 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025

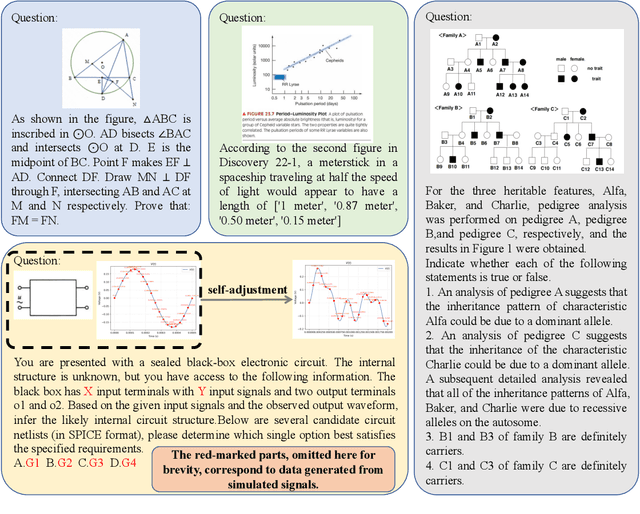
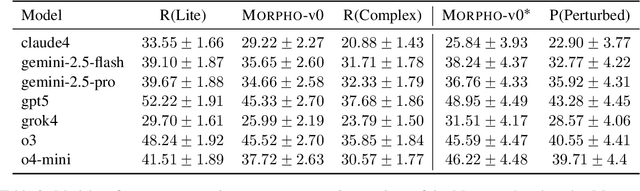
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
Cautious Weight Decay
Oct 14, 2025We introduce Cautious Weight Decay (CWD), a one-line, optimizer-agnostic modification that applies weight decay only to parameter coordinates whose signs align with the optimizer update. Unlike standard decoupled decay, which implicitly optimizes a regularized or constrained objective, CWD preserves the original loss and admits a bilevel interpretation: it induces sliding-mode behavior upon reaching the stationary manifold, allowing it to search for locally Pareto-optimal stationary points of the unmodified objective. In practice, CWD is a drop-in change for optimizers such as AdamW, Lion, and Muon, requiring no new hyperparameters or additional tuning. For language model pre-training and ImageNet classification, CWD consistently improves final loss and accuracy at million- to billion-parameter scales.
GenPilot: A Multi-Agent System for Test-Time Prompt Optimization in Image Generation
Oct 08, 2025Text-to-image synthesis has made remarkable progress, yet accurately interpreting complex and lengthy prompts remains challenging, often resulting in semantic inconsistencies and missing details. Existing solutions, such as fine-tuning, are model-specific and require training, while prior automatic prompt optimization (APO) approaches typically lack systematic error analysis and refinement strategies, resulting in limited reliability and effectiveness. Meanwhile, test-time scaling methods operate on fixed prompts and on noise or sample numbers, limiting their interpretability and adaptability. To solve these, we introduce a flexible and efficient test-time prompt optimization strategy that operates directly on the input text. We propose a plug-and-play multi-agent system called GenPilot, integrating error analysis, clustering-based adaptive exploration, fine-grained verification, and a memory module for iterative optimization. Our approach is model-agnostic, interpretable, and well-suited for handling long and complex prompts. Simultaneously, we summarize the common patterns of errors and the refinement strategy, offering more experience and encouraging further exploration. Experiments on DPG-bench and Geneval with improvements of up to 16.9% and 5.7% demonstrate the strong capability of our methods in enhancing the text and image consistency and structural coherence of generated images, revealing the effectiveness of our test-time prompt optimization strategy. The code is available at https://github.com/27yw/GenPilot.
UPRPRC: Unified Pipeline for Reproducing Parallel Resources -- Corpus from the United Nations
Sep 19, 2025The quality and accessibility of multilingual datasets are crucial for advancing machine translation. However, previous corpora built from United Nations documents have suffered from issues such as opaque process, difficulty of reproduction, and limited scale. To address these challenges, we introduce a complete end-to-end solution, from data acquisition via web scraping to text alignment. The entire process is fully reproducible, with a minimalist single-machine example and optional distributed computing steps for scalability. At its core, we propose a new Graph-Aided Paragraph Alignment (GAPA) algorithm for efficient and flexible paragraph-level alignment. The resulting corpus contains over 713 million English tokens, more than doubling the scale of prior work. To the best of our knowledge, this represents the largest publicly available parallel corpus composed entirely of human-translated, non-AI-generated content. Our code and corpus are accessible under the MIT License.
