 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockchain-Empowered Trustworthy Data Sharing: Fundamentals, Applications, and Challenges
Mar 12, 2023



Various data-sharing platforms have emerged with the growing public demand for open data and legislation mandating certain data to remain open. Most of these platforms remain opaque, leading to many questions about data accuracy, provenance and lineage, privacy implications, consent management, and the lack of fair incentives for data providers. With their transparency, immutability, non-repudiation, and decentralization properties, blockchains could not be more apt to answer these questions and enhance trust in a data-sharing platform. However, blockchains are not good at handling the four Vs of big data (i.e., volume, variety, velocity, and veracity) due to their limited performance, scalability, and high cost. Given many related works proposes blockchain-based trustworthy data-sharing solutions, there is increasing confusion and difficulties in understanding and selecting these technologies and platforms in terms of their sharing mechanisms, sharing services, quality of services, and applications. In this paper, we conduct a comprehensive survey on blockchain-based data-sharing architectures and applications to fill the gap. First, we present the foundations of blockchains and discuss the challenges of current data-sharing techniques. Second, we focus on the convergence of blockchain and data sharing to give a clear picture of this landscape and propose a reference architecture for blockchain-based data sharing. Third, we discuss the industrial applications of blockchain-based data sharing, ranging from healthcare and smart grid to transportation and decarbonization. For each application, we provide lessons learned for the deployment of Blockchain-based data sharing. Finally, we discuss research challenges and open research directions.
IronForge: An Open, Secure, Fair, Decentralized Federated Learning
Jan 07, 2023Federated learning (FL) provides an effective machine learning (ML) architecture to protect data privacy in a distributed manner. However, the inevitable network asynchrony, the over-dependence on a central coordinator, and the lack of an open and fair incentive mechanism collectively hinder its further development. We propose \textsc{IronForge}, a new generation of FL framework, that features a Directed Acyclic Graph (DAG)-based data structure and eliminates the need for central coordinators to achieve fully decentralized operations. \textsc{IronForge} runs in a public and open network, and launches a fair incentive mechanism by enabling state consistency in the DAG, so that the system fits in networks where training resources are unevenly distributed. In addition, dedicated defense strategies against prevalent FL attacks on incentive fairness and data privacy are presented to ensure the security of \textsc{IronForge}. Experimental results based on a newly developed testbed FLSim highlight the superiority of \textsc{IronForge} to the existing prevalent FL frameworks under various specifications in performance, fairness, and security. To the best of our knowledge, \textsc{IronForge} is the first secure and fully decentralized FL framework that can be applied in open networks with realistic network and training settings.
One-Shot Domain Adaptive and Generalizable Semantic Segmentation with Class-Aware Cross-Domain Transformers
Dec 14, 2022Unsupervised sim-to-real domain adaptation (UDA) for semantic segmentation aims to improve the real-world test performance of a model trained on simulated data. It can save the cost of manually labeling data in real-world applications such as robot vision and autonomous driving. Traditional UDA often assumes that there are abundant unlabeled real-world data samples available during training for the adaptation. However, such an assumption does not always hold in practice owing to the collection difficulty and the scarcity of the data. Thus, we aim to relieve this need on a large number of real data, and explore the one-shot unsupervised sim-to-real domain adaptation (OSUDA) and generalization (OSDG) problem, where only one real-world data sample is available. To remedy the limited real data knowledge, we first construct the pseudo-target domain by stylizing the simulated data with the one-shot real data. To mitigate the sim-to-real domain gap on both the style and spatial structure level and facilitate the sim-to-real adaptation, we further propose to use class-aware cross-domain transformers with an intermediate domain randomization strategy to extract the domain-invariant knowledge, from both the simulated and pseudo-target data. We demonstrate the effectiveness of our approach for OSUDA and OSDG on different benchmarks, outperforming the state-of-the-art methods by a large margin, 10.87, 9.59, 13.05 and 15.91 mIoU on GTA, SYNTHIA$\rightarrow$Cityscapes, Foggy Cityscapes, respectively.
