 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Predictive Analysis: How Far Are They?
May 22, 2025Predictive analysis is a cornerstone of modern decision-making, with applications in various domains. Large Language Models (LLMs) have emerged as powerful tools in enabling nuanced, knowledge-intensive conversations, thus aiding in complex decision-making tasks. With the burgeoning expectation to harness LLMs for predictive analysis, there is an urgent need to systematically assess their capability in this domain. However, there is a lack of relevant evaluations in existing studies. To bridge this gap, we introduce the \textbf{PredictiQ} benchmark, which integrates 1130 sophisticated predictive analysis queries originating from 44 real-world datasets of 8 diverse fields. We design an evaluation protocol considering text analysis, code generation, and their alignment. Twelve renowned LLMs are evaluated, offering insights into their practical use in predictive analysis. Generally, we believe that existing LLMs still face considerable challenges in conducting predictive analysis. See \href{https://github.com/Cqkkkkkk/PredictiQ}{Github}.
Reinforced Interactive Continual Learning via Real-time Noisy Human Feedback
May 15, 2025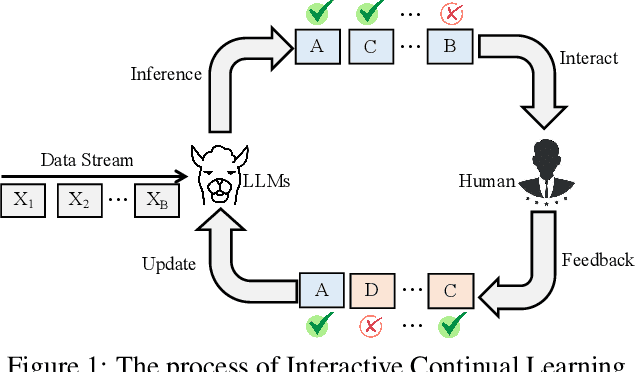
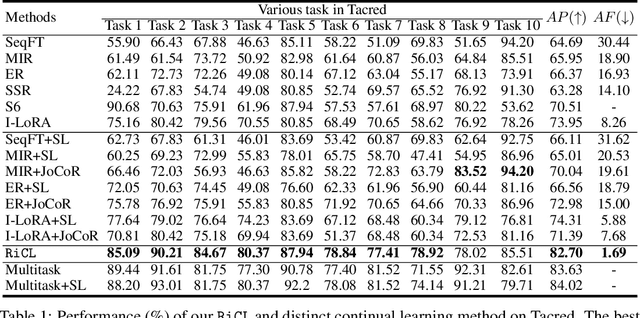
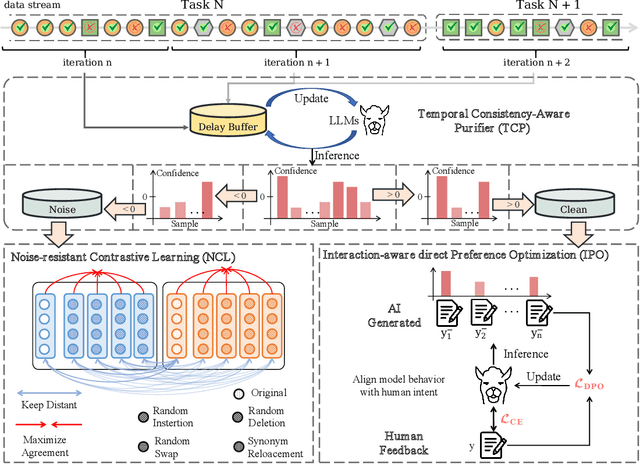

This paper introduces an interactive continual learning paradigm where AI models dynamically learn new skills from real-time human feedback while retaining prior knowledge. This paradigm distinctively addresses two major limitations of traditional continual learning: (1) dynamic model updates using streaming, real-time human-annotated data, rather than static datasets with fixed labels, and (2) the assumption of clean labels, by explicitly handling the noisy feedback common in real-world interactions. To tackle these problems, we propose RiCL, a Reinforced interactive Continual Learning framework leveraging Large Language Models (LLMs) to learn new skills effectively from dynamic feedback. RiCL incorporates three key components: a temporal consistency-aware purifier to automatically discern clean from noisy samples in data streams; an interaction-aware direct preference optimization strategy to align model behavior with human intent by reconciling AI-generated and human-provided feedback; and a noise-resistant contrastive learning module that captures robust representations by exploiting inherent data relationships, thus avoiding reliance on potentially unreliable labels. Extensive experiments on two benchmark datasets (FewRel and TACRED), contaminated with realistic noise patterns, demonstrate that our RiCL approach substantially outperforms existing combinations of state-of-the-art online continual learning and noisy-label learning methods.
Task-Core Memory Management and Consolidation for Long-term Continual Learning
May 15, 2025



