 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALLOC: Benchmarking the Memory-aware Long Sequence Compression for Large Sequential Recommendation
Jan 29, 2026The scaling law, which indicates that model performance improves with increasing dataset and model capacity, has fueled a growing trend in expanding recommendation models in both industry and academia. However, the advent of large-scale recommenders also brings significantly higher computational costs, particularly under the long-sequence dependencies inherent in the user intent of recommendation systems. Current approaches often rely on pre-storing the intermediate states of the past behavior for each user, thereby reducing the quadratic re-computation cost for the following requests. Despite their effectiveness, these methods often treat memory merely as a medium for acceleration, without adequately considering the space overhead it introduces. This presents a critical challenge in real-world recommendation systems with billions of users, each of whom might initiate thousands of interactions and require massive memory for state storage. Fortunately, there have been several memory management strategies examined for compression in LLM, while most have not been evaluated on the recommendation task. To mitigate this gap, we introduce MALLOC, a comprehensive benchmark for memory-aware long sequence compression. MALLOC presents a comprehensive investigation and systematic classification of memory management techniques applicable to large sequential recommendations. These techniques are integrated into state-of-the-art recommenders, enabling a reproducible and accessible evaluation platform. Through extensive experiments across accuracy, efficiency, and complexity, we demonstrate the holistic reliability of MALLOC in advancing large-scale recommendation. Code is available at https://anonymous.4open.science/r/MALLOC.
ThinkRec: Thinking-based recommendation via LLM
May 21, 2025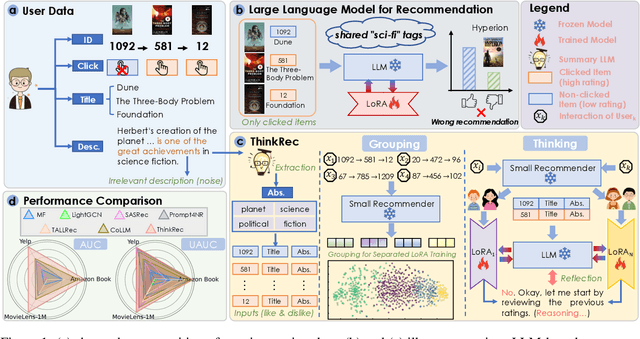
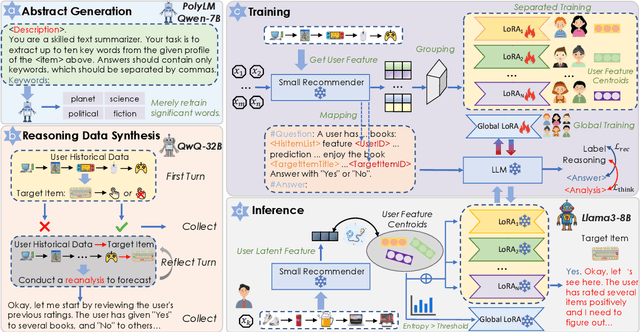

Recent advances in large language models (LLMs) have enabled more semantic-aware recommendations through natural language generation. Existing LLM for recommendation (LLM4Rec) methods mostly operate in a System 1-like manner, relying on superficial features to match similar items based on click history, rather than reasoning through deeper behavioral logic. This often leads to superficial and erroneous recommendations. Motivated by this, we propose ThinkRec, a thinking-based framework that shifts LLM4Rec from System 1 to System 2 (rational system). Technically, ThinkRec introduces a thinking activation mechanism that augments item metadata with keyword summarization and injects synthetic reasoning traces, guiding the model to form interpretable reasoning chains that consist of analyzing interaction histories, identifying user preferences, and making decisions based on target items. On top of this, we propose an instance-wise expert fusion mechanism to reduce the reasoning difficulty. By dynamically assigning weights to expert models based on users' latent features, ThinkRec adapts its reasoning path to individual users, thereby enhancing precision and personalization. Extensive experiments on real-world datasets demonstrate that ThinkRec significantly improves the accuracy and interpretability of recommendations. Our implementations are available in anonymous Github: https://anonymous.4open.science/r/ThinkRec_LLM.