DiffSpectra: Molecular Structure Elucidation from Spectra using Diffusion Models
Jul 09, 2025Molecular structure elucidation from spectra is a foundational problem in chemistry, with profound implications for compound identification, synthesis, and drug development. Traditional methods rely heavily on expert interpretation and lack scalability. Pioneering machine learning methods have introduced retrieval-based strategies, but their reliance on finite libraries limits generalization to novel molecules. Generative models offer a promising alternative, yet most adopt autoregressive SMILES-based architectures that overlook 3D geometry and struggle to integrate diverse spectral modalities. In this work, we present DiffSpectra, a generative framework that directly infers both 2D and 3D molecular structures from multi-modal spectral data using diffusion models. DiffSpectra formulates structure elucidation as a conditional generation process. Its denoising network is parameterized by Diffusion Molecule Transformer, an SE(3)-equivariant architecture that integrates topological and geometric information. Conditioning is provided by SpecFormer, a transformer-based spectral encoder that captures intra- and inter-spectral dependencies from multi-modal spectra. Extensive experiments demonstrate that DiffSpectra achieves high accuracy in structure elucidation, recovering exact structures with 16.01% top-1 accuracy and 96.86% top-20 accuracy through sampling. The model benefits significantly from 3D geometric modeling, SpecFormer pre-training, and multi-modal conditioning. These results highlight the effectiveness of spectrum-conditioned diffusion modeling in addressing the challenge of molecular structure elucidation. To our knowledge, DiffSpectra is the first framework to unify multi-modal spectral reasoning and joint 2D/3D generative modeling for de novo molecular structure elucidation.
Muon Optimizes Under Spectral Norm Constraints
Jun 18, 2025The pursuit of faster optimization algorithms remains an active and important research direction in deep learning. Recently, the Muon optimizer [JJB+24] has demonstrated promising empirical performance, but its theoretical foundation remains less understood. In this paper, we bridge this gap and provide a theoretical analysis of Muon by placing it within the Lion-$\mathcal{K}$ family of optimizers [CLLL24]. Specifically, we show that Muon corresponds to Lion-$\mathcal{K}$ when equipped with the nuclear norm, and we leverage the theoretical results of Lion-$\mathcal{K}$ to establish that Muon (with decoupled weight decay) implicitly solves an optimization problem that enforces a constraint on the spectral norm of weight matrices. This perspective not only demystifies the implicit regularization effects of Muon but also leads to natural generalizations through varying the choice of convex map $\mathcal{K}$, allowing for the exploration of a broader class of implicitly regularized and constrained optimization algorithms.
Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing
Jun 11, 2025



As textual reasoning with large language models (LLMs) has advanced significantly, there has been growing interest in enhancing the multimodal reasoning capabilities of large vision-language models (LVLMs). However, existing methods primarily approach multimodal reasoning in a straightforward, text-centric manner, where both reasoning and answer derivation are conducted purely through text, with the only difference being the presence of multimodal input. As a result, these methods often encounter fundamental limitations in spatial reasoning tasks that demand precise geometric understanding and continuous spatial tracking-capabilities that humans achieve through mental visualization and manipulation. To address the limitations, we propose drawing to reason in space, a novel paradigm that enables LVLMs to reason through elementary drawing operations in the visual space. By equipping models with basic drawing operations, including annotating bounding boxes and drawing auxiliary lines, we empower them to express and analyze spatial relationships through direct visual manipulation, meanwhile avoiding the performance ceiling imposed by specialized perception tools in previous tool-integrated reasoning approaches. To cultivate this capability, we develop a three-stage training framework: cold-start training with synthetic data to establish basic drawing abilities, reflective rejection sampling to enhance self-reflection behaviors, and reinforcement learning to directly optimize for target rewards. Extensive experiments demonstrate that our model, named VILASR, consistently outperforms existing methods across diverse spatial reasoning benchmarks, involving maze navigation, static spatial reasoning, video-based reasoning, and multi-view-based reasoning tasks, with an average improvement of 18.4%.
Flow Matching Meets PDEs: A Unified Framework for Physics-Constrained Generation
Jun 10, 2025Generative machine learning methods, such as diffusion models and flow matching, have shown great potential in modeling complex system behaviors and building efficient surrogate models. However, these methods typically learn the underlying physics implicitly from data. We propose Physics-Based Flow Matching (PBFM), a novel generative framework that explicitly embeds physical constraints, both PDE residuals and algebraic relations, into the flow matching objective. We also introduce temporal unrolling at training time that improves the accuracy of the final, noise-free sample prediction. Our method jointly minimizes the flow matching loss and the physics-based residual loss without requiring hyperparameter tuning of their relative weights. Additionally, we analyze the role of the minimum noise level, $\sigma_{\min}$, in the context of physical constraints and evaluate a stochastic sampling strategy that helps to reduce physical residuals. Through extensive benchmarks on three representative PDE problems, we show that our approach yields up to an $8\times$ more accurate physical residuals compared to FM, while clearly outperforming existing algorithms in terms of distributional accuracy. PBFM thus provides a principled and efficient framework for surrogate modeling, uncertainty quantification, and accelerated simulation in physics and engineering applications.
