 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Curse and Blessing of Mean Bias in FP4-Quantized LLM Training
Mar 11, 2026Large language models trained on natural language exhibit pronounced anisotropy: a small number of directions concentrate disproportionate energy, while the remaining dimensions form a broad semantic tail. In low-bit training regimes, this geometry becomes numerically unstable. Because blockwise quantization scales are determined by extreme elementwise magnitudes, dominant directions stretch the dynamic range, compressing long-tail semantic variation into narrow numerical bins. We show that this instability is primarily driven by a coherent rank-one mean bias, which constitutes the dominant component of spectral anisotropy in LLM representations. This mean component emerges systematically across layers and training stages and accounts for the majority of extreme activation magnitudes, making it the principal driver of dynamic-range inflation under low precision. Crucially, because the dominant instability is rank-one, it can be eliminated through a simple source-level mean-subtraction operation. This bias-centric conditioning recovers most of the stability benefits of SVD-based spectral methods while requiring only reduction operations and standard quantization kernels. Empirical results on FP4 (W4A4G4) training show that mean removal substantially narrows the loss gap to BF16 and restores downstream performance, providing a hardware-efficient path to stable low-bit LLM training.
Multi-Head Attention as a Source of Catastrophic Forgetting in MoE Transformers
Feb 13, 2026Mixture-of-Experts (MoE) architectures are often considered a natural fit for continual learning because sparse routing should localize updates and reduce interference, yet MoE Transformers still forget substantially even with sparse, well-balanced expert utilization. We attribute this gap to a pre-routing bottleneck: multi-head attention concatenates head-specific signals into a single post-attention router input, forcing routing to act on co-occurring feature compositions rather than separable head channels. We show that this router input simultaneously encodes multiple separately decodable semantic and structural factors with uneven head support, and that different feature compositions induce weakly aligned parameter-gradient directions; as a result, routing maps many distinct compositions to the same route. We quantify this collision effect via a route-wise effective composition number $N_{eff}$ and find that higher $N_{eff}$ is associated with larger old-task loss increases after continual training. Motivated by these findings, we propose MH-MoE, which performs head-wise routing over sub-representations to increase routing granularity and reduce composition collisions. On TRACE with Qwen3-0.6B/8B, MH-MoE effectively mitigates forgetting, reducing BWT on Qwen3-0.6B from 11.2% (LoRAMoE) to 4.5%.
SD-MoE: Spectral Decomposition for Effective Expert Specialization
Feb 13, 2026Mixture-of-Experts (MoE) architectures scale Large Language Models via expert specialization induced by conditional computation. In practice, however, expert specialization often fails: some experts become functionally similar, while others functioning as de facto shared experts, limiting the effective capacity and model performance. In this work, we analysis from a spectral perspective on parameter and gradient spaces, uncover that (1) experts share highly overlapping dominant spectral components in their parameters, (2) dominant gradient subspaces are strongly aligned across experts, driven by ubiquitous low-rank structure in human corpus, and (3) gating mechanisms preferentially route inputs along these dominant directions, further limiting specialization. To address this, we propose Spectral-Decoupled MoE (SD-MoE), which decomposes both parameter and gradient in the spectral space. SD-MoE improves performance across downstream tasks, enables effective expert specialization, incurring minimal additional computation, and can be seamlessly integrated into a wide range of existing MoE architectures, including Qwen and DeepSeek.
Train Faster, Perform Better: Modular Adaptive Training in Over-Parameterized Models
May 13, 2024



Despite their prevalence in deep-learning communities, over-parameterized models convey high demands of computational costs for proper training. This work studies the fine-grained, modular-level learning dynamics of over-parameterized models to attain a more efficient and fruitful training strategy. Empirical evidence reveals that when scaling down into network modules, such as heads in self-attention models, we can observe varying learning patterns implicitly associated with each module's trainability. To describe such modular-level learning capabilities, we introduce a novel concept dubbed modular neural tangent kernel (mNTK), and we demonstrate that the quality of a module's learning is tightly associated with its mNTK's principal eigenvalue $\lambda_{\max}$. A large $\lambda_{\max}$ indicates that the module learns features with better convergence, while those miniature ones may impact generalization negatively. Inspired by the discovery, we propose a novel training strategy termed Modular Adaptive Training (MAT) to update those modules with their $\lambda_{\max}$ exceeding a dynamic threshold selectively, concentrating the model on learning common features and ignoring those inconsistent ones. Unlike most existing training schemes with a complete BP cycle across all network modules, MAT can significantly save computations by its partially-updating strategy and can further improve performance. Experiments show that MAT nearly halves the computational cost of model training and outperforms the accuracy of baselines.
