 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuSE: A Neural Snapshot Ensemble Method for Collaborative Filtering
Apr 15, 2021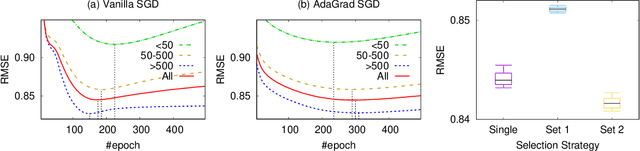

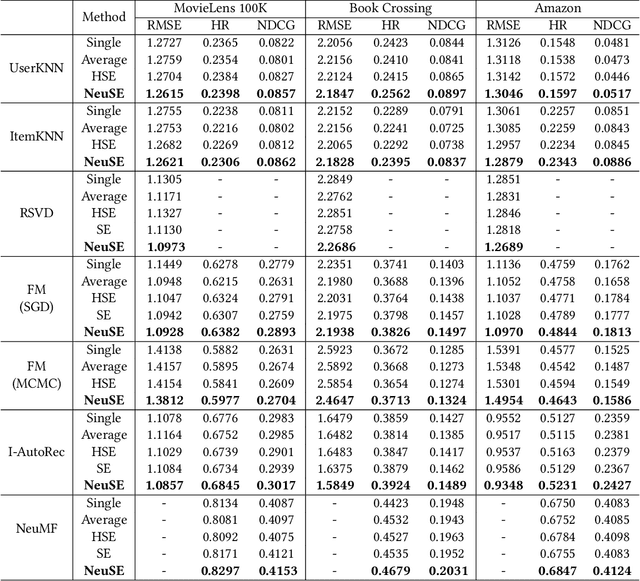
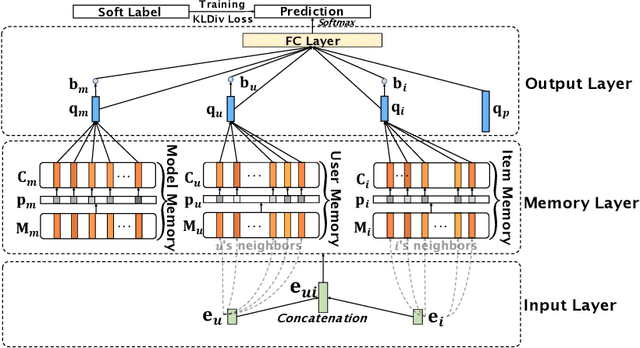
In collaborative filtering (CF) algorithms, the optimal models are usually learned by globally minimizing the empirical risks averaged over all the observed data. However, the global models are often obtained via a performance tradeoff among users/items, i.e., not all users/items are perfectly fitted by the global models due to the hard non-convex optimization problems in CF algorithms. Ensemble learning can address this issue by learning multiple diverse models but usually suffer from efficiency issue on large datasets or complex algorithms. In this paper, we keep the intermediate models obtained during global model learning as the snapshot models, and then adaptively combine the snapshot models for individual user-item pairs using a memory network-based method. Empirical studies on three real-world datasets show that the proposed method can extensively and significantly improve the accuracy (up to 15.9% relatively) when applied to a variety of existing collaborative filtering methods.
Collaborative Filtering with Stability
Nov 06, 2018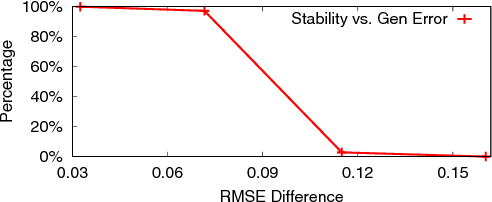
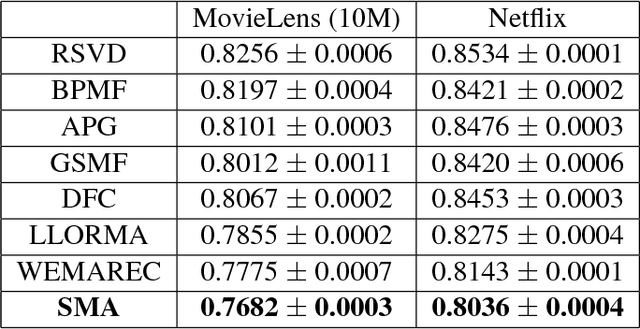
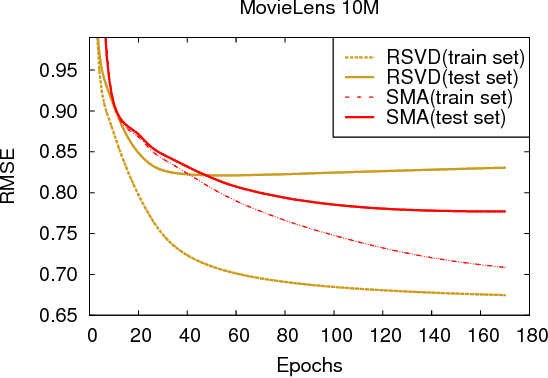
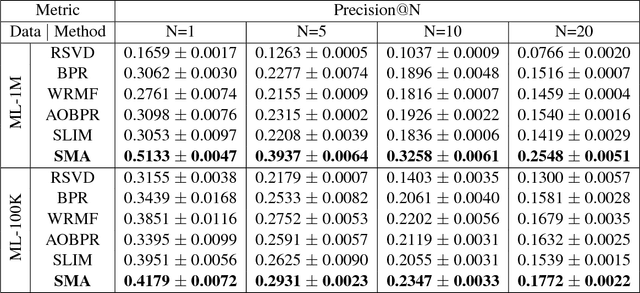
Collaborative filtering (CF) is a popular technique in today's recommender systems, and matrix approximation-based CF methods have achieved great success in both rating prediction and top-N recommendation tasks. However, real-world user-item rating matrices are typically sparse, incomplete and noisy, which introduce challenges to the algorithm stability of matrix approximation, i.e., small changes in the training data may significantly change the models. As a result, existing matrix approximation solutions yield low generalization performance, exhibiting high error variance on the training data, and minimizing the training error may not guarantee error reduction on the test data. This paper investigates the algorithm stability problem of matrix approximation methods and how to achieve stable collaborative filtering via stable matrix approximation. We present a new algorithm design framework, which (1) introduces new optimization objectives to guide stable matrix approximation algorithm design, and (2) solves the optimization problem to obtain stable approximation solutions with good generalization performance. Experimental results on real-world datasets demonstrate that the proposed method can achieve better accuracy compared with state-of-the-art matrix approximation methods and ensemble methods in both rating prediction and top-N recommendation tasks.
