 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Achieving Near-optimal Utility for Privacy-Preserving Federated Learning via Data Generation and Parameter Distortion
May 19, 2023Federated learning (FL) enables participating parties to collaboratively build a global model with boosted utility without disclosing private data information. Appropriate protection mechanisms have to be adopted to fulfill the requirements in preserving \textit{privacy} and maintaining high model \textit{utility}. The nature of the widely-adopted protection mechanisms including \textit{Randomization Mechanism} and \textit{Compression Mechanism} is to protect privacy via distorting model parameter. We measure the utility via the gap between the original model parameter and the distorted model parameter. We want to identify under what general conditions privacy-preserving federated learning can achieve near-optimal utility via data generation and parameter distortion. To provide an avenue for achieving near-optimal utility, we present an upper bound for utility loss, which is measured using two main terms called variance-reduction and model parameter discrepancy separately. Our analysis inspires the design of appropriate protection parameters for the protection mechanisms to achieve near-optimal utility and meet the privacy requirements simultaneously. The main techniques for the protection mechanism include parameter distortion and data generation, which are generic and can be applied extensively. Furthermore, we provide an upper bound for the trade-off between privacy and utility, which together with the lower bound illustrated in NFL form the conditions for achieving optimal trade-off.
A Topic-aware Summarization Framework with Different Modal Side Information
May 19, 2023



Automatic summarization plays an important role in the exponential document growth on the Web. On content websites such as CNN.com and WikiHow.com, there often exist various kinds of side information along with the main document for attention attraction and easier understanding, such as videos, images, and queries. Such information can be used for better summarization, as they often explicitly or implicitly mention the essence of the article. However, most of the existing side-aware summarization methods are designed to incorporate either single-modal or multi-modal side information, and cannot effectively adapt to each other. In this paper, we propose a general summarization framework, which can flexibly incorporate various modalities of side information. The main challenges in designing a flexible summarization model with side information include: (1) the side information can be in textual or visual format, and the model needs to align and unify it with the document into the same semantic space, (2) the side inputs can contain information from various aspects, and the model should recognize the aspects useful for summarization. To address these two challenges, we first propose a unified topic encoder, which jointly discovers latent topics from the document and various kinds of side information. The learned topics flexibly bridge and guide the information flow between multiple inputs in a graph encoder through a topic-aware interaction. We secondly propose a triplet contrastive learning mechanism to align the single-modal or multi-modal information into a unified semantic space, where the summary quality is enhanced by better understanding the document and side information. Results show that our model significantly surpasses strong baselines on three public single-modal or multi-modal benchmark summarization datasets.
FedSOV: Federated Model Secure Ownership Verification with Unforgeable Signature
May 10, 2023



Federated learning allows multiple parties to collaborate in learning a global model without revealing private data. The high cost of training and the significant value of the global model necessitates the need for ownership verification of federated learning. However, the existing ownership verification schemes in federated learning suffer from several limitations, such as inadequate support for a large number of clients and vulnerability to ambiguity attacks. To address these limitations, we propose a cryptographic signature-based federated learning model ownership verification scheme named FedSOV. FedSOV allows numerous clients to embed their ownership credentials and verify ownership using unforgeable digital signatures. The scheme provides theoretical resistance to ambiguity attacks with the unforgeability of the signature. Experimental results on computer vision and natural language processing tasks demonstrate that FedSOV is an effective federated model ownership verification scheme enhanced with provable cryptographic security.
FedZKP: Federated Model Ownership Verification with Zero-knowledge Proof
May 10, 2023