CiaoSR: Continuous Implicit Attention-in-Attention Network for Arbitrary-Scale Image Super-Resolution
Dec 08, 2022



Learning continuous image representations is recently gaining popularity for image super-resolution (SR) because of its ability to reconstruct high-resolution images with arbitrary scales from low-resolution inputs. Existing methods mostly ensemble nearby features to predict the new pixel at any queried coordinate in the SR image. Such a local ensemble suffers from some limitations: i) it has no learnable parameters and it neglects the similarity of the visual features; ii) it has a limited receptive field and cannot ensemble relevant features in a large field which are important in an image; iii) it inherently has a gap with real camera imaging since it only depends on the coordinate. To address these issues, this paper proposes a continuous implicit attention-in-attention network, called CiaoSR. We explicitly design an implicit attention network to learn the ensemble weights for the nearby local features. Furthermore, we embed a scale-aware attention in this implicit attention network to exploit additional non-local information. Extensive experiments on benchmark datasets demonstrate CiaoSR significantly outperforms the existing single image super resolution (SISR) methods with the same backbone. In addition, the proposed method also achieves the state-of-the-art performance on the arbitrary-scale SR task. The effectiveness of the method is also demonstrated on the real-world SR setting. More importantly, CiaoSR can be flexibly integrated into any backbone to improve the SR performance.
Superresolution Reconstruction of Single Image for Latent features
Nov 25, 2022



In recent years, Deep Learning has shown good results in the Single Image Superresolution Reconstruction (SISR) task, thus becoming the most widely used methods in this field. The SISR task is a typical task to solve an uncertainty problem. Therefore, it is often challenging to meet the requirements of High-quality sampling, fast Sampling, and diversity of details and texture after Sampling simultaneously in a SISR task.It leads to model collapse, lack of details and texture features after Sampling, and too long Sampling time in High Resolution (HR) image reconstruction methods. This paper proposes a Diffusion Probability model for Latent features (LDDPM) to solve these problems. Firstly, a Conditional Encoder is designed to effectively encode Low-Resolution (LR) images, thereby reducing the solution space of reconstructed images to improve the performance of reconstructed images. Then, the Normalized Flow and Multi-modal adversarial training are used to model the denoising distribution with complex Multi-modal distribution so that the Generative Modeling ability of the model can be improved with a small number of Sampling steps. Experimental results on mainstream datasets demonstrate that our proposed model reconstructs more realistic HR images and obtains better PSNR and SSIM performance compared to existing SISR tasks, thus providing a new idea for SISR tasks.
HAT: Head-Worn Assistive Teleoperation of Mobile Manipulators
Sep 27, 2022Mobile manipulators in the home can provide increased autonomy to individuals with severe motor impairments, who often cannot complete activities of daily living (ADLs) without the help of a caregiver. Teleoperation of an assistive mobile manipulator could enable an individual with motor impairments to independently perform self-care and household tasks, yet limited motor function can impede one's ability to interface with a robot. In this work, we present a unique inertial-based wearable assistive interface, embedded in a familiar head-worn garment, for individuals with severe motor impairments to teleoperate and perform physical tasks with a mobile manipulator. We evaluate this wearable interface with both able-bodied (N = 16) and individuals with motor impairments (N = 2) for performing ADLs and everyday household tasks. Our results show that the wearable interface enabled participants to complete physical tasks with low error rates, high perceived ease of use, and low workload measures. Overall, this inertial-based wearable serves as a new assistive interface option for control of mobile manipulators in the home.
