 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
Aug 27, 2025



Graph retrieval-augmented generation (GraphRAG) has effectively enhanced large language models in complex reasoning by organizing fragmented knowledge into explicitly structured graphs. Prior efforts have been made to improve either graph construction or graph retrieval in isolation, yielding suboptimal performance, especially when domain shifts occur. In this paper, we propose a vertically unified agentic paradigm, Youtu-GraphRAG, to jointly connect the entire framework as an intricate integration. Specifically, (i) a seed graph schema is introduced to bound the automatic extraction agent with targeted entity types, relations and attribute types, also continuously expanded for scalability over unseen domains; (ii) To obtain higher-level knowledge upon the schema, we develop novel dually-perceived community detection, fusing structural topology with subgraph semantics for comprehensive knowledge organization. This naturally yields a hierarchical knowledge tree that supports both top-down filtering and bottom-up reasoning with community summaries; (iii) An agentic retriever is designed to interpret the same graph schema to transform complex queries into tractable and parallel sub-queries. It iteratively performs reflection for more advanced reasoning; (iv) To alleviate the knowledge leaking problem in pre-trained LLM, we propose a tailored anonymous dataset and a novel 'Anonymity Reversion' task that deeply measures the real performance of the GraphRAG frameworks. Extensive experiments across six challenging benchmarks demonstrate the robustness of Youtu-GraphRAG, remarkably moving the Pareto frontier with up to 90.71% saving of token costs and 16.62% higher accuracy over state-of-the-art baselines. The results indicate our adaptability, allowing seamless domain transfer with minimal intervention on schema.
Sequential-NIAH: A Needle-In-A-Haystack Benchmark for Extracting Sequential Needles from Long Contexts
Apr 09, 2025Evaluating the ability of large language models (LLMs) to handle extended contexts is critical, particularly for retrieving information relevant to specific queries embedded within lengthy inputs. We introduce Sequential-NIAH, a benchmark specifically designed to evaluate the capability of LLMs to extract sequential information items (known as needles) from long contexts. The benchmark comprises three types of needle generation pipelines: synthetic, real, and open-domain QA. It includes contexts ranging from 8K to 128K tokens in length, with a dataset of 14,000 samples (2,000 reserved for testing). To facilitate evaluation on this benchmark, we trained a synthetic data-driven evaluation model capable of evaluating answer correctness based on chronological or logical order, achieving an accuracy of 99.49% on synthetic test data. We conducted experiments on six well-known LLMs, revealing that even the best-performing model achieved a maximum accuracy of only 63.15%. Further analysis highlights the growing challenges posed by increasing context lengths and the number of needles, underscoring substantial room for improvement. Additionally, noise robustness experiments validate the reliability of the benchmark, making Sequential-NIAH an important reference for advancing research on long text extraction capabilities of LLMs.
FactGuard: Leveraging Multi-Agent Systems to Generate Answerable and Unanswerable Questions for Enhanced Long-Context LLM Extraction
Apr 08, 2025Extractive reading comprehension systems are designed to locate the correct answer to a question within a given text. However, a persistent challenge lies in ensuring these models maintain high accuracy in answering questions while reliably recognizing unanswerable queries. Despite significant advances in large language models (LLMs) for reading comprehension, this issue remains critical, particularly as the length of supported contexts continues to expand. To address this challenge, we propose an innovative data augmentation methodology grounded in a multi-agent collaborative framework. Unlike traditional methods, such as the costly human annotation process required for datasets like SQuAD 2.0, our method autonomously generates evidence-based question-answer pairs and systematically constructs unanswerable questions. Using this methodology, we developed the FactGuard-Bench dataset, which comprises 25,220 examples of both answerable and unanswerable question scenarios, with context lengths ranging from 8K to 128K. Experimental evaluations conducted on seven popular LLMs reveal that even the most advanced models achieve only 61.79% overall accuracy. Furthermore, we emphasize the importance of a model's ability to reason about unanswerable questions to avoid generating plausible but incorrect answers. By implementing efficient data selection and generation within the multi-agent collaborative framework, our method significantly reduces the traditionally high costs associated with manual annotation and provides valuable insights for the training and optimization of LLMs.