Hang-Time HAR: A Benchmark Dataset for Basketball Activity Recognition using Wrist-worn Inertial Sensors
May 22, 2023



We present a benchmark dataset for evaluating physical human activity recognition methods from wrist-worn sensors, for the specific setting of basketball training, drills, and games. Basketball activities lend themselves well for measurement by wrist-worn inertial sensors, and systems that are able to detect such sport-relevant activities could be used in applications toward game analysis, guided training, and personal physical activity tracking. The dataset was recorded for two teams from separate countries (USA and Germany) with a total of 24 players who wore an inertial sensor on their wrist, during both repetitive basketball training sessions and full games. Particular features of this dataset include an inherent variance through cultural differences in game rules and styles as the data was recorded in two countries, as well as different sport skill levels, since the participants were heterogeneous in terms of prior basketball experience. We illustrate the dataset's features in several time-series analyses and report on a baseline classification performance study with two state-of-the-art deep learning architectures.
Air Pollution Hotspot Detection and Source Feature Analysis using Cross-domain Urban Data
Nov 15, 2022



Air pollution is a major global environmental health threat, in particular for people who live or work near pollution sources. Areas adjacent to pollution sources often have high ambient pollution concentrations, and those areas are commonly referred to as air pollution hotspots. Detecting and characterizing pollution hotspots are of great importance for air quality management, but are challenging due to the high spatial and temporal variability of air pollutants. In this work, we explore the use of mobile sensing data (i.e., air quality sensors installed on vehicles) to detect pollution hotspots. One major challenge with mobile sensing data is uneven sampling, i.e., data collection can vary by both space and time. To address this challenge, we propose a two-step approach to detect hotspots from mobile sensing data, which includes local spike detection and sample-weighted clustering. Essentially, this approach tackles the uneven sampling issue by weighting samples based on their spatial frequency and temporal hit rate, so as to identify robust and persistent hotspots. To contextualize the hotspots and discover potential pollution source characteristics, we explore a variety of cross-domain urban data and extract features from them. As a soft-validation of the extracted features, we build hotspot inference models for cities with and without mobile sensing data. Evaluation results using real-world mobile sensing air quality data as well as cross-domain urban data demonstrate the effectiveness of our approach in detecting and inferring pollution hotspots. Furthermore, the empirical analysis of hotspots and source features yields useful insights regarding neighborhood pollution sources.