Domain Shift-oriented Machine Anomalous Sound Detection Model Based on Self-Supervised Learning
Aug 31, 2022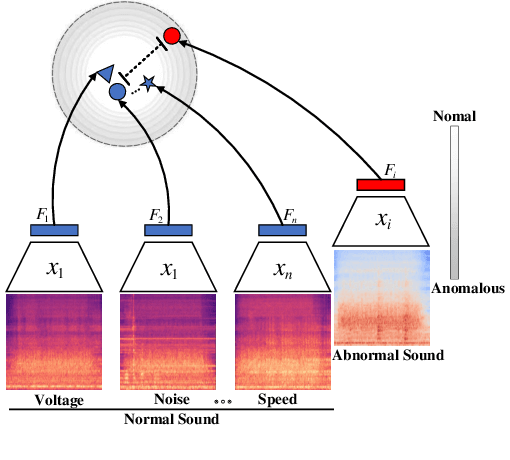
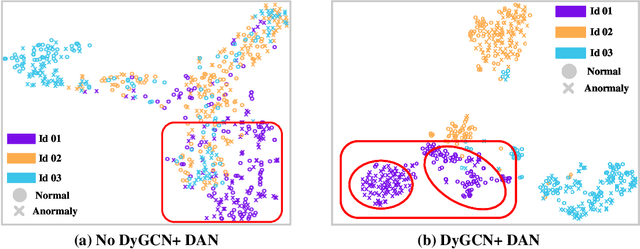
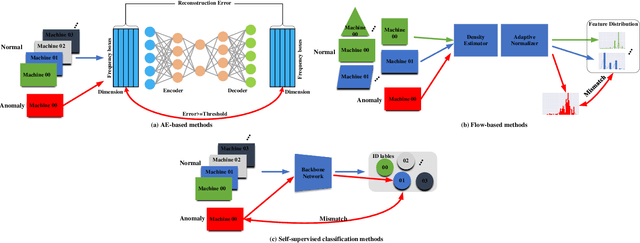
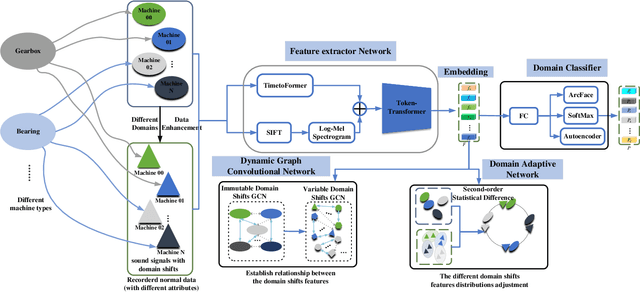
Thanks to the development of deep learning, research on machine anomalous sound detection based on self-supervised learning has made remarkable achievements. However, there are differences in the acoustic characteristics of the test set and the training set under different operating conditions of the same machine (domain shifts). It is challenging for the existing detection methods to learn the domain shifts features stably with low computation overhead. To address these problems, we propose a domain shift-oriented machine anomalous sound detection model based on self-supervised learning (TranSelf-DyGCN) in this paper. Firstly, we design a time-frequency domain feature modeling network to capture global and local spatial and time-domain features, thus improving the stability of machine anomalous sound detection stability under domain shifts. Then, we adopt a Dynamic Graph Convolutional Network (DyGCN) to model the inter-dependence relationship between domain shifts features, enabling the model to perceive domain shifts features efficiently. Finally, we use a Domain Adaptive Network (DAN) to compensate for the performance decrease caused by domain shifts, making the model adapt to anomalous sound better in the self-supervised environment. The performance of the suggested model is validated on DCASE 2020 task 2 and DCASE 2022 task 2.
Practical Real Video Denoising with Realistic Degradation Model
Aug 25, 2022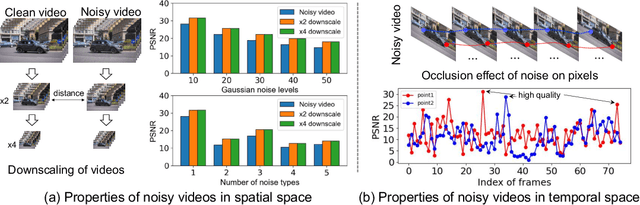
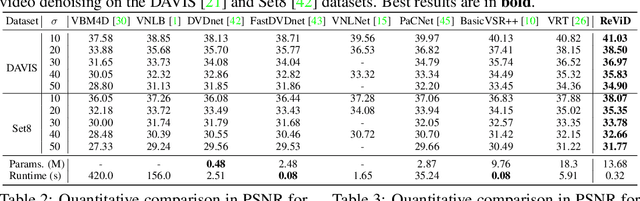
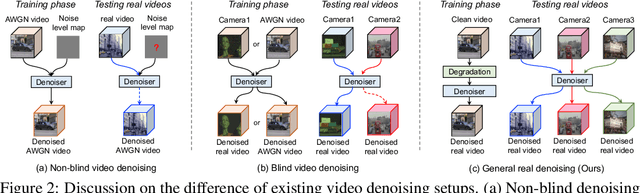
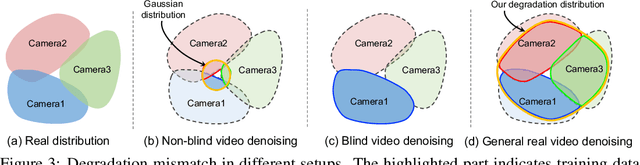
Existing video denoising methods typically assume noisy videos are degraded from clean videos by adding Gaussian noise. However, deep models trained on such a degradation assumption will inevitably give rise to poor performance for real videos due to degradation mismatch. Although some studies attempt to train deep models on noisy and noise-free video pairs captured by cameras, such models can only work well for specific cameras and do not generalize well for other videos. In this paper, we propose to lift this limitation and focus on the problem of general real video denoising with the aim to generalize well on unseen real-world videos. We tackle this problem by firstly investigating the common behaviors of video noises and observing two important