 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Preference Distribution Learning
Mar 17, 2026Decision-making problems often feature uncertainty stemming from heterogeneous and context-dependent human preferences. To address this, we propose a sequential learning-and-optimization pipeline to learn preference distributions and leverage them to solve downstream problems, for example risk-averse formulations. We focus on human choice settings that can be formulated as (integer) linear programs. In such settings, existing inverse optimization and choice modelling methods infer preferences from observed choices but typically produce point estimates or fail to capture contextual shifts, making them unsuitable for risk-averse decision-making. Using a bounded-variance score function gradient estimator, we train a predictive model mapping contextual features to a rich class of parameterizable distributions. This approach yields a maximum likelihood estimate. The model generates scenarios for unseen contexts in the subsequent optimization phase. In a synthetic ridesharing environment, our approach reduces average post-decision surprise by up to 114$\times$ compared to a risk-neutral approach with perfect predictions and up to 25$\times$ compared to leading risk-averse baselines.
Graph Neural Network Guided Local Search for the Traveling Salesperson Problem
Oct 12, 2021
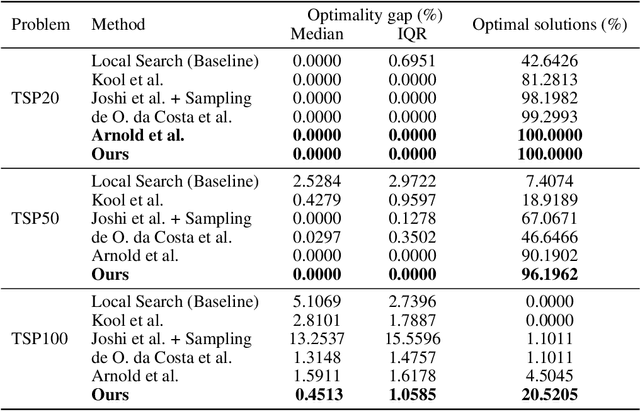

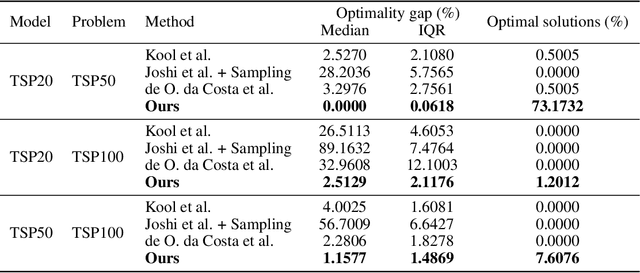
Solutions to the Traveling Salesperson Problem (TSP) have practical applications to processes in transportation, logistics, and automation, yet must be computed with minimal delay to satisfy the real-time nature of the underlying tasks. However, solving large TSP instances quickly without sacrificing solution quality remains challenging for current approximate algorithms. To close this gap, we present a hybrid data-driven approach for solving the TSP based on Graph Neural Networks (GNNs) and Guided Local Search (GLS). Our model predicts the regret of including each edge of the problem graph in the solution; GLS uses these predictions in conjunction with the original problem graph to find solutions. Our experiments demonstrate that this approach converges to optimal solutions at a faster rate than state-of-the-art learning-based approaches and non-learning GLS algorithms for the TSP, notably finding optimal solutions to 96% of the 50-node problem set, 7% more than the next best benchmark, and to 20% of the 100-node problem set, 4.5x more than the next best benchmark. When generalizing from 20-node problems to the 100-node problem set, our approach finds solutions with an average optimality gap of 2.5%, a 10x improvement over the next best learning-based benchmark.