Grouping First, Attending Smartly: Training-Free Acceleration for Diffusion Transformers
May 20, 2025



Diffusion-based Transformers have demonstrated impressive generative capabilities, but their high computational costs hinder practical deployment, for example, generating an $8192\times 8192$ image can take over an hour on an A100 GPU. In this work, we propose GRAT (\textbf{GR}ouping first, \textbf{AT}tending smartly), a training-free attention acceleration strategy for fast image and video generation without compromising output quality. The key insight is to exploit the inherent sparsity in learned attention maps (which tend to be locally focused) in pretrained Diffusion Transformers and leverage better GPU parallelism. Specifically, GRAT first partitions contiguous tokens into non-overlapping groups, aligning both with GPU execution patterns and the local attention structures learned in pretrained generative Transformers. It then accelerates attention by having all query tokens within the same group share a common set of attendable key and value tokens. These key and value tokens are further restricted to structured regions, such as surrounding blocks or criss-cross regions, significantly reducing computational overhead (e.g., attaining a \textbf{35.8$\times$} speedup over full attention when generating $8192\times 8192$ images) while preserving essential attention patterns and long-range context. We validate GRAT on pretrained Flux and HunyuanVideo for image and video generation, respectively. In both cases, GRAT achieves substantially faster inference without any fine-tuning, while maintaining the performance of full attention. We hope GRAT will inspire future research on accelerating Diffusion Transformers for scalable visual generation.
ReVision: High-Quality, Low-Cost Video Generation with Explicit 3D Physics Modeling for Complex Motion and Interaction
Apr 30, 2025In recent years, video generation has seen significant advancements. However, challenges still persist in generating complex motions and interactions. To address these challenges, we introduce ReVision, a plug-and-play framework that explicitly integrates parameterized 3D physical knowledge into a pretrained conditional video generation model, significantly enhancing its ability to generate high-quality videos with complex motion and interactions. Specifically, ReVision consists of three stages. First, a video diffusion model is used to generate a coarse video. Next, we extract a set of 2D and 3D features from the coarse video to construct a 3D object-centric representation, which is then refined by our proposed parameterized physical prior model to produce an accurate 3D motion sequence. Finally, this refined motion sequence is fed back into the same video diffusion model as additional conditioning, enabling the generation of motion-consistent videos, even in scenarios involving complex actions and interactions. We validate the effectiveness of our approach on Stable Video Diffusion, where ReVision significantly improves motion fidelity and coherence. Remarkably, with only 1.5B parameters, it even outperforms a state-of-the-art video generation model with over 13B parameters on complex video generation by a substantial margin. Our results suggest that, by incorporating 3D physical knowledge, even a relatively small video diffusion model can generate complex motions and interactions with greater realism and controllability, offering a promising solution for physically plausible video generation.
FlowTok: Flowing Seamlessly Across Text and Image Tokens
Mar 13, 2025Bridging different modalities lies at the heart of cross-modality generation. While conventional approaches treat the text modality as a conditioning signal that gradually guides the denoising process from Gaussian noise to the target image modality, we explore a much simpler paradigm-directly evolving between text and image modalities through flow matching. This requires projecting both modalities into a shared latent space, which poses a significant challenge due to their inherently different representations: text is highly semantic and encoded as 1D tokens, whereas images are spatially redundant and represented as 2D latent embeddings. To address this, we introduce FlowTok, a minimal framework that seamlessly flows across text and images by encoding images into a compact 1D token representation. Compared to prior methods, this design reduces the latent space size by 3.3x at an image resolution of 256, eliminating the need for complex conditioning mechanisms or noise scheduling. Moreover, FlowTok naturally extends to image-to-text generation under the same formulation. With its streamlined architecture centered around compact 1D tokens, FlowTok is highly memory-efficient, requires significantly fewer training resources, and achieves much faster sampling speeds-all while delivering performance comparable to state-of-the-art models. Code will be available at https://github.com/bytedance/1d-tokenizer.
Beyond Next-Token: Next-X Prediction for Autoregressive Visual Generation
Feb 27, 2025Autoregressive (AR) modeling, known for its next-token prediction paradigm, underpins state-of-the-art language and visual generative models. Traditionally, a ``token'' is treated as the smallest prediction unit, often a discrete symbol in language or a quantized patch in vision. However, the optimal token definition for 2D image structures remains an open question. Moreover, AR models suffer from exposure bias, where teacher forcing during training leads to error accumulation at inference. In this paper, we propose xAR, a generalized AR framework that extends the notion of a token to an entity X, which can represent an individual patch token, a cell (a $k\times k$ grouping of neighboring patches), a subsample (a non-local grouping of distant patches), a scale (coarse-to-fine resolution), or even a whole image. Additionally, we reformulate discrete token classification as \textbf{continuous entity regression}, leveraging flow-matching methods at each AR step. This approach conditions training on noisy entities instead of ground truth tokens, leading to Noisy Context Learning, which effectively alleviates exposure bias. As a result, xAR offers two key advantages: (1) it enables flexible prediction units that capture different contextual granularity and spatial structures, and (2) it mitigates exposure bias by avoiding reliance on teacher forcing. On ImageNet-256 generation benchmark, our base model, xAR-B (172M), outperforms DiT-XL/SiT-XL (675M) while achieving 20$\times$ faster inference. Meanwhile, xAR-H sets a new state-of-the-art with an FID of 1.24, running 2.2$\times$ faster than the previous best-performing model without relying on vision foundation modules (\eg, DINOv2) or advanced guidance interval sampling.