CJEval: A Benchmark for Assessing Large Language Models Using Chinese Junior High School Exam Data
Sep 25, 2024



Online education platforms have significantly transformed the dissemination of educational resources by providing a dynamic and digital infrastructure. With the further enhancement of this transformation, the advent of Large Language Models (LLMs) has elevated the intelligence levels of these platforms. However, current academic benchmarks provide limited guidance for real-world industry scenarios. This limitation arises because educational applications require more than mere test question responses. To bridge this gap, we introduce CJEval, a benchmark based on Chinese Junior High School Exam Evaluations. CJEval consists of 26,136 samples across four application-level educational tasks covering ten subjects. These samples include not only questions and answers but also detailed annotations such as question types, difficulty levels, knowledge concepts, and answer explanations. By utilizing this benchmark, we assessed LLMs' potential applications and conducted a comprehensive analysis of their performance by fine-tuning on various educational tasks. Extensive experiments and discussions have highlighted the opportunities and challenges of applying LLMs in the field of education.
SNFinLLM: Systematic and Nuanced Financial Domain Adaptation of Chinese Large Language Models
Aug 05, 2024Large language models (LLMs) have become powerful tools for advancing natural language processing applications in the financial industry. However, existing financial LLMs often face challenges such as hallucinations or superficial parameter training, resulting in suboptimal performance, particularly in financial computing and machine reading comprehension (MRC). To address these issues, we propose a novel large language model specifically designed for the Chinese financial domain, named SNFinLLM. SNFinLLM excels in domain-specific tasks such as answering questions, summarizing financial research reports, analyzing sentiment, and executing financial calculations. We then perform the supervised fine-tuning (SFT) to enhance the model's proficiency across various financial domains. Specifically, we gather extensive financial data and create a high-quality instruction dataset composed of news articles, professional papers, and research reports of finance domain. Utilizing both domain-specific and general datasets, we proceed with continuous pre-training on an established open-source base model, resulting in SNFinLLM-base. Following this, we engage in supervised fine-tuning (SFT) to bolster the model's capability across multiple financial tasks. Crucially, we employ a straightforward Direct Preference Optimization (DPO) method to better align the model with human preferences. Extensive experiments conducted on finance benchmarks and our evaluation dataset demonstrate that SNFinLLM markedly outperforms other state-of-the-art financial language models. For more details, check out our demo video here: https://www.youtube.com/watch?v=GYT-65HZwus.
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
Dec 26, 2023



Recent advancements in Text-to-SQL methods employing Large Language Models (LLMs) have demonstrated remarkable performance. Nonetheless, these approaches continue to encounter difficulties when handling extensive databases, intricate user queries, and erroneous SQL results. To tackle these challenges, we present \textsc{MAC-SQL}, a novel LLM-based multi-agent collaborative framework designed for the Text-to-SQL task. Our framework comprises three agents: the \textit{Selector}, accountable for condensing voluminous databases and preserving relevant table schemas for user questions; the \textit{Decomposer}, which disassembles complex user questions into more straightforward sub-problems and resolves them progressively; and the \textit{Refiner}, tasked with validating and refining defective SQL queries. We perform comprehensive experiments on two Text-to-SQL datasets, BIRD and Spider, achieving a state-of-the-art execution accuracy of 59.59\% on the BIRD test set. Moreover, we have open-sourced an instruction fine-tuning model, SQL-Llama, based on Code Llama 7B, in addition to an agent instruction dataset derived from training data based on BIRD and Spider. The SQL-Llama model has demonstrated encouraging results on the development sets of both BIRD and Spider. However, when compared to GPT-4, there remains a notable potential for enhancement. Our code and data are publicly available at https://github.com/wbbeyourself/MAC-SQL.