Modeling The Intensity Function Of Point Process Via Recurrent Neural Networks
May 24, 2017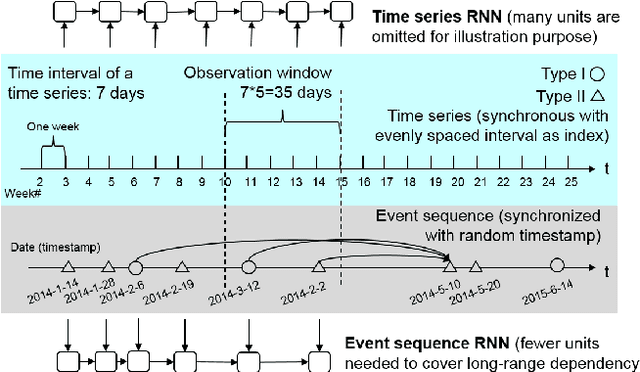

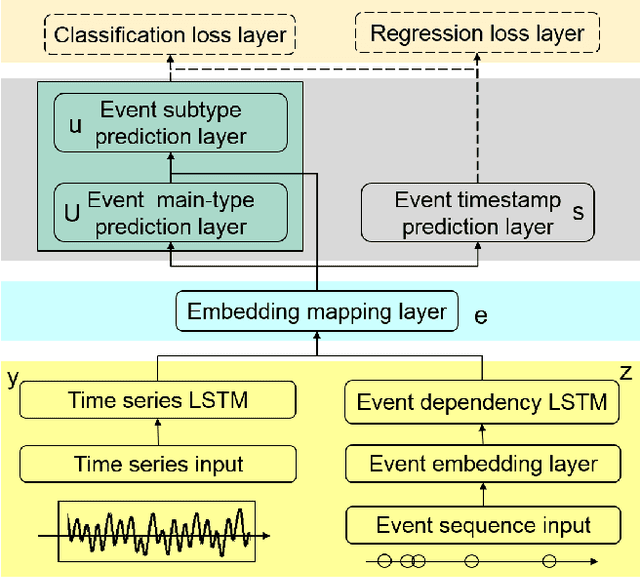
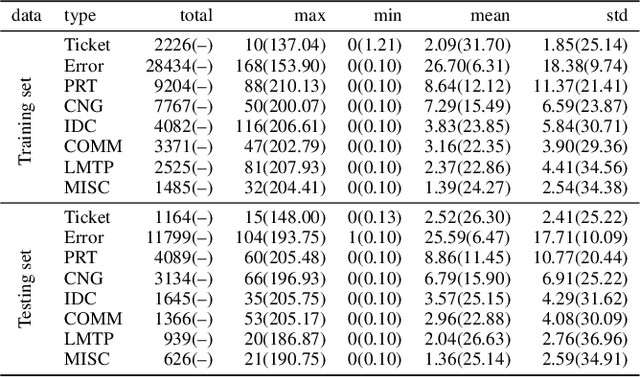
Event sequence, asynchronously generated with random timestamp, is ubiquitous among applications. The precise and arbitrary timestamp can carry important clues about the underlying dynamics, and has lent the event data fundamentally different from the time-series whereby series is indexed with fixed and equal time interval. One expressive mathematical tool for modeling event is point process. The intensity functions of many point processes involve two components: the background and the effect by the history. Due to its inherent spontaneousness, the background can be treated as a time series while the other need to handle the history events. In this paper, we model the background by a Recurrent Neural Network (RNN) with its units aligned with time series indexes while the history effect is modeled by another RNN whose units are aligned with asynchronous events to capture the long-range dynamics. The whole model with event type and timestamp prediction output layers can be trained end-to-end. Our approach takes an RNN perspective to point process, and models its background and history effect. For utility, our method allows a black-box treatment for modeling the intensity which is often a pre-defined parametric form in point processes. Meanwhile end-to-end training opens the venue for reusing existing rich techniques in deep network for point process modeling. We apply our model to the predictive maintenance problem using a log dataset by more than 1000 ATMs from a global bank headquartered in North America.