In this paper, we focus on a long-term continual learning (CL) task, where a model learns sequentially from a stream of vast tasks over time, acquiring new knowledge while retaining previously learned information in a manner akin to human learning. Unlike traditional CL settings, long-term CL involves handling a significantly larger number of tasks, which exacerbates the issue of catastrophic forgetting. Our work seeks to address two critical questions: 1) How do existing CL methods perform in the context of long-term CL? and 2) How can we mitigate the catastrophic forgetting that arises from prolonged sequential updates? To tackle these challenges, we propose a novel framework inspired by human memory mechanisms for long-term continual learning (Long-CL). Specifically, we introduce a task-core memory management strategy to efficiently index crucial memories and adaptively update them as learning progresses. Additionally, we develop a long-term memory consolidation mechanism that selectively retains hard and discriminative samples, ensuring robust knowledge retention. To facilitate research in this area, we construct and release two multi-modal and textual benchmarks, MMLongCL-Bench and TextLongCL-Bench, providing a valuable resource for evaluating long-term CL approaches. Experimental results show that Long-CL outperforms the previous state-of-the-art by 7.4\% and 6.5\% AP on the two benchmarks, respectively, demonstrating the effectiveness of our approach.
A Survey of Slow Thinking-based Reasoning LLMs using Reinforced Learning and Inference-time Scaling Law
May 05, 2025



This survey explores recent advancements in reasoning large language models (LLMs) designed to mimic "slow thinking" - a reasoning process inspired by human cognition, as described in Kahneman's Thinking, Fast and Slow. These models, like OpenAI's o1, focus on scaling computational resources dynamically during complex tasks, such as math reasoning, visual reasoning, medical diagnosis, and multi-agent debates. We present the development of reasoning LLMs and list their key technologies. By synthesizing over 100 studies, it charts a path toward LLMs that combine human-like deep thinking with scalable efficiency for reasoning. The review breaks down methods into three categories: (1) test-time scaling dynamically adjusts computation based on task complexity via search and sampling, dynamic verification; (2) reinforced learning refines decision-making through iterative improvement leveraging policy networks, reward models, and self-evolution strategies; and (3) slow-thinking frameworks (e.g., long CoT, hierarchical processes) that structure problem-solving with manageable steps. The survey highlights the challenges and further directions of this domain. Understanding and advancing the reasoning abilities of LLMs is crucial for unlocking their full potential in real-world applications, from scientific discovery to decision support systems.
NoiseController: Towards Consistent Multi-view Video Generation via Noise Decomposition and Collaboration
Apr 25, 2025High-quality video generation is crucial for many fields, including the film industry and autonomous driving. However, generating videos with spatiotemporal consistencies remains challenging. Current methods typically utilize attention mechanisms or modify noise to achieve consistent videos, neglecting global spatiotemporal information that could help ensure spatial and temporal consistency during video generation. In this paper, we propose the NoiseController, consisting of Multi-Level Noise Decomposition, Multi-Frame Noise Collaboration, and Joint Denoising, to enhance spatiotemporal consistencies in video generation. In multi-level noise decomposition, we first decompose initial noises into scene-level foreground/background noises, capturing distinct motion properties to model multi-view foreground/background variations. Furthermore, each scene-level noise is further decomposed into individual-level shared and residual components. The shared noise preserves consistency, while the residual component maintains diversity. In multi-frame noise collaboration, we introduce an inter-view spatiotemporal collaboration matrix and an intra-view impact collaboration matrix , which captures mutual cross-view effects and historical cross-frame impacts to enhance video quality. The joint denoising contains two parallel denoising U-Nets to remove each scene-level noise, mutually enhancing video generation. We evaluate our NoiseController on public datasets focusing on video generation and downstream tasks, demonstrating its state-of-the-art performance.
Code-Driven Inductive Synthesis: Enhancing Reasoning Abilities of Large Language Models with Sequences
Mar 17, 2025



Large language models make remarkable progress in reasoning capabilities. Existing works focus mainly on deductive reasoning tasks (e.g., code and math), while another type of reasoning mode that better aligns with human learning, inductive reasoning, is not well studied. We attribute the reason to the fact that obtaining high-quality process supervision data is challenging for inductive reasoning. Towards this end, we novelly employ number sequences as the source of inductive reasoning data. We package sequences into algorithmic problems to find the general term of each sequence through a code solution. In this way, we can verify whether the code solution holds for any term in the current sequence, and inject case-based supervision signals by using code unit tests. We build a sequence synthetic data pipeline and form a training dataset CodeSeq. Experimental results show that the models tuned with CodeSeq improve on both code and comprehensive reasoning benchmarks.
LLM-KT: Aligning Large Language Models with Knowledge Tracing using a Plug-and-Play Instruction
Feb 05, 2025