VersaVid-R1: A Versatile Video Understanding and Reasoning Model from Question Answering to Captioning Tasks
Jun 10, 2025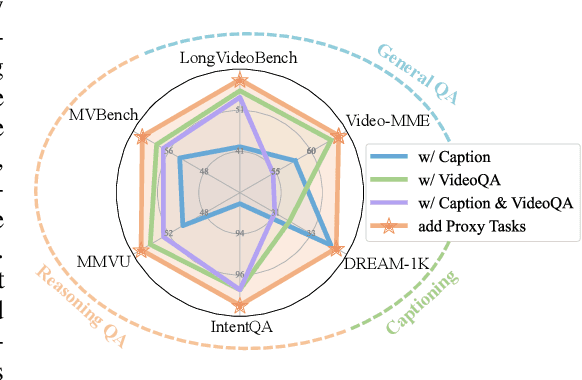

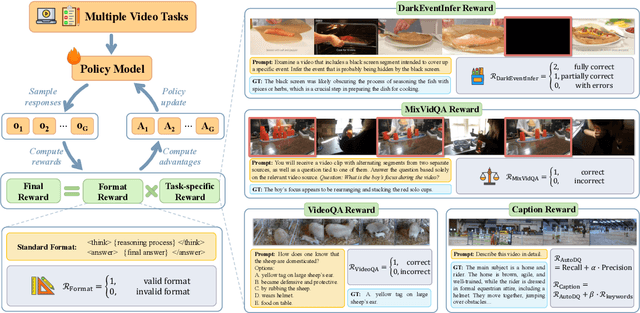

Recent advancements in multimodal large language models have successfully extended the Reason-Then-Respond paradigm to image-based reasoning, yet video-based reasoning remains an underdeveloped frontier, primarily due to the scarcity of high-quality reasoning-oriented data and effective training methodologies. To bridge this gap, we introduce DarkEventInfer and MixVidQA, two novel datasets specifically designed to stimulate the model's advanced video understanding and reasoning abilities. DarkEventinfer presents videos with masked event segments, requiring models to infer the obscured content based on contextual video cues. MixVidQA, on the other hand, presents interleaved video sequences composed of two distinct clips, challenging models to isolate and reason about one while disregarding the other. Leveraging these carefully curated training samples together with reinforcement learning guided by diverse reward functions, we develop VersaVid-R1, the first versatile video understanding and reasoning model under the Reason-Then-Respond paradigm capable of handling multiple-choice and open-ended question answering, as well as video captioning tasks. Extensive experiments demonstrate that VersaVid-R1 significantly outperforms existing models across a broad spectrum of benchmarks, covering video general understanding, cognitive reasoning, and captioning tasks.
MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
Jun 05, 2025We introduce MonkeyOCR, a vision-language model for document parsing that advances the state of the art by leveraging a Structure-Recognition-Relation (SRR) triplet paradigm. This design simplifies what would otherwise be a complex multi-tool pipeline (as in MinerU's modular approach) and avoids the inefficiencies of processing full pages with giant end-to-end models (e.g., large multimodal LLMs like Qwen-VL). In SRR, document parsing is abstracted into three fundamental questions - "Where is it?" (structure), "What is it?" (recognition), and "How is it organized?" (relation) - corresponding to layout analysis, content identification, and logical ordering. This focused decomposition balances accuracy and speed: it enables efficient, scalable processing without sacrificing precision. To train and evaluate this approach, we introduce the MonkeyDoc (the most comprehensive document parsing dataset to date), with 3.9 million instances spanning over ten document types in both Chinese and English. Experiments show that MonkeyOCR outperforms MinerU by an average of 5.1%, with particularly notable improvements on challenging content such as formulas (+15.0%) and tables (+8.6%). Remarkably, our 3B-parameter model surpasses much larger and top-performing models, including Qwen2.5-VL (72B) and Gemini 2.5 Pro, achieving state-of-the-art average performance on English document parsing tasks. In addition, MonkeyOCR processes multi-page documents significantly faster (0.84 pages per second compared to 0.65 for MinerU and 0.12 for Qwen2.5-VL-7B). The 3B model can be efficiently deployed for inference on a single NVIDIA 3090 GPU. Code and models will be released at https://github.com/Yuliang-Liu/MonkeyOCR.