* 10 pages
Do Smart Glasses Dream of Sentimental Visions? Deep Emotionship Analysis for Eyewear Devices
Jan 24, 2022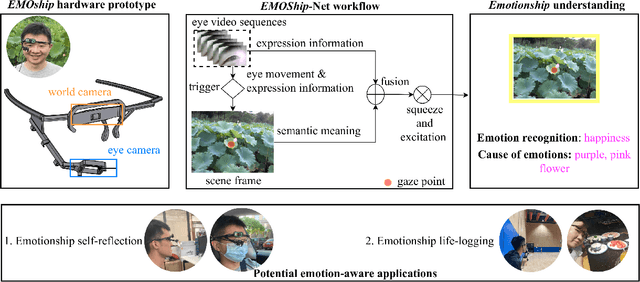

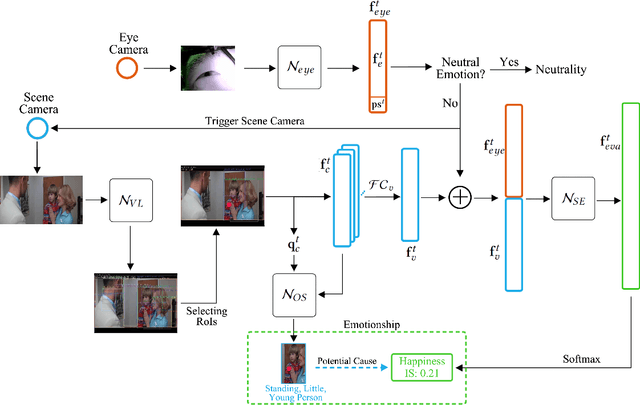
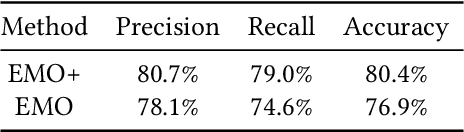
Emotion recognition in smart eyewear devices is highly valuable but challenging. One key limitation of previous works is that the expression-related information like facial or eye images is considered as the only emotional evidence. However, emotional status is not isolated; it is tightly associated with people's visual perceptions, especially those sentimental ones. However, little work has examined such associations to better illustrate the cause of different emotions. In this paper, we study the emotionship analysis problem in eyewear systems, an ambitious task that requires not only classifying the user's emotions but also semantically understanding the potential cause of such emotions. To this end, we devise EMOShip, a deep-learning-based eyewear system that can automatically detect the wearer's emotional status and simultaneously analyze its associations with semantic-level visual perceptions. Experimental studies with 20 participants demonstrate that, thanks to the emotionship awareness, EMOShip not only achieves superior emotion recognition accuracy over existing methods (80.2% vs. 69.4%), but also provides a valuable understanding of the cause of emotions. Pilot studies with 20 participants further motivate the potential use of EMOShip to empower emotion-aware applications, such as emotionship self-reflection and emotionship life-logging.
MemX: An Attention-Aware Smart Eyewear System for Personalized Moment Auto-capture
May 03, 2021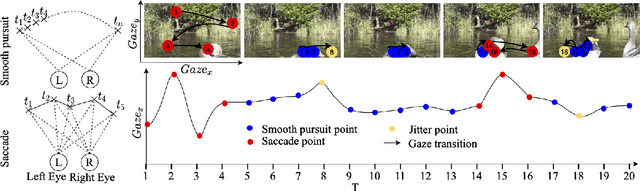

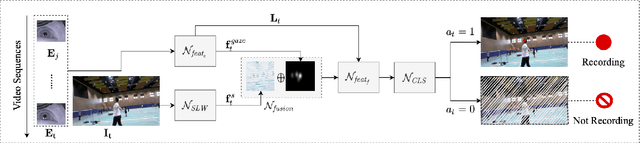
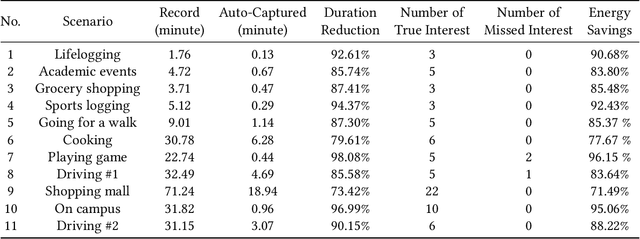
This work presents MemX: a biologically-inspired attention-aware eyewear system developed with the goal of pursuing the long-awaited vision of a personalized visual Memex. MemX captures human visual attention on the fly, analyzes the salient visual content, and records moments of personal interest in the form of compact video snippets. Accurate attentive scene detection and analysis on resource-constrained platforms is challenging because these tasks are computation and energy intensive. We propose a new temporal visual attention network that unifies human visual attention tracking and salient visual content analysis. Attention tracking focuses computation-intensive video analysis on salient regions, while video analysis makes human attention detection and tracking more accurate. Using the YouTube-VIS dataset and 30 participants, we experimentally show that MemX significantly improves the attention tracking accuracy over the eye-tracking-alone method, while maintaining high system energy efficiency. We have also conducted 11 in-field pilot studies across a range of daily usage scenarios, which demonstrate the feasibility and potential benefits of MemX.
