 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALLOC: Benchmarking the Memory-aware Long Sequence Compression for Large Sequential Recommendation
Jan 29, 2026The scaling law, which indicates that model performance improves with increasing dataset and model capacity, has fueled a growing trend in expanding recommendation models in both industry and academia. However, the advent of large-scale recommenders also brings significantly higher computational costs, particularly under the long-sequence dependencies inherent in the user intent of recommendation systems. Current approaches often rely on pre-storing the intermediate states of the past behavior for each user, thereby reducing the quadratic re-computation cost for the following requests. Despite their effectiveness, these methods often treat memory merely as a medium for acceleration, without adequately considering the space overhead it introduces. This presents a critical challenge in real-world recommendation systems with billions of users, each of whom might initiate thousands of interactions and require massive memory for state storage. Fortunately, there have been several memory management strategies examined for compression in LLM, while most have not been evaluated on the recommendation task. To mitigate this gap, we introduce MALLOC, a comprehensive benchmark for memory-aware long sequence compression. MALLOC presents a comprehensive investigation and systematic classification of memory management techniques applicable to large sequential recommendations. These techniques are integrated into state-of-the-art recommenders, enabling a reproducible and accessible evaluation platform. Through extensive experiments across accuracy, efficiency, and complexity, we demonstrate the holistic reliability of MALLOC in advancing large-scale recommendation. Code is available at https://anonymous.4open.science/r/MALLOC.
Deep Technology Tracing for High-tech Companies
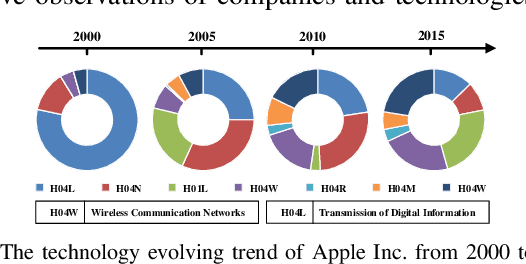
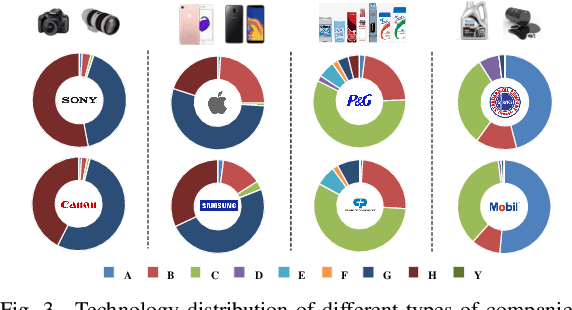
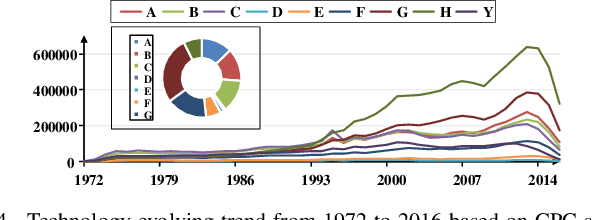
Jan 02, 2020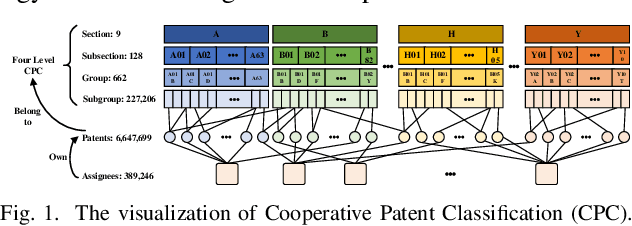
Technological change and innovation are vitally important, especially for high-tech companies. However, factors influencing their future research and development (R&D) trends are both complicated and various, leading it a quite difficult task to make technology tracing for high-tech companies. To this end, in this paper, we develop a novel data-driven solution, i.e., Deep Technology Forecasting (DTF) framework, to automatically find the most possible technology directions customized to each high-tech company. Specially, DTF consists of three components: Potential Competitor Recognition (PCR), Collaborative Technology Recognition (CTR), and Deep Technology Tracing (DTT) neural network. For one thing, PCR and CTR aim to capture competitive relations among enterprises and collaborative relations among technologies, respectively. For another, DTT is designed for modeling dynamic interactions between companies and technologies with the above relations involved. Finally, we evaluate our DTF framework on real-world patent data, and the experimental results clearly prove that DTF can precisely help to prospect future technology emphasis of companies by exploiting hybrid factors.