 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenResearcher: Unleashing AI for Accelerated Scientific Research
Aug 13, 2024



The rapid growth of scientific literature imposes significant challenges for researchers endeavoring to stay updated with the latest advancements in their fields and delve into new areas. We introduce OpenResearcher, an innovative platform that leverages Artificial Intelligence (AI) techniques to accelerate the research process by answering diverse questions from researchers. OpenResearcher is built based on Retrieval-Augmented Generation (RAG) to integrate Large Language Models (LLMs) with up-to-date, domain-specific knowledge. Moreover, we develop various tools for OpenResearcher to understand researchers' queries, search from the scientific literature, filter retrieved information, provide accurate and comprehensive answers, and self-refine these answers. OpenResearcher can flexibly use these tools to balance efficiency and effectiveness. As a result, OpenResearcher enables researchers to save time and increase their potential to discover new insights and drive scientific breakthroughs. Demo, video, and code are available at: https://github.com/GAIR-NLP/OpenResearcher.
Synergetic Event Understanding: A Collaborative Approach to Cross-Document Event Coreference Resolution with Large Language Models
Jun 04, 2024Cross-document event coreference resolution (CDECR) involves clustering event mentions across multiple documents that refer to the same real-world events. Existing approaches utilize fine-tuning of small language models (SLMs) like BERT to address the compatibility among the contexts of event mentions. However, due to the complexity and diversity of contexts, these models are prone to learning simple co-occurrences. Recently, large language models (LLMs) like ChatGPT have demonstrated impressive contextual understanding, yet they encounter challenges in adapting to specific information extraction (IE) tasks. In this paper, we propose a collaborative approach for CDECR, leveraging the capabilities of both a universally capable LLM and a task-specific SLM. The collaborative strategy begins with the LLM accurately and comprehensively summarizing events through prompting. Then, the SLM refines its learning of event representations based on these insights during fine-tuning. Experimental results demonstrate that our approach surpasses the performance of both the large and small language models individually, forming a complementary advantage. Across various datasets, our approach achieves state-of-the-art performance, underscoring its effectiveness in diverse scenarios.
A Rationale-centric Counterfactual Data Augmentation Method for Cross-Document Event Coreference Resolution
Apr 02, 2024



Based on Pre-trained Language Models (PLMs), event coreference resolution (ECR) systems have demonstrated outstanding performance in clustering coreferential events across documents. However, the existing system exhibits an excessive reliance on the `triggers lexical matching' spurious pattern in the input mention pair text. We formalize the decision-making process of the baseline ECR system using a Structural Causal Model (SCM), aiming to identify spurious and causal associations (i.e., rationales) within the ECR task. Leveraging the debiasing capability of counterfactual data augmentation, we develop a rationale-centric counterfactual data augmentation method with LLM-in-the-loop. This method is specialized for pairwise input in the ECR system, where we conduct direct interventions on triggers and context to mitigate the spurious association while emphasizing the causation. Our approach achieves state-of-the-art performance on three popular cross-document ECR benchmarks and demonstrates robustness in out-of-domain scenarios.
Dialogue State Induction Using Neural Latent Variable Models
Aug 13, 2020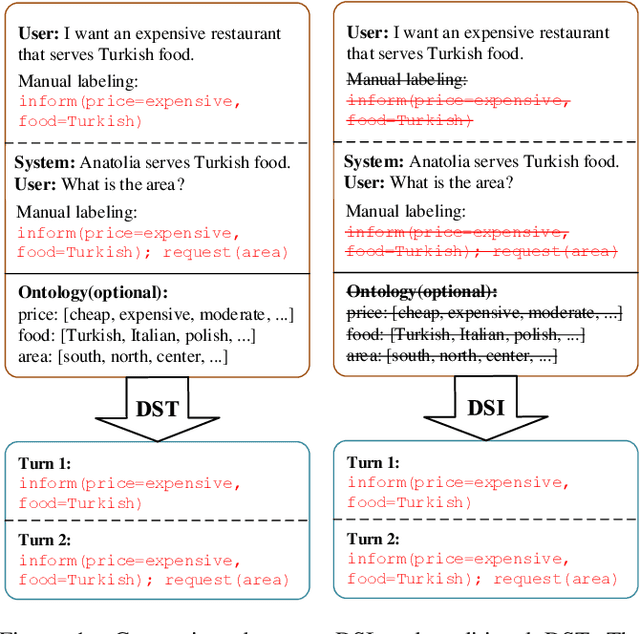