A Reinforcement-Learning-Based Energy-Efficient Framework for Multi-Task Video Analytics Pipeline
May 02, 2021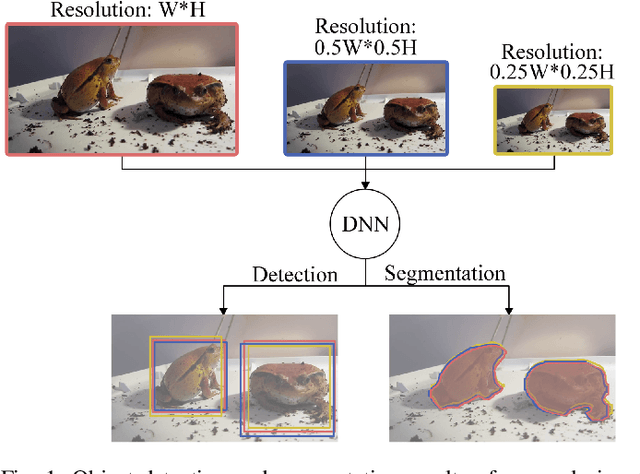
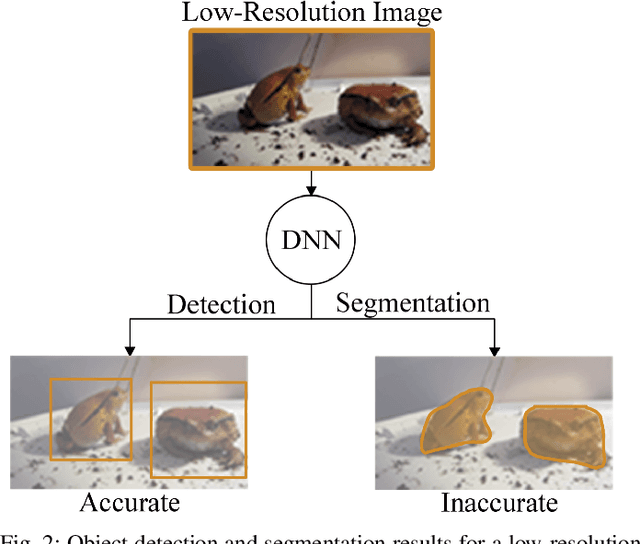
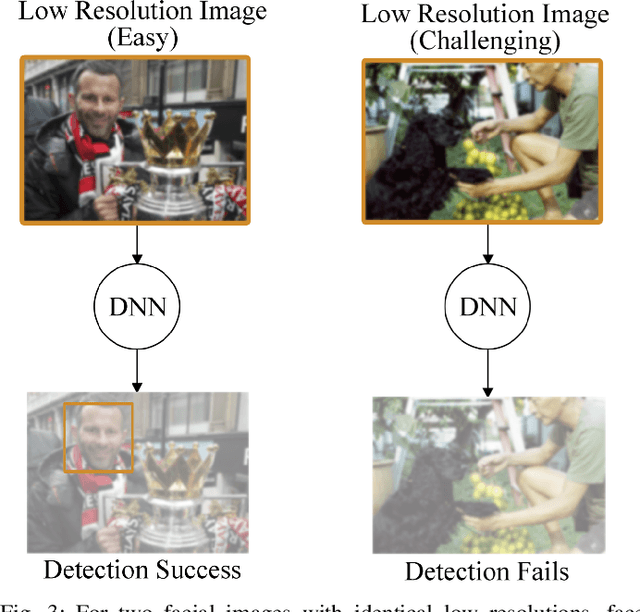
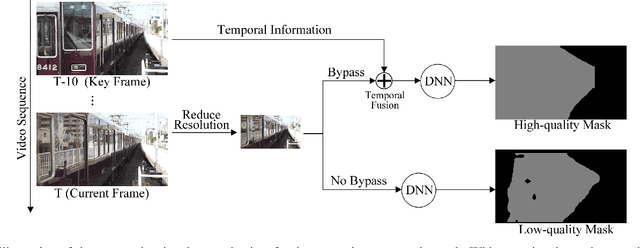
Deep-learning-based video processing has yielded transformative results in recent years. However, the video analytics pipeline is energy-intensive due to high data rates and reliance on complex inference algorithms, which limits its adoption in energy-constrained applications. Motivated by the observation of high and variable spatial redundancy and temporal dynamics in video data streams, we design and evaluate an adaptive-resolution optimization framework to minimize the energy use of multi-task video analytics pipelines. Instead of heuristically tuning the input data resolution of individual tasks, our framework utilizes deep reinforcement learning to dynamically govern the input resolution and computation of the entire video analytics pipeline. By monitoring the impact of varying resolution on the quality of high-dimensional video analytics features, hence the accuracy of video analytics results, the proposed end-to-end optimization framework learns the best non-myopic policy for dynamically controlling the resolution of input video streams to globally optimize energy efficiency. Governed by reinforcement learning, optical flow is incorporated into the framework to minimize unnecessary spatio-temporal redundancy that leads to re-computation, while preserving accuracy. The proposed framework is applied to video instance segmentation which is one of the most challenging computer vision tasks, and achieves better energy efficiency than all baseline methods of similar accuracy on the YouTube-VIS dataset.