Federated learning (FL) allows multiple parties to cooperatively learn a federated model without sharing private data with each other. The need of protecting such federated models from being plagiarized or misused, therefore, motivates us to propose a provable secure model ownership verification scheme using zero-knowledge proof, named FedZKP. It is shown that the FedZKP scheme without disclosing credentials is guaranteed to defeat a variety of existing and potential attacks. Both theoretical analysis and empirical studies demonstrate the security of FedZKP in the sense that the probability for attackers to breach the proposed FedZKP is negligible. Moreover, extensive experimental results confirm the fidelity and robustness of our scheme.
Optimizing Privacy, Utility and Efficiency in Constrained Multi-Objective Federated Learning
May 09, 2023Conventionally, federated learning aims to optimize a single objective, typically the utility. However, for a federated learning system to be trustworthy, it needs to simultaneously satisfy multiple/many objectives, such as maximizing model performance, minimizing privacy leakage and training cost, and being robust to malicious attacks. Multi-Objective Optimization (MOO) aiming to optimize multiple conflicting objectives at the same time is quite suitable for solving the optimization problem of Trustworthy Federated Learning (TFL). In this paper, we unify MOO and TFL by formulating the problem of constrained multi-objective federated learning (CMOFL). Under this formulation, existing MOO algorithms can be adapted to TFL straightforwardly. Different from existing CMOFL works focusing on utility, efficiency, fairness, and robustness, we consider optimizing privacy leakage along with utility loss and training cost, the three primary objectives of a TFL system. We develop two improved CMOFL algorithms based on NSGA-II and PSL, respectively, for effectively and efficiently finding Pareto optimal solutions, and we provide theoretical analysis on their convergence. We design specific measurements of privacy leakage, utility loss, and training cost for three privacy protection mechanisms: Randomization, BatchCrypt (An efficient version of homomorphic encryption), and Sparsification. Empirical experiments conducted under each of the three protection mechanisms demonstrate the effectiveness of our proposed algorithms.
Learn to Cluster Faces with Better Subgraphs
Apr 21, 2023



Face clustering can provide pseudo-labels to the massive unlabeled face data and improve the performance of different face recognition models. The existing clustering methods generally aggregate the features within subgraphs that are often implemented based on a uniform threshold or a learned cutoff position. This may reduce the recall of subgraphs and hence degrade the clustering performance. This work proposed an efficient neighborhood-aware subgraph adjustment method that can significantly reduce the noise and improve the recall of the subgraphs, and hence can drive the distant nodes to converge towards the same centers. More specifically, the proposed method consists of two components, i.e. face embeddings enhancement using the embeddings from neighbors, and enclosed subgraph construction of node pairs for structural information extraction. The embeddings are combined to predict the linkage probabilities for all node pairs to replace the cosine similarities to produce new subgraphs that can be further used for aggregation of GCNs or other clustering methods. The proposed method is validated through extensive experiments against a range of clustering solutions using three benchmark datasets and numerical results confirm that it outperforms the SOTA solutions in terms of generalization capability.
Probably Approximately Correct Federated Learning
Apr 13, 2023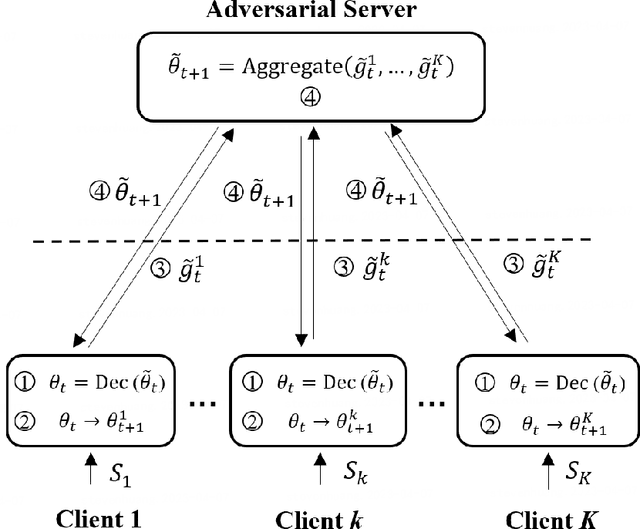