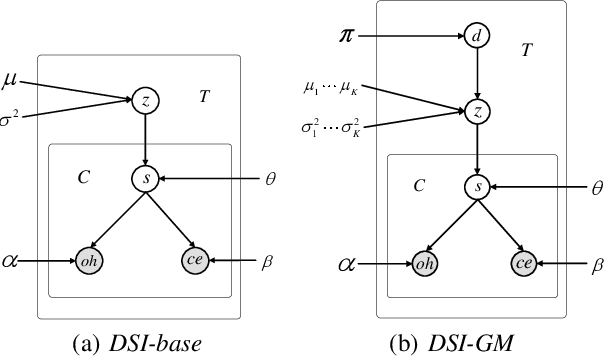
Dialogue state modules are a useful component in a task-oriented dialogue system. Traditional methods find dialogue states by manually labeling training corpora, upon which neural models are trained. However, the labeling process can be costly, slow, error-prone, and more importantly, cannot cover the vast range of domains in real-world dialogues for customer service. We propose the task of dialogue state induction, building two neural latent variable models that mine dialogue states automatically from unlabeled customer service dialogue records. Results show that the models can effectively find meaningful slots. In addition, equipped with induced dialogue states, a state-of-the-art dialogue system gives better performance compared with not using a dialogue state module.
A Pilot Study for Chinese SQL Semantic Parsing
Oct 16, 2019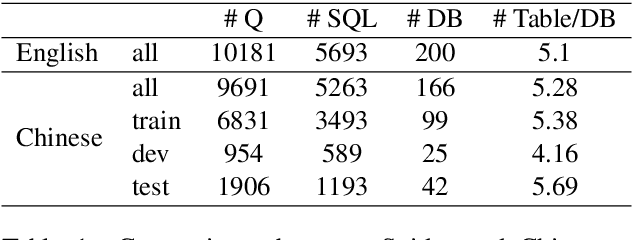
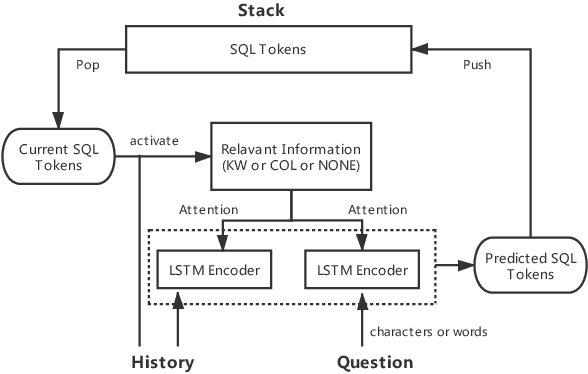

The task of semantic parsing is highly useful for dialogue and question answering systems. Many datasets have been proposed to map natural language text into SQL, among which the recent Spider dataset provides cross-domain samples with multiple tables and complex queries. We build a Spider dataset for Chinese, which is currently a low-resource language in this task area. Interesting research questions arise from the uniqueness of the language, which requires word segmentation, and also from the fact that SQL keywords and columns of DB tables are typically written in English. We compare character- and word-based encoders for a semantic parser, and different embedding schemes. Results show that word-based semantic parser is subject to segmentation errors and cross-lingual word embeddings are useful for text-to-SQL.