characteristics: 1) downscaling helps to reduce the noise level in spatial space and 2) the information from the adjacent frames help to remove the noise of current frame in temporal space. Motivated by these two observations, we propose a multi-scale recurrent architecture by making full use of the above two characteristics. Secondly, we propose a synthetic real noise degradation model by randomly shuffling different noise types to train the denoising model. With a synthesized and enriched degradation space, our degradation model can help to bridge the distribution gap between training data and real-world data. Extensive experiments demonstrate that our proposed method achieves the state-of-the-art performance and better generalization ability than existing methods on both synthetic Gaussian denoising and practical real video denoising.
Towards Interpretable Video Super-Resolution via Alternating Optimization
Jul 21, 2022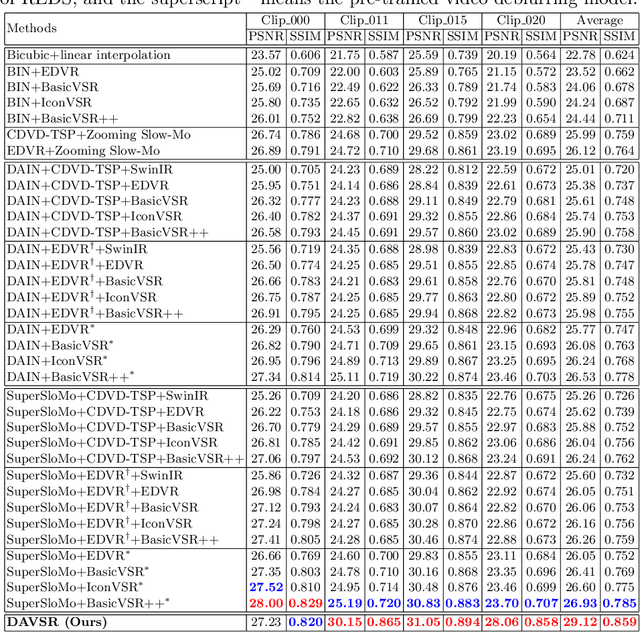
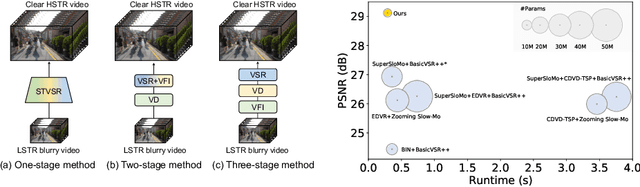
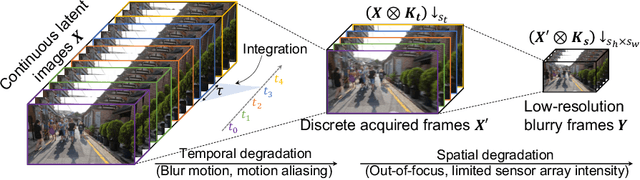
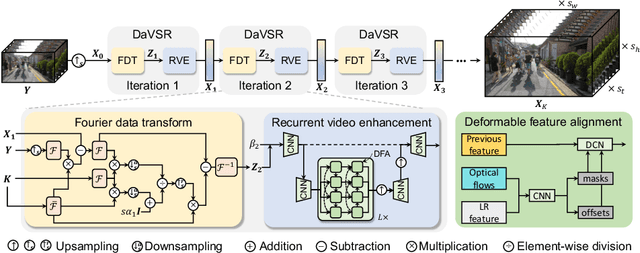
In this paper, we study a practical space-time video super-resolution (STVSR) problem which aims at generating a high-framerate high-resolution sharp video from a low-framerate low-resolution blurry video. Such problem often occurs when recording a fast dynamic event with a low-framerate and low-resolution camera, and the captured video would suffer from three typical issues: i) motion blur occurs due to object/camera motions during exposure time; ii) motion aliasing is unavoidable when the event temporal frequency exceeds the Nyquist limit of temporal sampling; iii) high-frequency details are lost because of the low spatial sampling rate. These issues can be alleviated by a cascade of three separate sub-tasks, including video deblurring, frame interpolation, and super-resolution, which, however, would fail to capture the spatial and temporal correlations among video sequences. To address this, we propose an interpretable STVSR framework by leveraging both model-based and learning-based methods. Specifically, we formulate STVSR as a joint video deblurring, frame interpolation, and super-resolution problem, and solve it as two sub-problems in an alternate way. For the first sub-problem, we derive an interpretable analytical solution and use it as a Fourier data transform layer. Then, we propose a recurrent video enhancement layer for the second sub-problem to further recover high-frequency details. Extensive experiments demonstrate the superiority of our method in terms of quantitative metrics and visual quality.
