. Moving away from traditional paradigms that rely on parametric models for intermediate facial representations, our innovative approach embraces the end-to-end diffusion paradigm and introduces a hierarchical audio-driven visual synthesis module to enhance the precision of alignment between audio inputs and visual outputs, encompassing lip, expression, and pose motion. Our proposed network architecture seamlessly integrates diffusion-based generative models, a UNet-based denoiser, temporal alignment techniques, and a reference network. The proposed hierarchical audio-driven visual synthesis offers adaptive control over expression and pose diversity, enabling more effective personalization tailored to different identities. Through a comprehensive evaluation that incorporates both qualitative and quantitative analyses, our approach demonstrates obvious enhancements in image and video quality, lip synchronization precision, and motion diversity. Further visualization and access to the source code can be found at: https://fudan-generative-vision.github.io/hallo.
MM-Diff: High-Fidelity Image Personalization via Multi-Modal Condition Integration
Mar 22, 2024



Recent advances in tuning-free personalized image generation based on diffusion models are impressive. However, to improve subject fidelity, existing methods either retrain the diffusion model or infuse it with dense visual embeddings, both of which suffer from poor generalization and efficiency. Also, these methods falter in multi-subject image generation due to the unconstrained cross-attention mechanism. In this paper, we propose MM-Diff, a unified and tuning-free image personalization framework capable of generating high-fidelity images of both single and multiple subjects in seconds. Specifically, to simultaneously enhance text consistency and subject fidelity, MM-Diff employs a vision encoder to transform the input image into CLS and patch embeddings. CLS embeddings are used on the one hand to augment the text embeddings, and on the other hand together with patch embeddings to derive a small number of detail-rich subject embeddings, both of which are efficiently integrated into the diffusion model through the well-designed multimodal cross-attention mechanism. Additionally, MM-Diff introduces cross-attention map constraints during the training phase, ensuring flexible multi-subject image sampling during inference without any predefined inputs (e.g., layout). Extensive experiments demonstrate the superior performance of MM-Diff over other leading methods.
Fine-grained Text-Video Retrieval with Frozen Image Encoders
Jul 14, 2023



State-of-the-art text-video retrieval (TVR) methods typically utilize CLIP and cosine similarity for efficient retrieval. Meanwhile, cross attention methods, which employ a transformer decoder to compute attention between each text query and all frames in a video, offer a more comprehensive interaction between text and videos. However, these methods lack important fine-grained spatial information as they directly compute attention between text and video-level tokens. To address this issue, we propose CrossTVR, a two-stage text-video retrieval architecture. In the first stage, we leverage existing TVR methods with cosine similarity network for efficient text/video candidate selection. In the second stage, we propose a novel decoupled video text cross attention module to capture fine-grained multimodal information in spatial and temporal dimensions. Additionally, we employ the frozen CLIP model strategy in fine-grained retrieval, enabling scalability to larger pre-trained vision models like ViT-G, resulting in improved retrieval performance. Experiments on text video retrieval datasets demonstrate the effectiveness and scalability of our proposed CrossTVR compared to state-of-the-art approaches.
MeshMVS: Multi-View Stereo Guided Mesh Reconstruction
Oct 17, 2020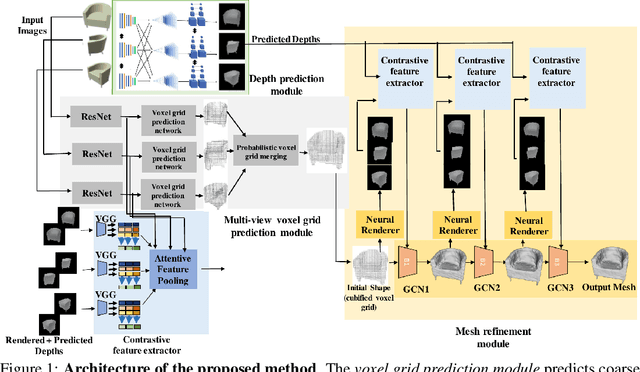
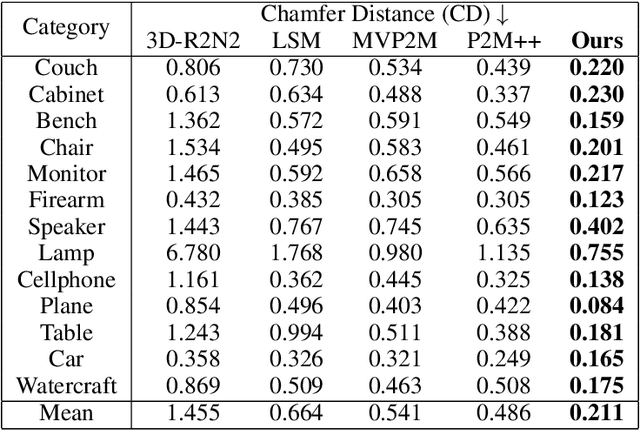