Collaborative Filtering with Stability
Nov 06, 2018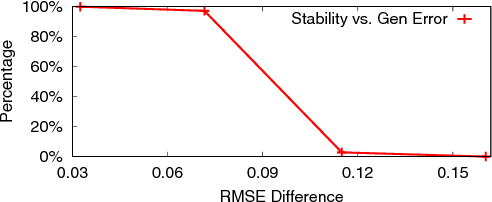
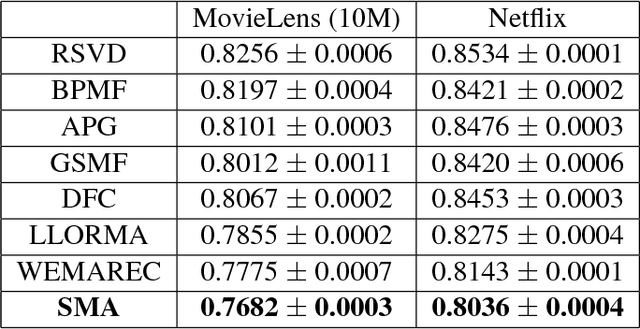
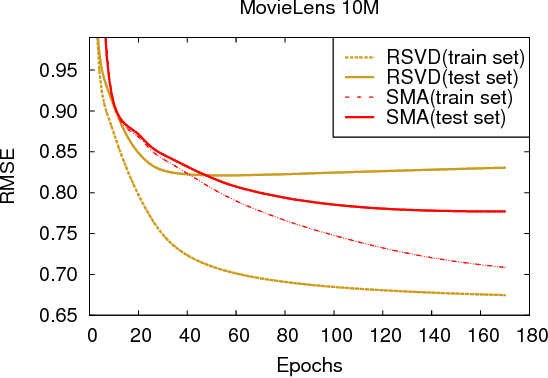
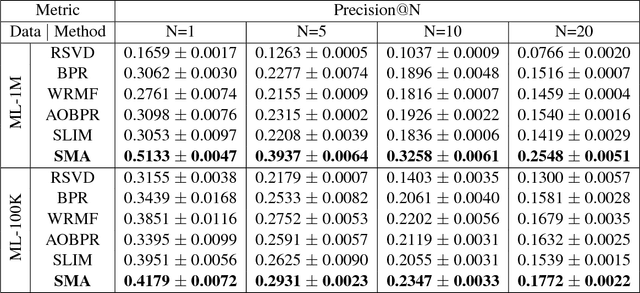
Collaborative filtering (CF) is a popular technique in today's recommender systems, and matrix approximation-based CF methods have achieved great success in both rating prediction and top-N recommendation tasks. However, real-world user-item rating matrices are typically sparse, incomplete and noisy, which introduce challenges to the algorithm stability of matrix approximation, i.e., small changes in the training data may significantly change the models. As a result, existing matrix approximation solutions yield low generalization performance, exhibiting high error variance on the training data, and minimizing the training error may not guarantee error reduction on the test data. This paper investigates the algorithm stability problem of matrix approximation methods and how to achieve stable collaborative filtering via stable matrix approximation. We present a new algorithm design framework, which (1) introduces new optimization objectives to guide stable matrix approximation algorithm design, and (2) solves the optimization problem to obtain stable approximation solutions with good generalization performance. Experimental results on real-world datasets demonstrate that the proposed method can achieve better accuracy compared with state-of-the-art matrix approximation methods and ensemble methods in both rating prediction and top-N recommendation tasks.