Multi-agent Actor-Critic with Time Dynamical Opponent Model
Apr 12, 2022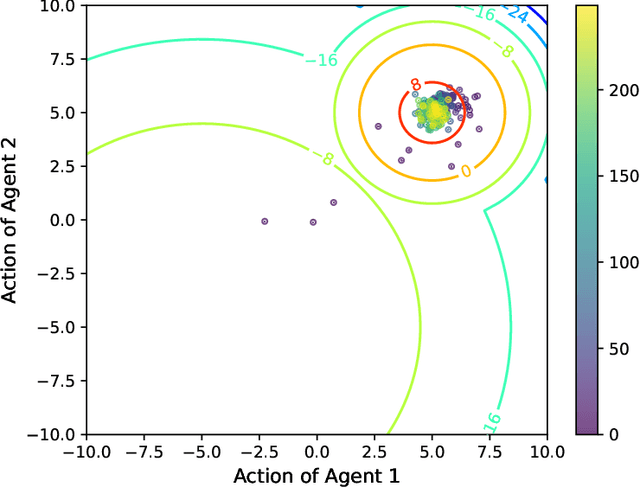

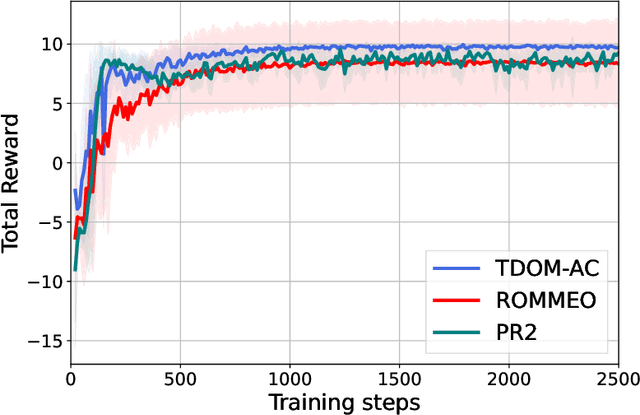

In multi-agent reinforcement learning, multiple agents learn simultaneously while interacting with a common environment and each other. Since the agents adapt their policies during learning, not only the behavior of a single agent becomes non-stationary, but also the environment as perceived by the agent. This renders it particularly challenging to perform policy improvement. In this paper, we propose to exploit the fact that the agents seek to improve their expected cumulative reward and introduce a novel \textit{Time Dynamical Opponent Model} (TDOM) to encode the knowledge that the opponent policies tend to improve over time. We motivate TDOM theoretically by deriving a lower bound of the log objective of an individual agent and further propose \textit{Multi-Agent Actor-Critic with Time Dynamical Opponent Model} (TDOM-AC). We evaluate the proposed TDOM-AC on a differential game and the Multi-agent Particle Environment. We show empirically that TDOM achieves superior opponent behavior prediction during test time. The proposed TDOM-AC methodology outperforms state-of-the-art Actor-Critic methods on the performed experiments in cooperative and \textbf{especially} in mixed cooperative-competitive environments. TDOM-AC results in a more stable training and a faster convergence.