Deep learning based 3D shape generation methods generally utilize latent features extracted from color images to encode the objects' semantics and guide the shape generation process. These color image semantics only implicitly encode 3D information, potentially limiting the accuracy of the generated shapes. In this paper we propose a multi-view mesh generation method which incorporates geometry information in the color images explicitly by using the features from intermediate 2.5D depth representations of the input images and regularizing the 3D shapes against these depth images. Our system first predicts a coarse 3D volume from the color images by probabilistically merging voxel occupancy grids from individual views. Depth images corresponding to the multi-view color images are predicted which along with the rendered depth images of the coarse shape are used as a contrastive input whose features guide the refinement of the coarse shape through a series of graph convolution networks. Attention-based multi-view feature pooling is proposed to fuse the contrastive depth features from different viewpoints which are fed to the graph convolution networks. We validate the proposed multi-view mesh generation method on ShapeNet, where we obtain a significant improvement with 34% decrease in chamfer distance to ground truth and 14% increase in the F1-score compared with the state-of-the-art multi-view shape generation method.
Sketch-R2CNN: An Attentive Network for Vector Sketch Recognition
Nov 20, 2018
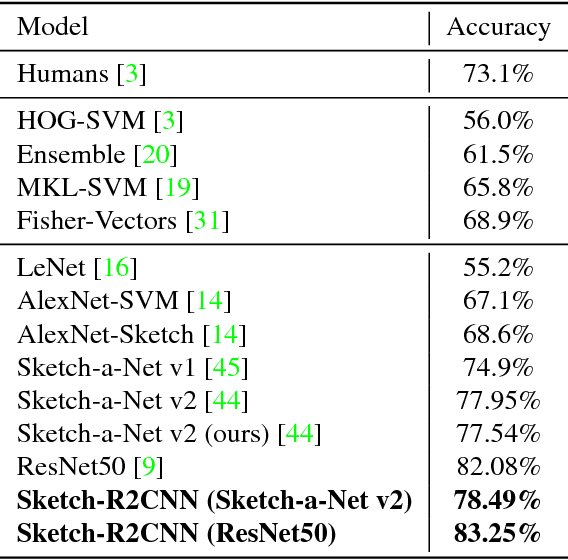
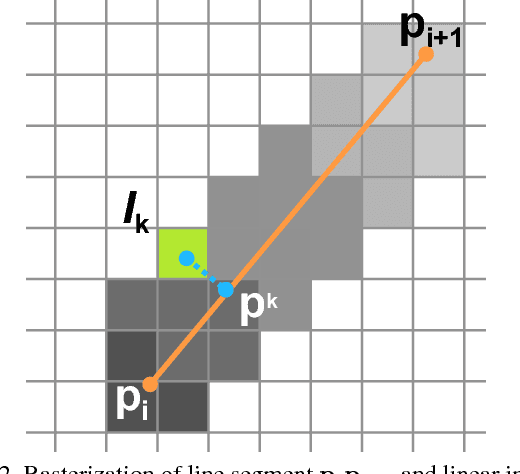

Freehand sketching is a dynamic process where points are sequentially sampled and grouped as strokes for sketch acquisition on electronic devices. To recognize a sketched object, most existing methods discard such important temporal ordering and grouping information from human and simply rasterize sketches into binary images for classification. In this paper, we propose a novel single-branch attentive network architecture RNN-Rasterization-CNN (Sketch-R2CNN for short) to fully leverage the dynamics in sketches for recognition. Sketch-R2CNN takes as input only a vector sketch with grouped sequences of points, and uses an RNN for stroke attention estimation in the vector space and a CNN for 2D feature extraction in the pixel space respectively. To bridge the gap between these two spaces in neural networks, we propose a neural line rasterization module to convert the vector sketch along with the attention estimated by RNN into a bitmap image, which is subsequently consumed by CNN. The neural line rasterization module is designed in a differentiable way to yield a unified pipeline for end-to-end learning. We perform experiments on existing large-scale sketch recognition benchmarks and show that by exploiting the sketch dynamics with the attention mechanism, our method is more robust and achieves better performance than the state-of-the-art methods.