The knowledge tracing (KT) problem is an extremely important topic in personalized education, which aims to predict whether students can correctly answer the next question based on their past question-answer records. Prior work on this task mainly focused on learning the sequence of behaviors based on the IDs or textual information. However, these studies usually fail to capture students' sufficient behavioral patterns without reasoning with rich world knowledge about questions. In this paper, we propose a large language models (LLMs)-based framework for KT, named \texttt{\textbf{LLM-KT}}, to integrate the strengths of LLMs and traditional sequence interaction models. For task-level alignment, we design Plug-and-Play instruction to align LLMs with KT, leveraging LLMs' rich knowledge and powerful reasoning capacity. For modality-level alignment, we design the plug-in context and sequence to integrate multiple modalities learned by traditional methods. To capture the long context of history records, we present a plug-in context to flexibly insert the compressed context embedding into LLMs using question-specific and concept-specific tokens. Furthermore, we introduce a plug-in sequence to enhance LLMs with sequence interaction behavior representation learned by traditional sequence models using a sequence adapter. Extensive experiments show that \texttt{\textbf{LLM-KT}} obtains state-of-the-art performance on four typical datasets by comparing it with approximately 20 strong baselines.
DAGPrompT: Pushing the Limits of Graph Prompting with a Distribution-aware Graph Prompt Tuning Approach
Jan 25, 2025



The pre-train then fine-tune approach has advanced GNNs by enabling general knowledge capture without task-specific labels. However, an objective gap between pre-training and downstream tasks limits its effectiveness. Recent graph prompting methods aim to close this gap through task reformulations and learnable prompts. Despite this, they struggle with complex graphs like heterophily graphs. Freezing the GNN encoder can reduce the impact of prompting, while simple prompts fail to handle diverse hop-level distributions. This paper identifies two key challenges in adapting graph prompting methods for complex graphs: (1) adapting the model to new distributions in downstream tasks to mitigate pre-training and fine-tuning discrepancies from heterophily and (2) customizing prompts for hop-specific node requirements. To overcome these challenges, we propose Distribution-aware Graph Prompt Tuning (DAGPrompT), which integrates a GLoRA module for optimizing the GNN encoder's projection matrix and message-passing schema through low-rank adaptation. DAGPrompT also incorporates hop-specific prompts accounting for varying graph structures and distributions among hops. Evaluations on 10 datasets and 14 baselines demonstrate that DAGPrompT improves accuracy by up to 4.79 in node and graph classification tasks, setting a new state-of-the-art while preserving efficiency. Codes are available at GitHub.
Enhancing Uncertainty Modeling with Semantic Graph for Hallucination Detection
Jan 02, 2025



Large Language Models (LLMs) are prone to hallucination with non-factual or unfaithful statements, which undermines the applications in real-world scenarios. Recent researches focus on uncertainty-based hallucination detection, which utilizes the output probability of LLMs for uncertainty calculation and does not rely on external knowledge or frequent sampling from LLMs. Whereas, most approaches merely consider the uncertainty of each independent token, while the intricate semantic relations among tokens and sentences are not well studied, which limits the detection of hallucination that spans over multiple tokens and sentences in the passage. In this paper, we propose a method to enhance uncertainty modeling with semantic graph for hallucination detection. Specifically, we first construct a semantic graph that well captures the relations among entity tokens and sentences. Then, we incorporate the relations between two entities for uncertainty propagation to enhance sentence-level hallucination detection. Given that hallucination occurs due to the conflict between sentences, we further present a graph-based uncertainty calibration method that integrates the contradiction probability of the sentence with its neighbors in the semantic graph for uncertainty calculation. Extensive experiments on two datasets show the great advantages of our proposed approach. In particular, we obtain substantial improvements with 19.78% in passage-level hallucination detection.
CMM-Math: A Chinese Multimodal Math Dataset To Evaluate and Enhance the Mathematics Reasoning of Large Multimodal Models
Sep 04, 2024



Large language models (LLMs) have obtained promising results in mathematical reasoning, which is a foundational skill for human intelligence. Most previous studies focus on improving and measuring the performance of LLMs based on textual math reasoning datasets (e.g., MATH, GSM8K). Recently, a few researchers have released English multimodal math datasets (e.g., MATHVISTA and MATH-V) to evaluate the effectiveness of large multimodal models (LMMs). In this paper, we release a Chinese multimodal math (CMM-Math) dataset, including benchmark and training parts, to evaluate and enhance the mathematical reasoning of LMMs. CMM-Math contains over 28,000 high-quality samples, featuring a variety of problem types (e.g., multiple-choice, fill-in-the-blank, and so on) with detailed solutions across 12 grade levels from elementary to high school in China. Specifically, the visual context may be present in the questions or opinions, which makes this dataset more challenging. Through comprehensive analysis, we discover that state-of-the-art LMMs on the CMM-Math dataset face challenges, emphasizing the necessity for further improvements in LMM development. We also propose a Multimodal Mathematical LMM (Math-LMM) to handle the problems with mixed input of multiple images and text segments. We train our model using three stages, including foundational pre-training, foundational fine-tuning, and mathematical fine-tuning. The extensive experiments indicate that our model effectively improves math reasoning performance by comparing it with the SOTA LMMs over three multimodal mathematical datasets.