QURG: Question Rewriting Guided Context-Dependent Text-to-SQL Semantic Parsing
May 16, 2023Context-dependent Text-to-SQL aims to translate multi-turn natural language questions into SQL queries. Despite various methods have exploited context-dependence information implicitly for contextual SQL parsing, there are few attempts to explicitly address the dependencies between current question and question context. This paper presents QURG, a novel Question Rewriting Guided approach to help the models achieve adequate contextual understanding. Specifically, we first train a question rewriting model to complete the current question based on question context, and convert them into a rewriting edit matrix. We further design a two-stream matrix encoder to jointly model the rewriting relations between question and context, and the schema linking relations between natural language and structured schema. Experimental results show that QURG significantly improves the performances on two large-scale context-dependent datasets SParC and CoSQL, especially for hard and long-turn questions.
CQR-SQL: Conversational Question Reformulation Enhanced Context-Dependent Text-to-SQL Parsers
May 17, 2022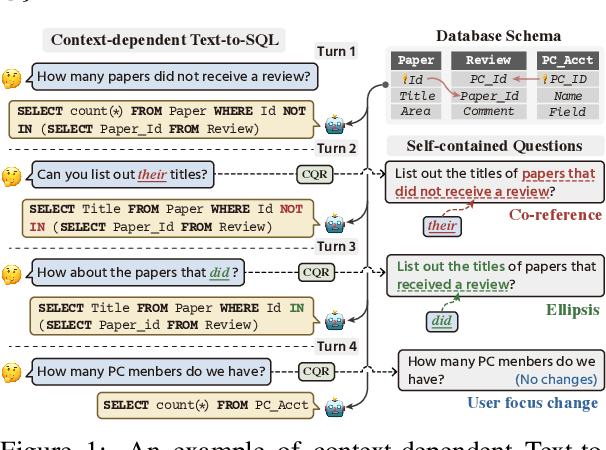

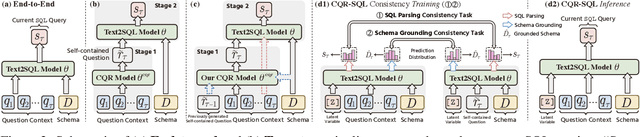
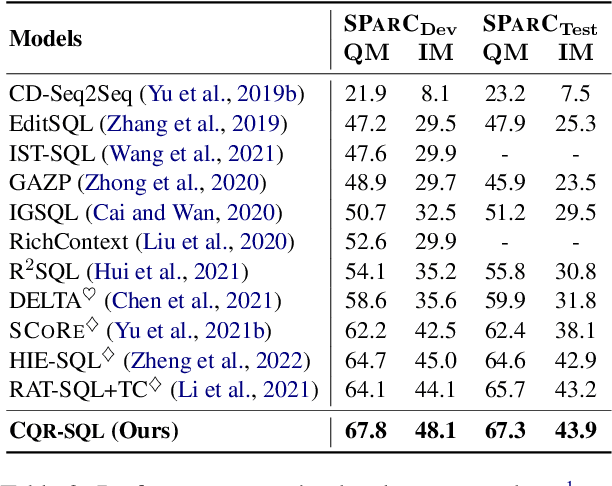
Context-dependent text-to-SQL is the task of translating multi-turn questions into database-related SQL queries. Existing methods typically focus on making full use of history context or previously predicted SQL for currently SQL parsing, while neglecting to explicitly comprehend the schema and conversational dependency, such as co-reference, ellipsis and user focus change. In this paper, we propose CQR-SQL, which uses auxiliary Conversational Question Reformulation (CQR) learning to explicitly exploit schema and decouple contextual dependency for SQL parsing. Specifically, we first present a schema enhanced recursive CQR method to produce domain-relevant self-contained questions. Secondly, we train CQR-SQL models to map the semantics of multi-turn questions and auxiliary self-contained questions into the same latent space through schema grounding consistency task and tree-structured SQL parsing consistency task, which enhances the abilities of SQL parsing by adequately contextual understanding. At the time of writing, our CQR-SQL achieves new state-of-the-art results on two context-dependent text-to-SQL benchmarks SParC and CoSQL.