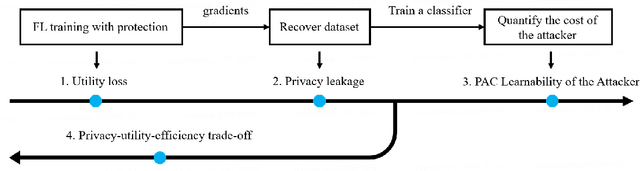
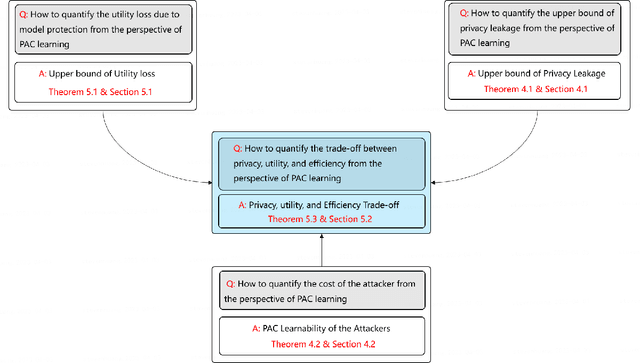
Federated learning (FL) is a new distributed learning paradigm, with privacy, utility, and efficiency as its primary pillars. Existing research indicates that it is unlikely to simultaneously attain infinitesimal privacy leakage, utility loss, and efficiency. Therefore, how to find an optimal trade-off solution is the key consideration when designing the FL algorithm. One common way is to cast the trade-off problem as a multi-objective optimization problem, i.e., the goal is to minimize the utility loss and efficiency reduction while constraining the privacy leakage not exceeding a predefined value. However, existing multi-objective optimization frameworks are very time-consuming, and do not guarantee the existence of the Pareto frontier, this motivates us to seek a solution to transform the multi-objective problem into a single-objective problem because it is more efficient and easier to be solved. To this end, we propose FedPAC, a unified framework that leverages PAC learning to quantify multiple objectives in terms of sample complexity, such quantification allows us to constrain the solution space of multiple objectives to a shared dimension, so that it can be solved with the help of a single-objective optimization algorithm. Specifically, we provide the results and detailed analyses of how to quantify the utility loss, privacy leakage, privacy-utility-efficiency trade-off, as well as the cost of the attacker from the PAC learning perspective.
A Game-theoretic Framework for Federated Learning
Apr 11, 2023In federated learning, benign participants aim to optimize a global model collaboratively. However, the risk of \textit{privacy leakage} cannot be ignored in the presence of \textit{semi-honest} adversaries. Existing research has focused either on designing protection mechanisms or on inventing attacking mechanisms. While the battle between defenders and attackers seems never-ending, we are concerned with one critical question: is it possible to prevent potential attacks in advance? To address this, we propose the first game-theoretic framework that considers both FL defenders and attackers in terms of their respective payoffs, which include computational costs, FL model utilities, and privacy leakage risks. We name this game the Federated Learning Security Game (FLSG), in which neither defenders nor attackers are aware of all participants' payoffs. To handle the \textit{incomplete information} inherent in this situation, we propose associating the FLSG with an \textit{oracle} that has two primary responsibilities. First, the oracle provides lower and upper bounds of the payoffs for the players. Second, the oracle acts as a correlation device, privately providing suggested actions to each player. With this novel framework, we analyze the optimal strategies of defenders and attackers. Furthermore, we derive and demonstrate conditions under which the attacker, as a rational decision-maker, should always follow the oracle's suggestion \textit{not to attack}.
Federated Learning without Full Labels: A Survey
Mar 25, 2023



Data privacy has become an increasingly important concern in real-world big data applications such as machine learning. To address the problem, federated learning (FL) has been a promising solution to building effective machine learning models from decentralized and private data. Existing federated learning algorithms mainly tackle the supervised learning problem, where data are assumed to be fully labeled. However, in practice, fully labeled data is often hard to obtain, as the participants may not have sufficient domain expertise, or they lack the motivation and tools to label data. Therefore, the problem of federated learning without full labels is important in real-world FL applications. In this paper, we discuss how the problem can be solved with machine learning techniques that leverage unlabeled data. We present a survey of methods that combine FL with semi-supervised learning, self-supervised learning, and transfer learning methods. We also summarize the datasets used to evaluate FL methods without full labels. Finally, we highlight future directions in the context of FL without full labels.
FedPass: Privacy-Preserving Vertical Federated Deep Learning with Adaptive Obfuscation
Jan 31, 2023Vertical federated learning (VFL) allows an active party with labeled feature to leverage auxiliary features from the passive parties to improve model performance. Concerns about the private feature and label leakage in both the training and inference phases of VFL have drawn wide research attention. In this paper, we propose a general privacy-preserving vertical federated deep learning framework called FedPass, which leverages adaptive obfuscation to protect the feature and label simultaneously. Strong privacy-preserving capabilities about private features and labels are theoretically proved (in Theorems 1 and 2). Extensive experimental result s with different datasets and network architectures also justify the superiority of FedPass against existing methods in light of its near-optimal trade-off between privacy and model performance.