Dictionary-based Framework for Interpretable and Consistent Object Parsing
Feb 26, 2025In this work, we present CoCal, an interpretable and consistent object parsing framework based on dictionary-based mask transformer. Designed around Contrastive Components and Logical Constraints, CoCal rethinks existing cluster-based mask transformer architectures used in segmentation; Specifically, CoCal utilizes a set of dictionary components, with each component being explicitly linked to a specific semantic class. To advance this concept, CoCal introduces a hierarchical formulation of dictionary components that aligns with the semantic hierarchy. This is achieved through the integration of both within-level contrastive components and cross-level logical constraints. Concretely, CoCal employs a component-wise contrastive algorithm at each semantic level, enabling the contrasting of dictionary components within the same class against those from different classes. Furthermore, CoCal addresses logical concerns by ensuring that the dictionary component representing a particular part is closer to its corresponding object component than to those of other objects through a cross-level contrastive learning objective. To further enhance our logical relation modeling, we implement a post-processing function inspired by the principle that a pixel assigned to a part should also be assigned to its corresponding object. With these innovations, CoCal establishes a new state-of-the-art performance on both PartImageNet and Pascal-Part-108, outperforming previous methods by a significant margin of 2.08% and 0.70% in part mIoU, respectively. Moreover, CoCal exhibits notable enhancements in object-level metrics across these benchmarks, highlighting its capacity to not only refine parsing at a finer level but also elevate the overall quality of object segmentation.
COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation
Feb 04, 2025This paper introduces the COCONut-PanCap dataset, created to enhance panoptic segmentation and grounded image captioning. Building upon the COCO dataset with advanced COCONut panoptic masks, this dataset aims to overcome limitations in existing image-text datasets that often lack detailed, scene-comprehensive descriptions. The COCONut-PanCap dataset incorporates fine-grained, region-level captions grounded in panoptic segmentation masks, ensuring consistency and improving the detail of generated captions. Through human-edited, densely annotated descriptions, COCONut-PanCap supports improved training of vision-language models (VLMs) for image understanding and generative models for text-to-image tasks. Experimental results demonstrate that COCONut-PanCap significantly boosts performance across understanding and generation tasks, offering complementary benefits to large-scale datasets. This dataset sets a new benchmark for evaluating models on joint panoptic segmentation and grounded captioning tasks, addressing the need for high-quality, detailed image-text annotations in multi-modal learning.
Democratizing Text-to-Image Masked Generative Models with Compact Text-Aware One-Dimensional Tokens
Jan 13, 2025



Image tokenizers form the foundation of modern text-to-image generative models but are notoriously difficult to train. Furthermore, most existing text-to-image models rely on large-scale, high-quality private datasets, making them challenging to replicate. In this work, we introduce Text-Aware Transformer-based 1-Dimensional Tokenizer (TA-TiTok), an efficient and powerful image tokenizer that can utilize either discrete or continuous 1-dimensional tokens. TA-TiTok uniquely integrates textual information during the tokenizer decoding stage (i.e., de-tokenization), accelerating convergence and enhancing performance. TA-TiTok also benefits from a simplified, yet effective, one-stage training process, eliminating the need for the complex two-stage distillation used in previous 1-dimensional tokenizers. This design allows for seamless scalability to large datasets. Building on this, we introduce a family of text-to-image Masked Generative Models (MaskGen), trained exclusively on open data while achieving comparable performance to models trained on private data. We aim to release both the efficient, strong TA-TiTok tokenizers and the open-data, open-weight MaskGen models to promote broader access and democratize the field of text-to-image masked generative models.
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
Dec 19, 2024Autoregressive (AR) modeling has achieved remarkable success in natural language processing by enabling models to generate text with coherence and contextual understanding through next token prediction. Recently, in image generation, VAR proposes scale-wise autoregressive modeling, which extends the next token prediction to the next scale prediction, preserving the 2D structure of images. However, VAR encounters two primary challenges: (1) its complex and rigid scale design limits generalization in next scale prediction, and (2) the generator's dependence on a discrete tokenizer with the same complex scale structure restricts modularity and flexibility in updating the tokenizer. To address these limitations, we introduce FlowAR, a general next scale prediction method featuring a streamlined scale design, where each subsequent scale is simply double the previous one. This eliminates the need for VAR's intricate multi-scale residual tokenizer and enables the use of any off-the-shelf Variational AutoEncoder (VAE). Our simplified design enhances generalization in next scale prediction and facilitates the integration of Flow Matching for high-quality image synthesis. We validate the effectiveness of FlowAR on the challenging ImageNet-256 benchmark, demonstrating superior generation performance compared to previous methods. Codes will be available at \url{https://github.com/OliverRensu/FlowAR}.