Enhancing Label Correlation Feedback in Multi-Label Text Classification via Multi-Task Learning
Jun 06, 2021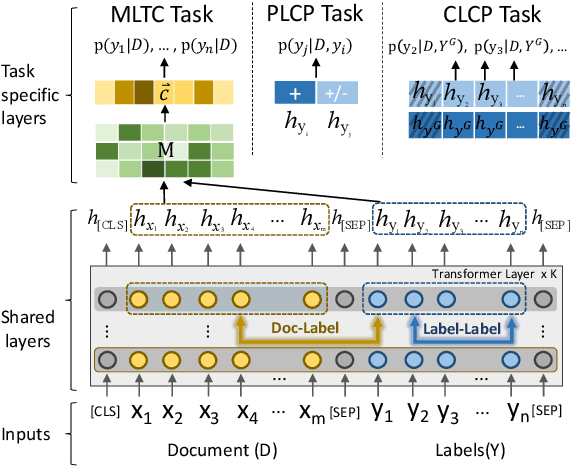
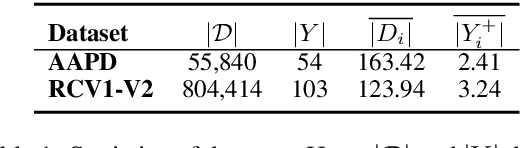
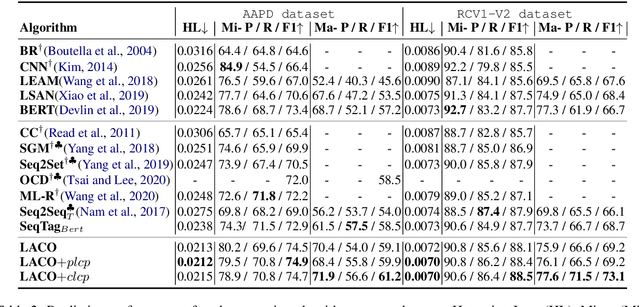
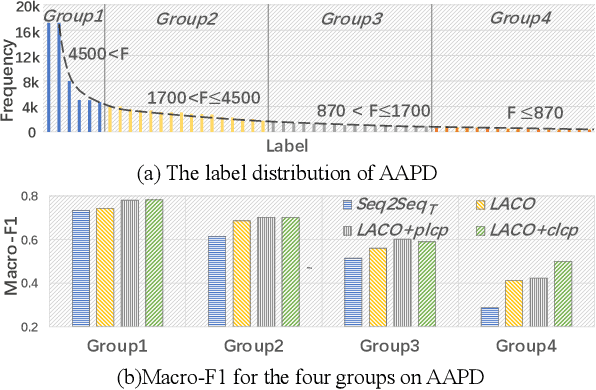
In multi-label text classification (MLTC), each given document is associated with a set of correlated labels. To capture label correlations, previous classifier-chain and sequence-to-sequence models transform MLTC to a sequence prediction task. However, they tend to suffer from label order dependency, label combination over-fitting and error propagation problems. To address these problems, we introduce a novel approach with multi-task learning to enhance label correlation feedback. We first utilize a joint embedding (JE) mechanism to obtain the text and label representation simultaneously. In MLTC task, a document-label cross attention (CA) mechanism is adopted to generate a more discriminative document representation. Furthermore, we propose two auxiliary label co-occurrence prediction tasks to enhance label correlation learning: 1) Pairwise Label Co-occurrence Prediction (PLCP), and 2) Conditional Label Co-occurrence Prediction (CLCP). Experimental results on AAPD and RCV1-V2 datasets show that our method outperforms competitive baselines by a large margin. We analyze low-frequency label performance, label dependency, label combination diversity and coverage speed to show the effectiveness of our proposed method on label correlation learning.